
[Hyperscale Infrastructure] AI 시대, 성공적인 멀티 클라우드 구축과 스마트팩토리 자동화 방안
1 min read
‘Hyperscale Infrastructure’을 주제로 한 시스코 커넥트 코리아 2023 트랙 C에서는 클라우드 구축, 투자 효율적 AI 구축 방안, 스마트팩토리 네트워크 자동화 방안 등 가장 핫한 최신 IT 트렌드와 시스코의 솔루션을 소개합니다.
기업의 디지털 전환이 가속화되는 가운데 고가용 아키텍처에 의한 비즈니스 연속성에 대한 니즈도 확대되고 있습니다. 다양한 클라우드 인프라를 어떻게 효율적으로 연결하여 운영할 수 있는지, AI 시대를 맞아 IT 인프라가 AI를 어떤 식으로 지원해야 하는지, 점점 복잡해지는 IT 인프라를 문제 없이 잘 관리하기 위해 어떤 서비스가 필요한지 이번 블로그에서 확인해 보세요!
기업의 멀티 클라우드 네트워킹 준비하기
시스코코리아 하정환 프로, 이요한 이사

클라우드 네트워킹 구축 방법론에 대해 소개하고 있는 시스코코리아 이요한 이사(좌)와 하정환 프로(우)

- 클라우드 송환 : 퍼블릭 클라우드 전환한 애플리케이션 및 워크로드를 갔다가 다시 온프레미스 또는 프라이빗 클라우드로 다시 돌려보내는 것, 송환 이유로 예상치 못한 비용, 운영 복잡성, 보안 3가지가 대표적인 요인으로 꼽힘
- 비용 : 클라우드 전환 시 예상치 못한 많은 비용이 발생하고 지출이 증가함, 그만큼 클라우드에서의 비용 관리가 어렵다는 것을 의미하며 이 때문에 FinOps가 새롭게 주목받고 있음
- 운영 복잡성 : 클라우드로 전환한 많은 기업들이 인프라 운영의 복잡성 및 엔드투엔드 가시성 확보에 문제가 있음을 호고 -> 문제가 어디서 발생했고 어떻게 해결해야 하는지 어려움을 느낌
- 보안 : 보안을 위해 멀티 클라우드 선택했으나 분산된 인프라에서 운영되는 다수의 워크로드를 안전하게 보호하고 운영할 수 있는 노하우가 부족
- 여기에 연결성, 운영 복잡성, 지속가능성도 고려해야 함
- 이러한 사항을 해결할 수 있는 것이 클라우드 네트워킹 운영 + AIOps를 통한 간편한 관리 + 환경적 영향을 최소화시킬 수 있는 데이터 센터를 표방하는 ESG 경영임
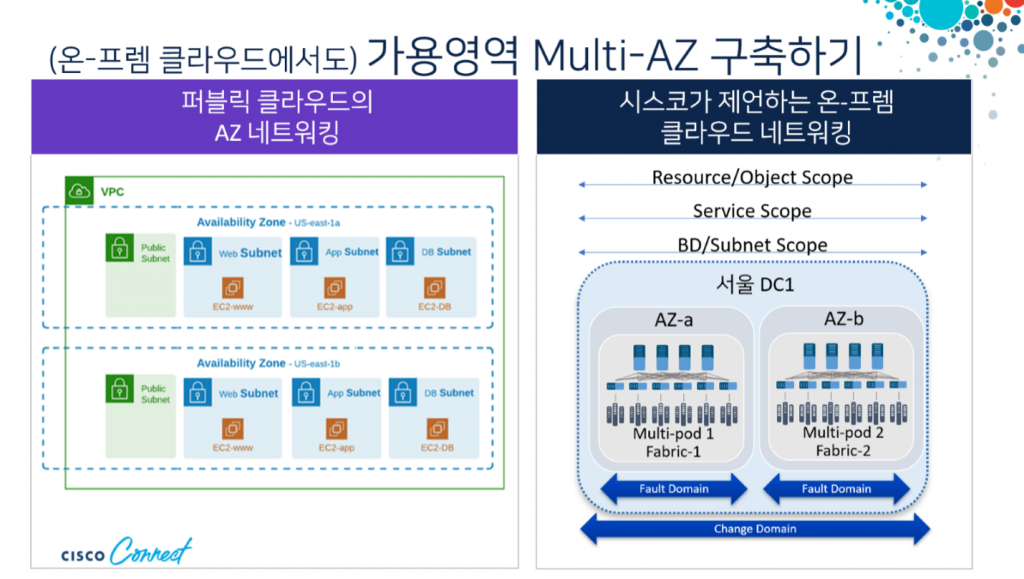
- 온프레미스에서도 멀티 AZ, 멀티 리전 구축 가능 : Cisco SDN을 사용해 패브릭 2중화로 데이터 센터 가용성 확보 혹은 프론트 엔드 & 백엔드 분리, 망분리 구축 가능, 서울DC와 대전DC로 나눠서 운영 가능(금융사 및 공공기관 레퍼런스 확보)
- 퍼블릭 멀티 클라우드와 온프레미스의 네트워크를 연결해서 Cisco Nexus 단일 대시보드에서 GUI로 관리
- 템플릿을 사용해 자동화된 네트워크 배포 및 운영 가능, 고객이 자사의 서비스를 빠르게 배포하고 운영할 수 있게 하기 위함
- 온프레미스에서도 퍼블릭 클라우드처럼 고가용성 네트워킹이 가능하며 이 둘을 원활하게 연계할 수 있다는 것이 핵심
- 하이브리드 클라우드 네트워크에서 시급한 문제는 빠른 장애 해결과 엔드 투 엔트 가시성 확보임
- 이 2가지를 해결할 수 있는 것이 AIOps : 사전 대응이 가능, 이상징후 알람이 발생했을 때 무엇이 문제이며 징후는 어떻게 발생했고 영향은 어느 정도이며 어떻게 고쳐야 하는지 정보를 알 수 있고 원-클릭 교정 지원
초거대 AI 시대, 네트워크 아키텍처 새판짜기
시스코코리아 최수영 상무, 임규현 프로

