
この記事は、Cisco AppDynamics のセールス イネーブルメント エンジニア Jeff Holmes によるブログ「Scaling Kubernetes with Observability and Confidence」
(2020/11/25)の抄訳です。
Kubernetes を利用するとマイクロサービス アプリケーションを簡単に導入できます。本ブログ記事では、AppDynamics を利用してマイクロサービス アプリケーションの正常性を大規模に確保する方法をいくつかご紹介しています。
Kubernetes は急速に進化しており、KubeCon + CloudNativeCon 2020 に参加したすべての人がそのことを今まで以上に実感したはずです。このイベントでは優れたコンテンツとイノベーションが数多く紹介されました。特に、Microsoft 社の Project Tye や、Kubernetes 上でサーバレスコンテナを実行できる Knative など、開発者のエクスペリエンスの簡素化に重点が置かれているのが印象的でした。
本ブログ記事では、私がイベントで学んだことと、Kubernetes のオブザーバビリティ(可観測性)の大幅な向上に AppDynamics を役立てる方法をご紹介します。特に、大規模な導入環境をプロアクティブにモニタリングし、アプリケーションとクラスタのオブザーバビリティを最大限かつ最短で実現できる新旧のいくつかの機能に焦点を当てています。
以前のブログ記事「AppDynamics を使用して実稼働環境の Kubernetes クラスタをモニタリングする際のベストプラクティス」と同様に、このブログ記事は Kubernetes に関する高度な知識をお持ちの方を対象としています。
課題 1:オブザーバビリティを大規模に実現する
