
この記事は、Common Hardware Group の Cisco フェロー Rakesh Chopra
によるブログ「Building AI/ML Networks with Cisco Silicon One
ニュース、記事、ブログ、さらには休憩中の雑談でも頻繁に話題に上っているように、人工知能(AI)と機械学習(ML)が私たちの社会を抜本的に変えていることは明らかです。このような状況の中、業界はこの爆発的な AI/ML の拡大に追いつくべく、急速に進化しています。
残念ながら、これまでハイパフォーマンス コンピューティング(HPC)で使用してきたネットワークは、AI/ML の需要を満たすまでには拡張できません。したがって業界としては、これまでの考え方を発展させて、AI/ML に対応できるだけの拡張性と持続可能性を備えたネットワークを構築する必要があります。
現在のところ、この業界は AI/ML ネットワークは 4種類の固有のアーキテクチャに分断されています。具体的には、InfiniBand、イーサネット、テレメトリアシスト型イーサネット、フルスケジュールドファブリックという 4 つです。
これらのテクノロジーにはそれぞれに利点と欠点がありますが、各テクノロジーに伴うトレードオフに対する見方は、Web スケールの大企業の間で様々です。このことから、この急速で大規模な成長に対応しようと、業界は複数の方向に同時に向かっているのです。
Cisco Silicon One の開発はこの状況を見据えたものです。
お客様が自社の AI/ML ネットワークを強化するために Cisco Silicon One を導入すれば、標準のイーサネット、テレメトリアシスト型イーサネット、フルスケジュールドファブリックのどれを使用するかにかかわらず、AI/ML ネットワークを構築できます。Cisco Silicon One のプログラム可能なアーキテクチャを利用し、ワークロードの進化に合わせて手法を柔軟に進化させてていくこともできます。

図 1. 柔軟性に優れた Cisco Silicon One
市場に出回っているその他のシリコンアーキテクチャは、限定的な導入モデルの利用を余儀なくさせます。そのため、お客様は検討する十分な時間もなく購入の意思決定を迫られ、進化に対応する柔軟性も制限されます。一方、Cisco Silicon One では、さまざまな運用モデルに合わせて柔軟にネットワークをプログラムできます。しかも、どの運用モデルでも最高水準の方式を実現できます。Cisco Silicon One は複数のアーキテクチャに対応できることから、お客様は取り扱うデータの特性を重視したうえで、お客様自身の基準に応じてdata-drivenな意思決定を行うことができます。
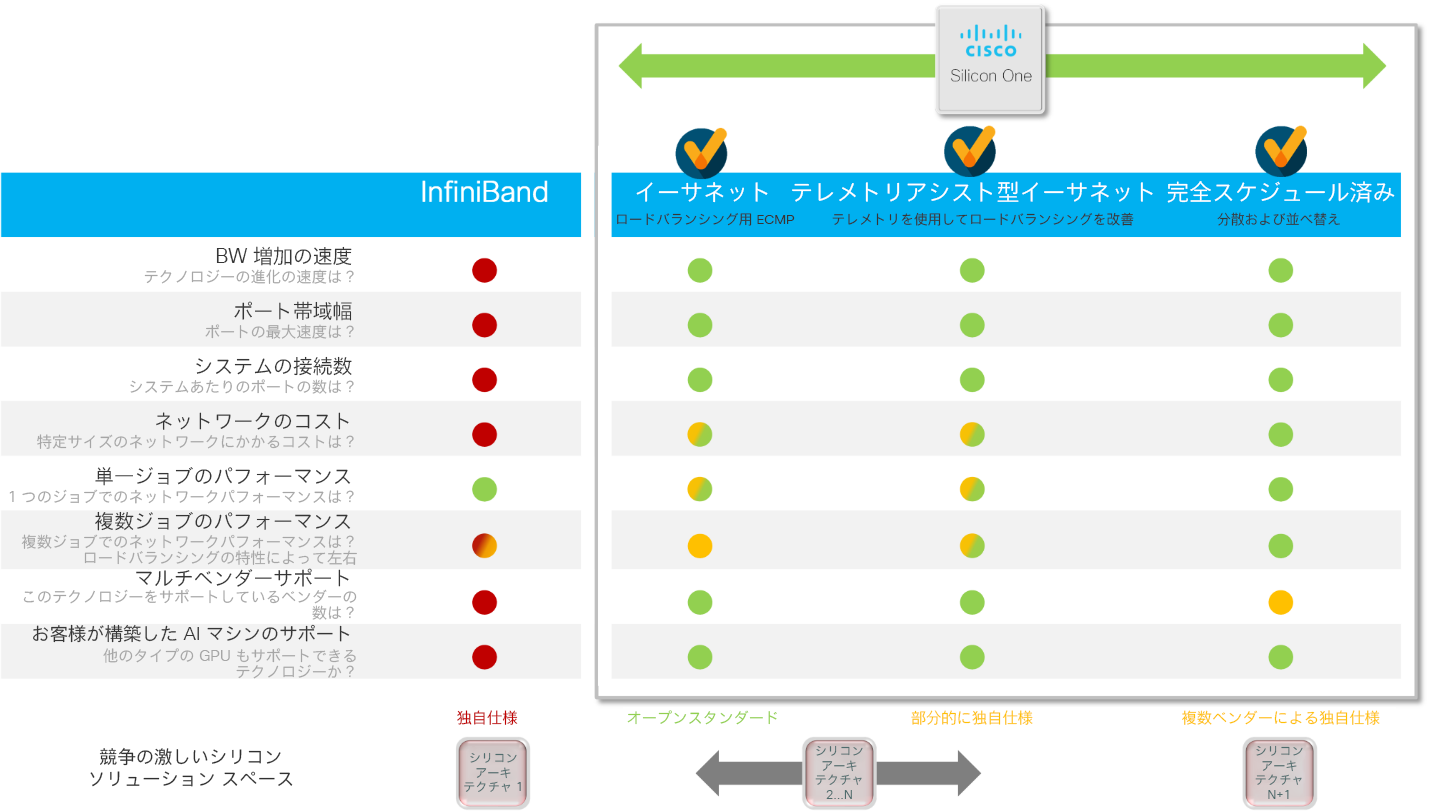
図 2. AI/ML ネットワークソリューションの選択肢
これらのテクノロジーに応じたメリットを理解するには、AI/ML の基本を理解することが重要です。多くのバズワードと同様に、AI/ML という言葉は、さまざまな固有のテクノロジー、ユースケース、トラフィックパターン、要件をひとまとめにした、あまりにも単純化された呼称です。わかりやすいように、ここではトレーニングクラスタと推論クラスタという 2 つの側面に注目します。
トレーニングクラスタは、既知のデータを使用してモデルを作成することを目的としています。これらのクラスタで、モデルをトレーニングします。そのために使用されるのは、膨大な数の GPU で実行される、非常に複雑な反復型アルゴリズムです。この複雑なアルゴリズムが、新しいモデルを生成するために数か月にわたって実行されることもあります。