초거대 AI를 위한 네트워크 아키텍처와 구축 사례에 대해 소개하고 있는 시스코코리아 최수영 상무(우)와 임규현 프로(좌)

- AI 마켓 트렌드 : 다양한 생성형 AI 활용률 증가, 2028년까지 연평균 7% 성장 예상, 기술의 발전과 함께 AI 모델 수요 증가, 국내 시장 역시 매년 17% 상승 예상되며 AI 투자금 30%는 하드웨어 인프라에 투자 중
- AI 인프라 구조 : 분산 병렬 처리 때문에 GPU가 핵심, GPU 수량을 늘려 학습 시간을 줄여야 함, NVIDIA V100, A100, H100이 널리 활용되고 있음, H100에 이르러서는 네트워크 대역폭 400Gbps 이상 네트워크 필요
- GPU 서버의 네트워크 연결 : 과거 CPU 중심의 네트워크는 서버당 10G, 25G로 충분했으나 현재의 NVDIIA GPU 칩 하나가 필요로 하는 네트워크 대역폭이 400Gbps임
- 게다가 하나의 서버에 GPU 8개가 장착될 경우 이 GPU들간의 통신에도 400Gbps 이상의 네트워크 대역폭을 연결할 수 있는 NIC 필요, 이 GPU가 다른 서버 및 스토리지와 연결되어 제 성능을 발휘하기 위해서도 마찬가지로 400Gbps 이상의 네트워크 대역폭 및 NIC가 필요
- AI 인프라에서는 최소 400G 이상의 고대역폭 네트워크가 필요하다는 의미