Kubernetes を利用するとマイクロサービス アプリケーションを簡単に導入できます。AppDynamics などのアプリケーション パフォーマンス モニタリング(APM)ツールはマイクロサービス アプリケーションを正常に運用するために不可欠であることがすでに実証されており、OOTB トレース機能、コードレベルの診断、ベースライン設定などがそうした目的に役立ちます。
しかし、あらゆるマイクロサービス導入環境(複数の Kubernetes 導入環境、名前空間、クラスタなど)にわたって APM の力を大規模に発揮することはますます困難になっています。また、APM 機能を追加するためにアプリケーションチームがコードやイメージを手動で変更しなければならない場合は、重大な問題が発生する可能性があります。Kubernetes の init コンテナを使用すると、APM エージェントを導入時にインストールできるため、各アプリケーションイメージを手動で変更する必要がなくなります。しかし、大規模な組織の場合、アプリケーションごとに Kubernetes 導入環境の仕様を変更するのはやはり大きな課題となる可能性があります。
AppDynamics クラスタエージェントは、「自動インストゥルメンテーション」を通じてこの問題を解決します。この機能は、Kubernetes API を利用することで、アプリケーションイメージを変更することなく、(init コンテナを使用して)Kubernetes アプリケーションに APM エージェントを動的かつ自動的に追加します。
これにより、Day 1 と Day 2 のユースケースが大幅に簡素化されます。つまり、APM インストゥルメンテーションの導入と、新しい APM エージェントが利用可能になった場合のアップグレードの管理が簡素化されます。Java アプリケーションの自動インストゥルメンテーションを有効にするために必要なクラスタエージェントの設定は次のとおりです。
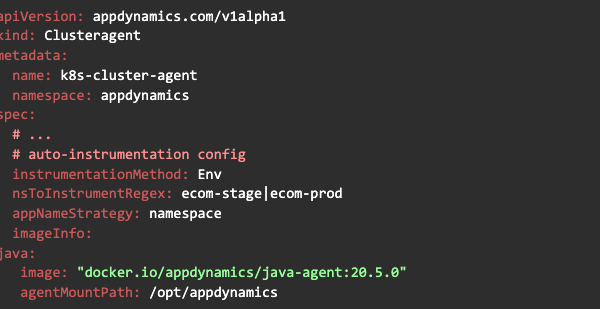