- AI 트래픽 패턴 : GPU 연산 트래픽의 경우 GPU 클러스터 내에서 최초로 연산 명령을 내리면 다수의 GPU에서 동시에 연산 명령을 실행함, 이후 연산이 완료되면 결과를 다시 클러스터 내 모든 GPU에 전달하며, 아직 연산이 완료되지 않은 GPU는 계속 연산 수행, 모든 GPU 연산이 완료될 때까지 먼저 연산이 완료된 GPU는 기다려야 하는 상황, 이만큼 처리 지연 시간, 병목이 생기는 것 ->이것을 해결하기 위해 다양한 기술 사용
- Grace CPU : GPU와 CPU를 직접 연결하여 GPU 내 메모리가 모자랄 경우 CPU Host의 메모리를 가져다 사용함
- GPUDirect P2P : 1개 이상의 다수의 GPU에서 트래픽을 처리할 때 CPU를 거치지 않고 직접 GPU끼리 P2P로 직결해서 GPU 간의 병목 현상 해결
- GPUDirect RDMA : GPU와 GPU 노드 간에는 GPUDirect RDMA를 통해 NIC에서 호스트 메모리를 통과하지 않고 바로 GPU 메모리를 읽을 수 있게 노드 간의 GPU를 또 직결함
- GPUDirect Storage : 스토리지 연결 역시 마찬가지로 GPU와 Storage를 직결해서 병목 해결
- 핵심은 기존 구조에서 CPU와 Host 메모리를 한번 거쳐가야 하는 구조를 생략하고 필요한 GPU와 GPU 상호 간 직결 + GPU 자원을 사용해야 하는 시스템을 GPU와 직결해서 해결하는 것
- CPU를 경유하지 않고 병목 없이 통신하게 하자는 것이 RDMA이며, 이 RDMA 통신을 이더넷으로 가능케 하는 것이 RoCEv2(RDMA Over Converged Ethernet) -> Lossless Network
- ECN(Explicit Congestion Notification) 프로토콜, PFC(Priority-based Flow Control, Switch to Switch) 프로토콜 활용
- 네트워크 장비들 간의 흐름 제어뿐만이 아닌 네트워크와 연결된 GPU, Storage 등 모든 자원을 아우르는 네트워크 흐름 제어가 필요한 것이 AI 인프라의 네트워크 특징임

- Non-Blocking Fabric 디자인 : 다운링크와 업링크 속도를 1:1로 동일하게 맞춤으로써 병목 현상을 제거, 이것을 지원할 수 있는 장비가 Cisco Nexus 9000 Series
- Cisco NDFC : 목적에 맞는 네트워크 패브릭 디자인 + AI 네트워크를 위한 표준 설정을 배포 자동화 -> AI 네트워크에서는 각 장비 하나하나가 전체 성능에 끼치는 영향이 지대하기 때문에 무중단 OS 업그레이드 지원, 네트워크에서 발생하는 플로우 성능 모니터링을 위해 텔레메트리 서비스 제공
- Cisco ND-Insights, AI 트래픽 플로우별로 어떤 이슈가 있고, 이 이슈로 인해 다른 트래픽 구간에 얼마나 영향을 끼치고 있으며, 향후 어떤 트렌드를 보일 것인지 예측할 수 있는, 기존에 모니터링하지 않았던 새로운 요소를 모니터링할 수 있다는 것이 핵심
전환기의 IT 인프라, 어떻게 운영해야 하나?
시스코코리아 윤희진 프로

전환기의 IT 인프라에 대해 소개하고 있는 시스코코리아 윤희진 프로
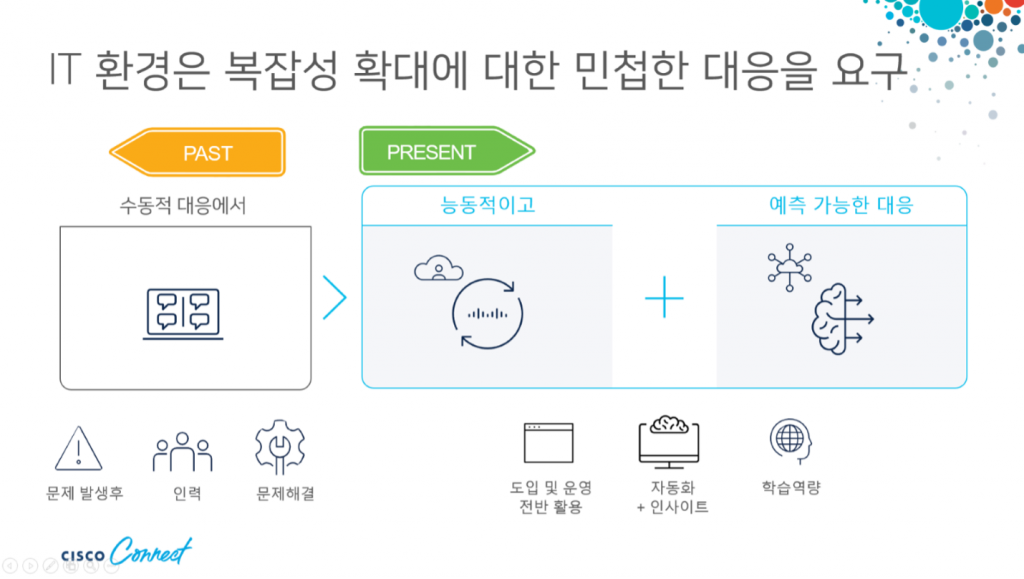
- 기술지원 서비스의 진화 : 1세대 하드웨어 장비 이슈 해결 -> 2세대 연계된 이기종 제품 이슈 해결(현상은 장비에서 발견되나 해결은 그 장비 외에 연계된 다른 장비까지 확인 필요) -> 3세대 복잡한 문제를 더 빠르게 해결할 수 있기 위해 AI 기능 활용
- 현재의 복잡한 IT 환경을 제대로 지원하기 위해서는 현실적으로 ‘매우’ 복잡한 디지털 트랜스포메이션을 기술지원해야 함
- 레거시 시스템의 현대화에 클라우드 모델까지 합쳐지고 사용자 및 시스템 데이터까지 연계되면서 매우 복잡한 환경이 되었기 때문
- 이런 환경에서 고객은 빠른 대응을 요구 : 따라서 문제가 발생하면 대응하는 수동적 대응에서 자동화 기술을 통해 분석 후 선제적 대응을 할 수 있는 능력을 키워 나가야 함 -> IT 운영 환경 고도화가 필요
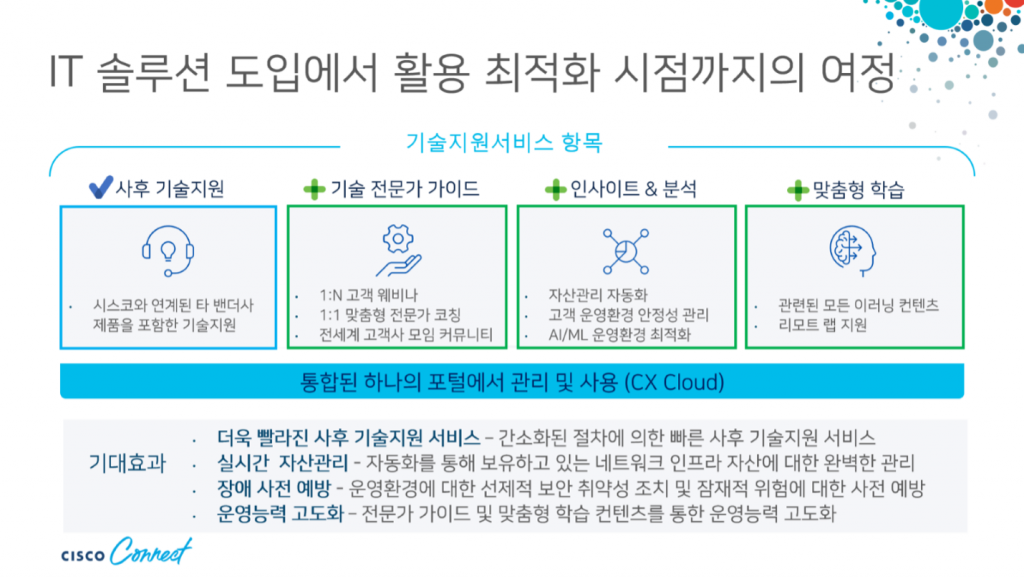
- 시스코는 Cisco CX Cloud를 사용해 IT 솔루션 도입에서 활용 최적화 시점까지의 여정 모두를 체계적으로 관리
- 기술지원에 필요한 절차 간소화 + 고객 맞춤 기술 전문가 가이드 + AI/ML을 활용한 인사이트 & 분석 + 고객의 사용 환경에 맞는 필요한 학슴 콘텐츠 제공으로 운영 능력 고도화 제고
- 각 항목별 기술지원 서비스를 하나의 단일 화면에서 관리하고 기술지원을 받을 수 있다는 것이 핵심