まず nsToInstrumentRegex プロパティを設定して、自動インストゥルメンテーションの対象とする名前空間を指定します。次に java.image プロパティを設定して、エージェントビットのコピーに使用する Java APM エージェントのイメージを指定します。後はこの設定を適用するだけで自動インストゥルメンテーションが有効になります。クラスタエージェントは指定された名前空間のアプリケーションを更新し、Kubernetes はローリングアップデートを実行してアプリケーションを再起動します。エージェントのアップデートは、java.image プロパティを更新してクラスタエージェントを再適用するだけで行えます。これはアプリケーションごとにアップデートを行うよりもはるかに簡単です。
すでに Java、NET Core、Node.js アプリケーションの自動インストゥルメンテーションがサポートされていますが、今後もさまざまな言語がサポートされる予定です。
課題 2:アプリケーション(およびポッド)がクラッシュする問題の根本原因を特定する
2 つ目の課題は、Kubernetes アプリケーションが正常に稼働せず、繰り返し再起動する場合の原因を特定することです。これは非常に難しい課題です。アプリケーションの稼働時間が短かすぎて問題をトレースできなかったり、大規模な導入環境のオペレータには根本原因を見つけるためにログを確認したりさまざまなツールで調査を行う時間的余裕がなかったりする場合が多いからです。
クラスタエージェントには、障害が発生したアプリケーションに関連するログイベントを自動的にキャプチャする新機能が追加されています。クラスタエージェントは APM の相関関係分析(APM エージェントが提供する追加のパースペクティブ(トレースやコードレベルの診断など)にポッド/コンテナを関連付ける機能)をサポートしていますが、この新機能は APM に依存しません。代わりに、クラスタエージェントは Kubernetes API を活用して、クラッシュと再起動を繰り返している異常なアプリケーションを認識し、関連するログを自動収集します。