- 자산 관리 사례 : 1,200개의 시스코 장비 운영 중, 오래된 장비를 파악하고 향후 어떻게 교체해 나갈 것인지 계획 수립 필요 -> 6~12개월 안에 EOS가 예고되어있는, 교체가 필요한 장비를 CX Cloud에서 빠르게 확인, 드릴 다운으로 해당 장비에 대한 상세 정보 확인 가능(제품 하드웨어 및 소프트웨어 정보 + 기술지원 정보)
- 보안 조치 사례 : 운영 장비 중 심각한 보안 취약점에 노출되어 해당 자산이 무엇인지 파악해야 하고 잠재적인 위협에 노출된 장비까지 한 번에 파악해야 함 -> 필터에서 긴급한 조치가 요하는 항목을 선택해 해당 상황에 적용된 장비들을 리스트업 -> 장비의 상세 내역을 드릴 다운으로 확인하고 기술지원 케이스를 열어 빠르게 조치 가능
- 장애에 대한 선제적 예방 사례 : 운영 중 장애가 발생하기 전에 예방할 수 있어야 함 -> 장애 발생 위험도를 중간, 심각 등 단계별로 나누어 일목요연하게 볼 수 있음 -> 마찬가지로 해당 장비를 클릭하여 세부 내역을 확인 -> 관리자가 주기적으로 잘 관리하고 있다면 위험도가 낮게 평가됨 -> 이어서 현재의 상태에 따라 시스코에서 제안하는 조치가 무엇인지 확인 후 조치할 수 있음
- 운영 환경에 맞는 안정적인 OS 버전 권고 : 소프트웨어 탭을 클릭해 운영 버전이 낮아 운영에 심각한 장애를 초래할 수 있는 장비들을 리스트업 -> 현재 장비의 소프트웨어 버전 상태에 따라 AI가 그 소프트웨어가 가진 버그를 분석해 관리자에게 어떤 소프트웨어로 업그레이드하면 좋다는 것을 권고 -> 이때 단순히 최신 버전만을 권고하는 것이 아닌 기존에 알려진 버그 및 보안 취약점이 해결된 버전을 추천
IT/OT 컨버전스 아키텍처를 통한 스마트팩토리의 진화
시스코코리아 이정표 프로

스마트팩토리의 진화와 시스코 솔루션에 대해 설명하고 있는 시스코코리아 이정표 프로

- 왜 IT/OT 컨버전스가 필요한가 : OT는 공장에서 운영되는 기기를 다루는 기술, IT에서 바라보는 OT는 이런 기기 자체가 아닌 기기에서 수집되는 데이터를 어떻게 관리하고 사용할 것인가에 대한 관점임 -> 데이터 처리장치는 빠르게 통합되고 있음, 공장에서 운영되는 다수의 서버와 로봇을 다루는 장치들을 통합해서 가상화된 통합 운영 환경으로 진화 중 -> OT의 IT화(아우디 제조공장 사례)
- 공장의 수만 개 이상에서 운영하는 이기종 기계 컨트롤러에 대한 관리를 하기 위해서는 가상화 + 단순하고 일관된 관리 방안이 필요
- 따라서 IT와 OT의 연결, 융합은 Simple해야 함, 현재 매우 높아진 OT의 복잡성을 IT 기술을 활용함으로써 상당부분 해결할 수 있음 -> 독자적인 사양의 기기 및 이기종 기기들에 대한 관리 복잡성을 해결하기 위해 이 기기들에서 수집되는 데이터를 표준화하고 분석해서 활용하며, 이 과정에서 보안이 고려되는, 안전한 아키텍처로 전환될 것

- IT/OT 컨버전스란 무엇인가 : 신공장에 적용하기 쉬움, 기존 공장에는 변화가 어렵기 때문, 공정 및 생산 라인에서 사용되는 고유한 설비/장치/센서들이 개별적인 환경에서 격리되어 Silo 환경에서 운영되고 있음
- 따라서 어떻게 이 기기들에서 수집되는 데이터를 통합하고 분석함으로써 기기들을 통합 관리할 수 있으며, 보안을 강화할 수 있는지 고민 필요
- 결국 각 기기들의 예지정비와 같은 효율적인 운영이 가능하려면 기기로부터 수집한 데이터를 IT에서 분석하고, 그 결과를 다시 OT로 내려주어야 함, 그런데 기존의 OT망은 100mbps라서 데이터 전달이 어려움 -> 10G 네트워크망 필요하나 기존에 많은 설비들이 운영되고 있는 공장의 네트워크 망을 전환하는 것은 쉽지 않음, 그래서 기존 공장에 IT/OT 컨버전스를 구현하기 어려운 것 -> 따라서 아예 처음 공장을 설계할 때부터 IT/OT 컨버지드 아키텍처를 적용해 10G 망으로 구성할 필요가 있음
- 이러한 IT/OT 컨버전스 환경이 갖추어지면 IT/OT 인프라가 통합 운영됨, 이 위에 기존에 IT 환경에서 사용되던 고도의 모니터링 및 분석 솔루션을 적용해 OT망의 설비들 사이에서 흘러 다니는 트래픽을 심도있게 분석하여 보안을 강화시킬 수 있음