以下にクラスタエージェントのポッドダッシュボードの例を示します。このダッシュボードには、再起動が発生した devops-offers-profile-service-v2 導入環境のポッドが表示されています。
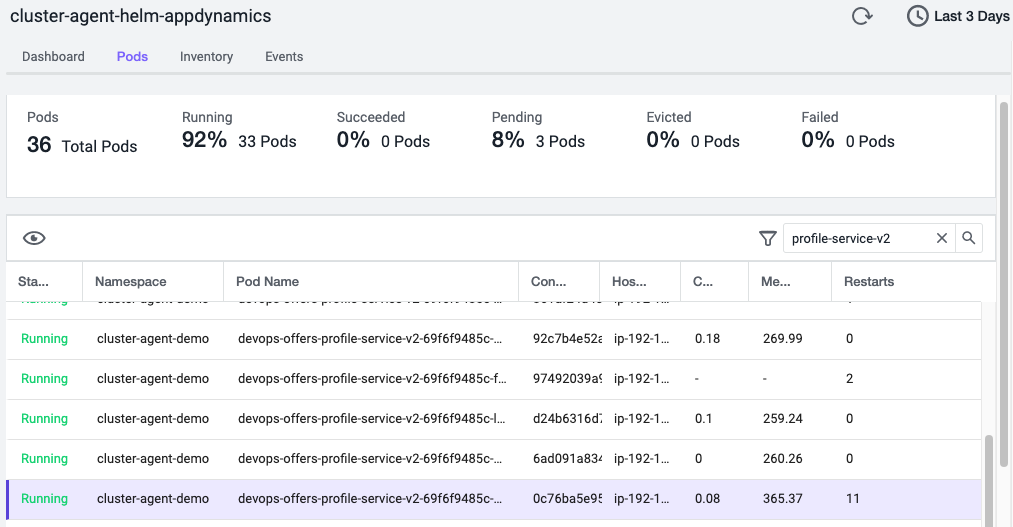
再起動が 11 回発生しているポッドをドリルダウンすると、ポッドの詳細ビューが現れ、[エラーログ(Error Log)] セクションが新たに表示されます。
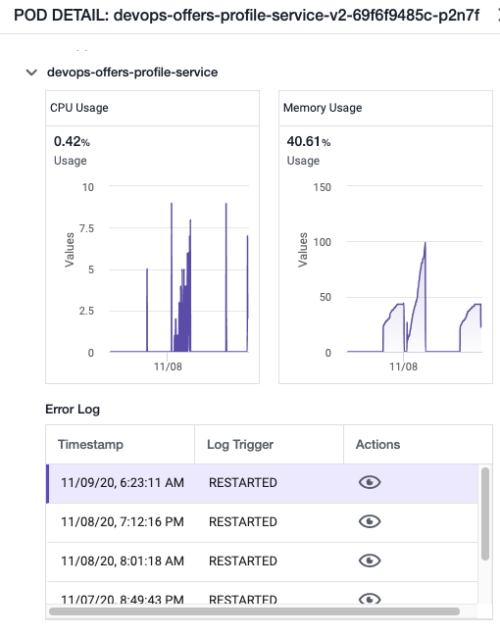
[アクション(Actions)] をドリルダウンすると、一連の再起動イベントで収集されたログが表示され、再起動の根本原因がメモリの問題であることがわかります。
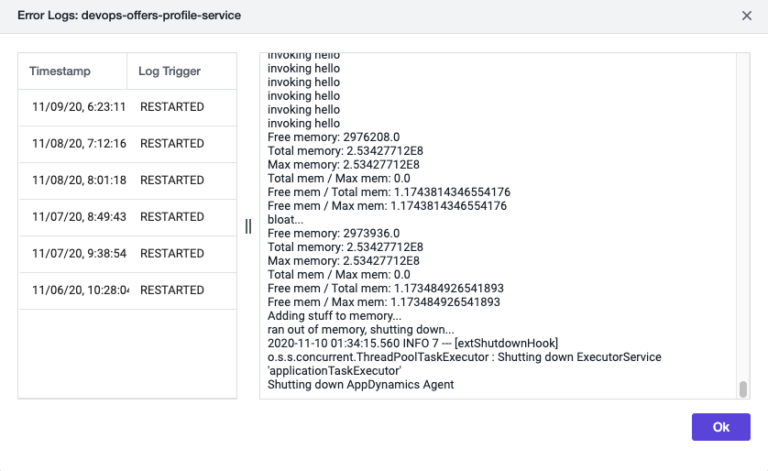
自動ログキャプチャは、再起動が発生しているポッドだけでなく、CrashLoopBack イベントが発生しているポッドに対しても機能します。詳細については、ポッドログの管理に関するドキュメントを参照してください。
課題 3:クラスタ情報(またはプロアクティブなクラスタ正常性アラート)が多すぎる
大規模な導入環境のオペレータに共通する別の課題として、基本情報が多すぎることが挙げられます。AppDynamics クラスタエージェントのダッシュボードには各クラスタの正常性を可視化するためのオプションがいくつかあります。ただし、クラスタの数が数百とまでは言わないまでも数十以上ある場合は、注意が必要なイベントを検出するプロアクティブなアラートが必要になります。これを実現する方法の一例として、AppDynamics クラスタエージェントと主なクラスタメトリックの OOTB ベースライン設定を使用する方法を簡単に見てみましょう。