- IT/OT 컨버전스 구현을 위한 역량 : 레퍼런스 아키텍처를 통한 검증된 설계 도입 -> CVD(Cisco Validated Design), 시스코의 오랜 학습을 통해 사전 검증된 표준화된 모델로 설계를 간소화하고 소프트웨어 기반 관리로 OT 인프라로 전환할 수 있어야 함
- 기존의 제조 레거시 인프라 : 이미 서로 다른 설비와 기기들로 갖추어진 환경들을 통합 관리하는 것은 매우 어려움
- To-Be 제조 IT/OT 컨버지드 인프라 : OT 백본망을 가상화하여 기존에 IT에서 활용되던 다양한 인프라 운영 관리 기술을 적용해 좀 더 효율적인 관리 + 보안적으로 안전한 운영이 가능해짐
- 통합 보안 아키텍처 : 기존에는 장비에 문제가 생기면 일단 생산성 문제 해결에 급급하여 사용자 인증 없이 빠르게 장애 해결 시도, 하지만 이렇게 사용자 인증 없이 조치하면 장애가 해결됐더라도 어떤 작업을 진행했고 누가 작업을 했는지에 대한 기록을 남기기 어려워 보안상 큰 문제가 될 수 있음 -> 하지만 통합 보안 아키텍처에서는 로컬에서 직접 문제를 해결하든 원격으로 문제를 해결하든 모든 기록을 남길 수 있고, 사전에 인가된 사용자가 접근하여 안전하게 장애를 해결할 수 있음
- 나아가 네트워크 세그멘테이션을 통해 특정 장비가 악성코드에 감염되더라도 이 장비에서 발생한 보안 사고가 다른 장비로 전파되는 것을 방지할 수 있음 -> 차세대 방화벽뿐만 아니라 장비들이 연결된 네트워크 로직 자체를 보안 아키텍처 기반으로 설계해야 함, 그래야 데이터를 서로 주고받아도 되는 장비들과 데이터 통신이 되면 안 되는 장비들을 설정해서 관리할 수 있음 -> 이것이 안전한 OT 환경의 시작임
- 시스코만이 유일한 IT인프라와 OT인프라를 통합 제공할 수 있는 제조사, IT에서 사용하는 기술을 OT에서도 사용할 수 있어야 하며, 이에 대한 기반 기술을 폭넓게 보유하고 있음
- IT와 OT 조직의 협업이 매우 중요, IT조직과 OT조직이 긴밀하게 협업해야 IT/OT 통합 레퍼런스 아키텍처 기반의 IT/OT 컨버전스를 구현할 수 있음
여기까지 Cisco Connect Korea 2023의 트랙 C 세션 내용들을 간략하게 소개드렸습니다. 해당 세션 다시 보기 영상 및 발표자료 다운로드는 시스코 커넥트 코리아 2023 이벤트 페이지에서 확인 가능합니다.

잠깐! 세션 내용 중 궁금한 사항이나 상담 신청이 필요하신가요? 하단 배너를 통해 상담 요청 남겨주시면 시스코가 전문가가 바로 연락드리도록 하겠습니다. 감사합니다.

* 시스코 커넥트 코리아 2023 행사 리뷰 보기
트랙 A : [Secure Networking] 최신 보안 트렌드와 전략 인사이트
트랙 B : [Future Enterprise] 시스코가 바라보는 미래의 IT는?
트랙 C : [Hyperscale Infrastructure] AI 시대, 성공적인 멀티 클라우드 구축과 스마트팩토리 자동화 방안
Authors
1 댓글
안녕하세요
제가 IT에 대해 깊이 알지못하고 있어서 궁금했던차에 여러세미나를 바쁜 시간을 내어서 참석했으나 모든곳의 발표자는 전문가로서 열성이나 본인은 이해가 어렵고 혼란스러웠습니다.
모두다 좋은것 같고 그런데 시스코 세미나 C트랙에서 이해와 더블어서
이런 시스템이 옳지 않은가해서 다시 알아보려고 여러경로로 문의을 해도 아프리카 에서 사자 잡기보다 어렵웠습니다.
그러는중에 스마트폰으로 당시 트랙별 자료가 온것같은데 화면이 작아서
다시보기가 좀 그랬는데 어찌 된 사연있지 그날 전반의 자료가 왔습니다.
AI가 한것인지 하늘에서 한것인지는 모르겠으나 주말에 다시 차분하게 보려고 합니다.
우리 프로젝트가 특별하고 신설하는 과정이고 재무 인력 전세계 지사와 테마파크 회원 입퇴 관리 영상자료 관리 스마트폰과 연계 기타 전반을 IT. AI 시스템으로 하려고 생각하니 클라우드도 고민이고 비용등 자산관리등 그렇습니다.
더위에 건강하시고 모두 행복하세요
자본주의 세계는 과학기술시스템으로 인류의 존엄과 근본성을 깨트리거 있습니다
우리는 인류의 가치를 이루고 높이는 인류사회에서 특별한 프로젝트을 펼쳐가는 것입니다.