追跡する必要がある一般的なクラスタ KPI の 1 つに、アプリケーションの追加導入や既存アプリケーションのスケールアウトに使用できるクラスタの空き容量があります。Kubernetes には、名前空間内のアプリケーションに対して使用可能な CPU、メモリ、ストレージ容量の合計を制限するクォータメカニズムと、アプリケーションごとに使用可能なリソース(要求と上限)を制限する機能があります。
ここではメモリ容量を例に取ってみましょう。使用可能なメモリ容量は、使用済み容量(名前空間に導入されているアプリケーションの合計メモリ要求/上限)と名前空間で使用可能な CPU 容量(名前空間クォータで設定)の比率として追跡できます。クラスタエージェントは、この比率を追跡するために「要求使用率(Request Used (%))」を報告します。この比率が高いほど、利用可能な空き容量が少ないことを意味します。
この比率をモニターして、しきい値(90% など)を超えた場合や、比率が急激に上昇した場合にアラートを発行するように設定しておくと、アプリケーションの導入やスケーリングなどのイベントをすばやく検出できます。次に、クラスタエージェントによって報告されるメモリの要求使用率の例を見てみましょう。この例では、メモリの要求上限が 20G で、すでに 12G が使用されているため、現在の比率は 60% となります。
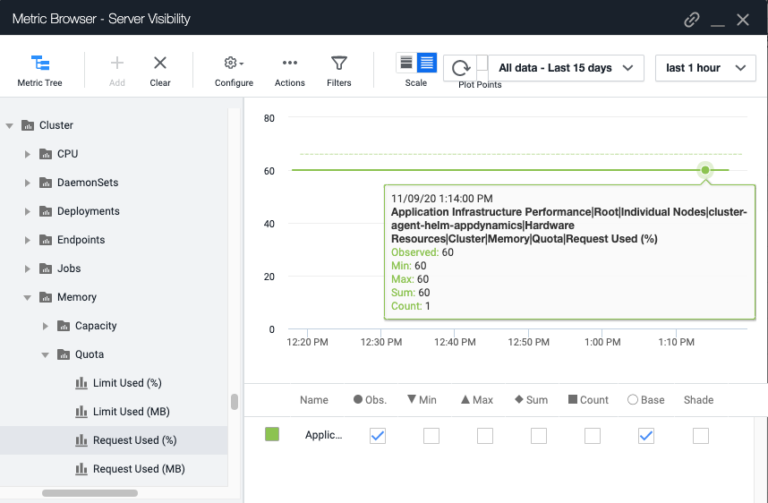
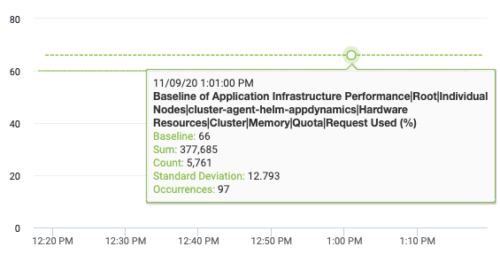
上の点線は、AppDynamics によってクラスタメトリックごとに自動計算されるベースラインです。これは過去 30 日間の全体平均で、66% とやや高くなっています。
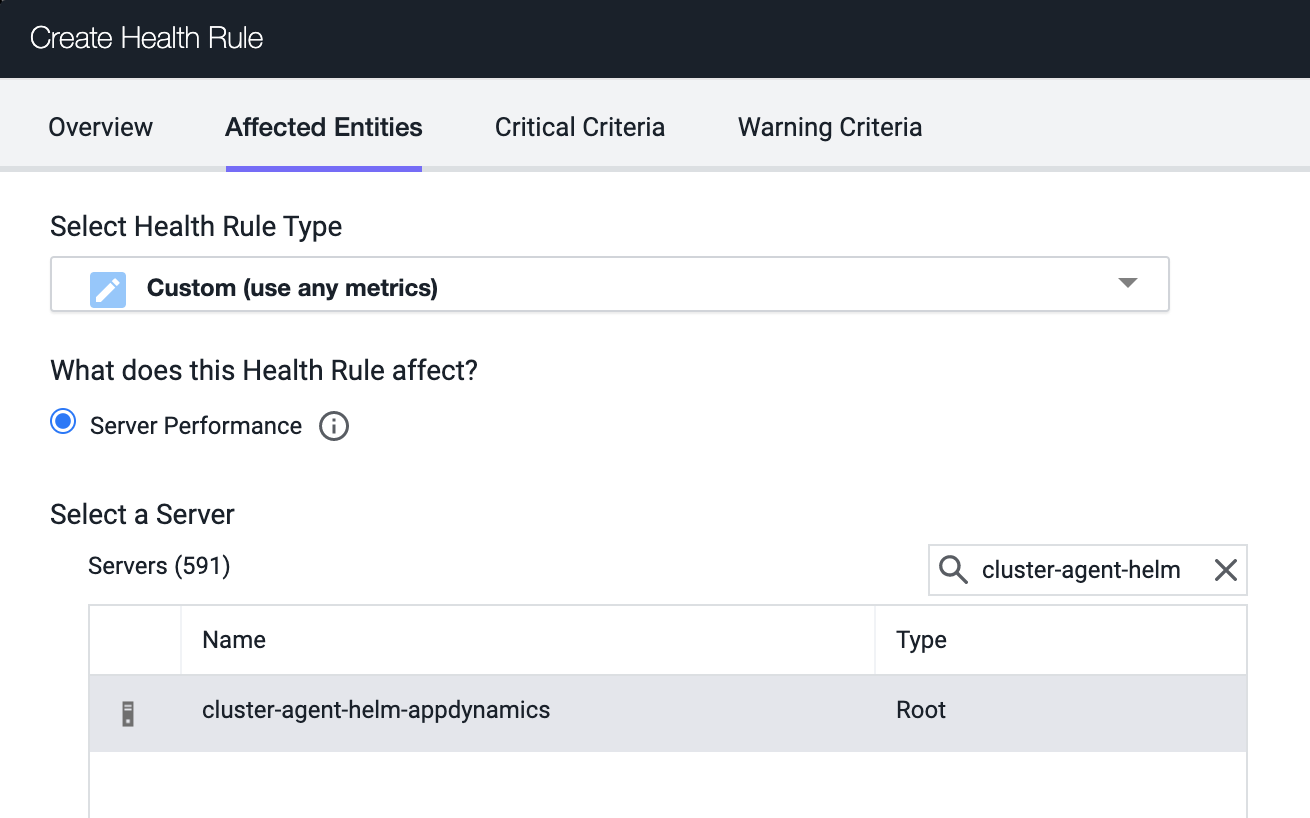
ここで、要求使用率が静的な上限を超えた場合や、要求使用率が大幅に変化した場合にアラートを発行する正常性ルールを定義します。正常性ルールの種類として [カスタム(Custom)] を選択し、モニタリングするクラスタを選択します。
次に [重要基準(Critical Criteria )] を設定します。まず、要求使用率が 90% を超えた場合に 1 つ目の [静的上限を超過(Static Limit Exceeded)] 状態が報告されるように設定します。2 つ目の [ベースラインを超過(Baseline Exceeded)] 状態は、同じ値がベースラインから 2 標準偏差逸脱すると報告されます。これにより、使用済み容量の急増をすばやく発見できます。
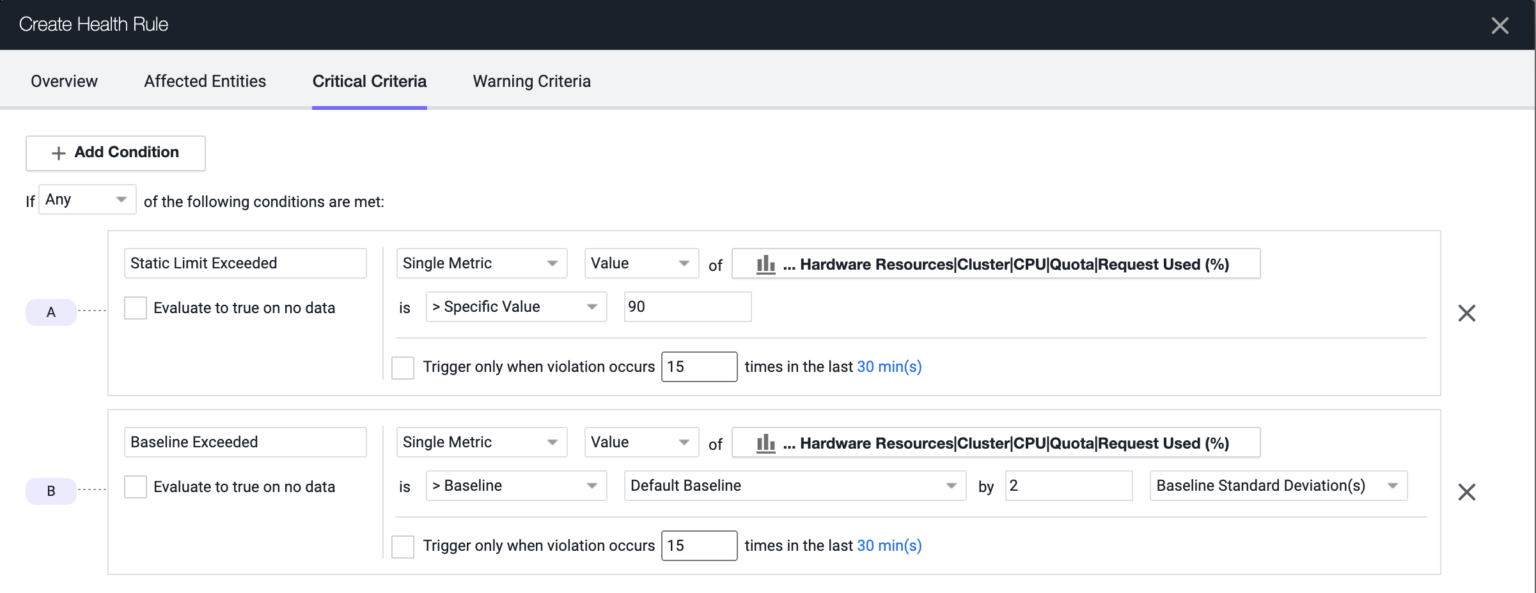
[評価ステータス(Evaluation Status)] が緑色になっている場合は、アラートが有効になっていて、指定した条件を超えるとアラートが発行されることを意味します。
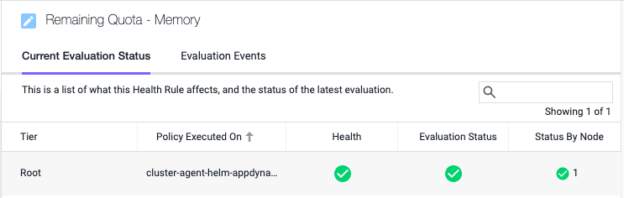
ここで、プロファイル サービス アプリケーションのレプリカを 2 個から 20 個にスケールアップしてみましょう。

すると、5 分以内に使用率が急上昇して正常性ルールが適用されたことがわかります。
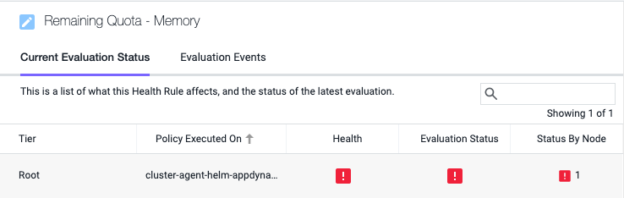
感度を下げて(標準偏差の値を増やして)調整することもできますが、使用率の上昇がベースラインの 60 より 2 標準偏差分高いため、[ベースラインを超過(Baseline Exceeded)] 状態が発生していることがわかります。
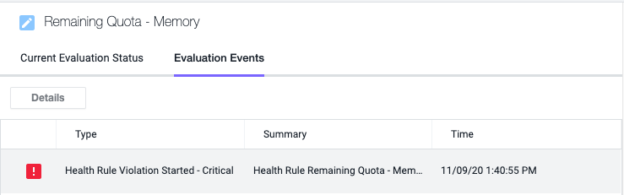
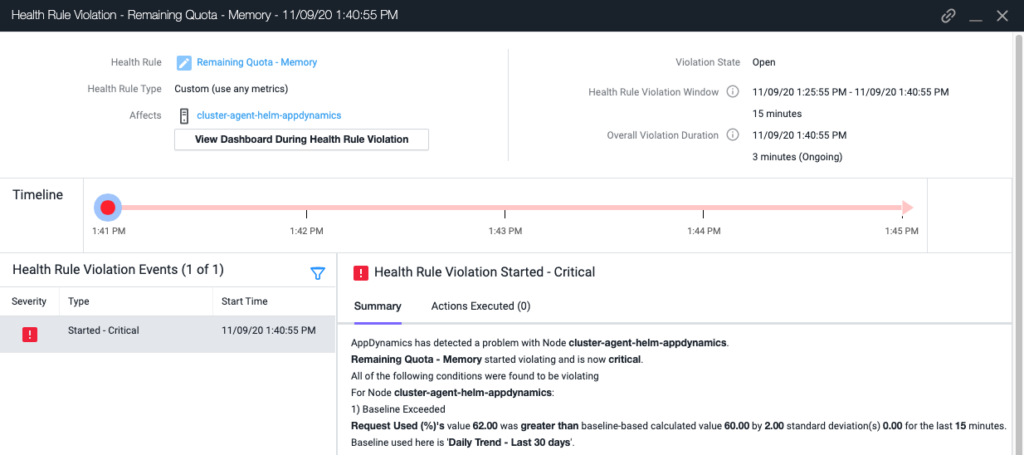
もう少し待つと、アラートが更新され、2 番目の [静的制限を超過(Static Limit Exceeded)] 状態が発生します。名前空間全体のメモリ使用率は 90% を超えています。
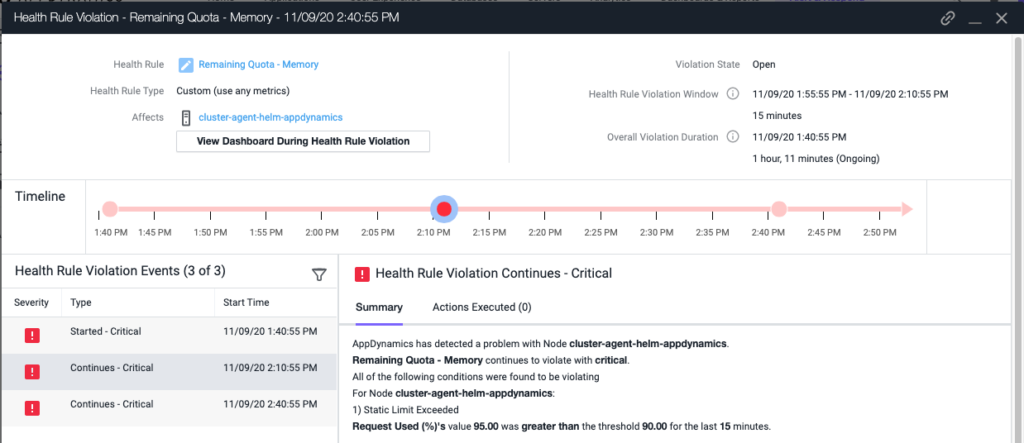
アプリケーションに影響が及ぶ前に問題に対処するためのアクションとして、チケットをオープンするだけでなく、これらの正常性ルールも使用すると効果的です。また、AppDynamics の設定 API を活用して、導入環境に適した正常性ルールとしきい値をクラスタのプロビジョニング時に自動設定することもできます。
このブログ記事では、Kubernetes の大規模導入環境においてオブザーバビリティを向上させる最新機能をいくつかご紹介しました。各機能の詳細とクイックデモについては、オンデマンドウェビナー「AppDynamics クラスタエージェントによるマイクロサービスのパフォーマンスの最適化」をご覧ください。
このブログ記事には、AppDynamics LLC(「AppDynamics」)の製品ロードマップ情報が含まれている場合があります。AppDynamics は、製品ロードマップ情報を、理由を問わずいつでも予告なしに変更する権利を留保します。ここで提供されている情報は、AppDynamics 製品の一般的な方向性を示すためのものであり、将来の製品機能を保証するものではありません。また、購入を決定する際に依拠すべきものではありません。AppDynamics の製品に関して記載されている機能の開発、リリース、および時期は、AppDynamics の単独の裁量により決定されます。AppDynamics は、一般提供の開始前であれば予定されている機能をいつでも変更する権利に加え、一般提供を一切行わない権利を留保します。
 Jeff Holmes
Jeff Holmes
Jeff Holmes は、AppDynamics のセールス イネーブルメント エンジニアです。ソフトウェア業界で 20 年以上の経験を有しており、 Pivotal Cloud Foundry などのクラウドプラットフォームのモニタリングを専門としています。Jeff はソフトウェアエンジニア、アプリケーションアーキテクト、エンタープライズ アーキテクトとして経験を積んできました。以前は、Pivotal 社のソリューションアーキテクトとして PCF 導入の初期段階にあるお客様をサポートしていました。