一方、推論クラスタは、トレーニング済みのモデルを使用して未知のデータを分析し、答えを推論します。簡単に言うと、これらのクラスタはトレーニング済みのモデルで未知のデータの内容を推論するためのものです。トレーニングクラスタと比べると、推論クラスタは遥かに小さいコンピューティングモデルです。私たちが OpenAI の ChatGPT や Google Bard を操作する際は、推論モデルを操作していることになります。これらの推論モデルは、数十億個、さらには数兆個ものパラメータを持つモデルを長期間にわたって大規模にトレーニングして生まれた結果です。
このブログではトレーニングクラスタに焦点を当て、イーサネット、テレメトリアシスト型イーサネット、フルスケジュールドファブリックのそれぞれのパフォーマンスを分析します。このトピックに関する詳細は、私が 2022 年の OCP グローバルサミットで行ったプレゼンテーションでご確認いただけます。
AI/ML トレーニングネットワークは自己完結型の大規模なバックエンドネットワークとして構築され、そのトラフィックパターンは従来のフロントエンドネットワークとは大きく異なります。これらのバックエンドネットワークを使用して、特別なエンドポイント間で特別なトラフィックが送信されます。これらは以前はストレージ相互接続を目的に使用されていました。しかしながら、Remote Direct Memory Access(RDMA)と RDMA over Converged Ethernet(RoCE)の誕生により、現在のストレージネットワークの大部分は汎用イーサネットで構築されるようになっています。
現在、これらのバックエンドネットワークは、HPC と大規模な AI/ML トレーニングクラスタで使用されています。ストレージの場合と同じく、レガシープロトコルからの移行も進んでいます。
従来のフロントエンドネットワークと比べ、AI/ML トレーニングクラスタのトラフィックパターンは独特です。GPU は、All-to-All Collective と呼ばれるデータ転送で計算結果をピアに送信するときに、高帯域幅リンクを完全に飽和状態にすることがあります。このデータ転送の終了時に、バリアオペレーションにより、すべての GPU が最新の状態であることが確認されます。これが発生させるネットワーク内の同期イベントによって、GPU はアイドル状態になり、最も時間がかかっているネットワーク経由のパスが完了するまで待機します。すべてのパスが優れたパフォーマンスを発揮していることを確認するには、ジョブ完了時間(JCT, Job Completion Time)によってネットワークのパフォーマンスを評価します。

図 3. AI/ML の計算および通知プロセス
このトラフィックはノンブロッキング トラフィックであるため、同時発生し、高帯域幅を消費し、長時間残るフローとなります。フロントエンドネットワークでのデータパターンはこれとは大幅に異なります。フロントエンドネットワークで主に生成されるのは、多数の非同期かつ短時間で完了する低帯域幅フローです。ストレージ用にはそれとは別に、大きな非同期の長時間残るフローが生成されます。これらの違いはJCTの重要性と関係性があり、つまりネットワークパフォーマンスは極めて重要という事です。
それぞれのネットワークのパフォーマンスを分析するために、256 基の GPU、8 台のトップオブラック(TOR)スイッチ、4 台のスパインスイッチからなる小規模なトレーニングクラスタのモデルを作成しました。そのうえで、ネットワーク上で実行される同期ジョブの数とネットワーク帯域幅を増やしながら、All-to-All Collective を使用して合計 64 MB のデータを転送しました。
この調査の結果は劇的なものでした。
HPC は単一のジョブを対象に設計されたものですが、大規模な AI/ML トレーニングクラスタはそれとは異なり、現在の Web スケールのデータセンターで行われるのと同様に、複数の同時ジョブを実行するように設計されています。ジョブの数を増やすにつれ、ネットワーク内で使用されているロード バランシング スキームの効果が明らかになっていきます。256 基の GPU で 16 個のジョブを実行する場合、フルスケジュールドファブリックの JCT は 1.9 倍高速です。
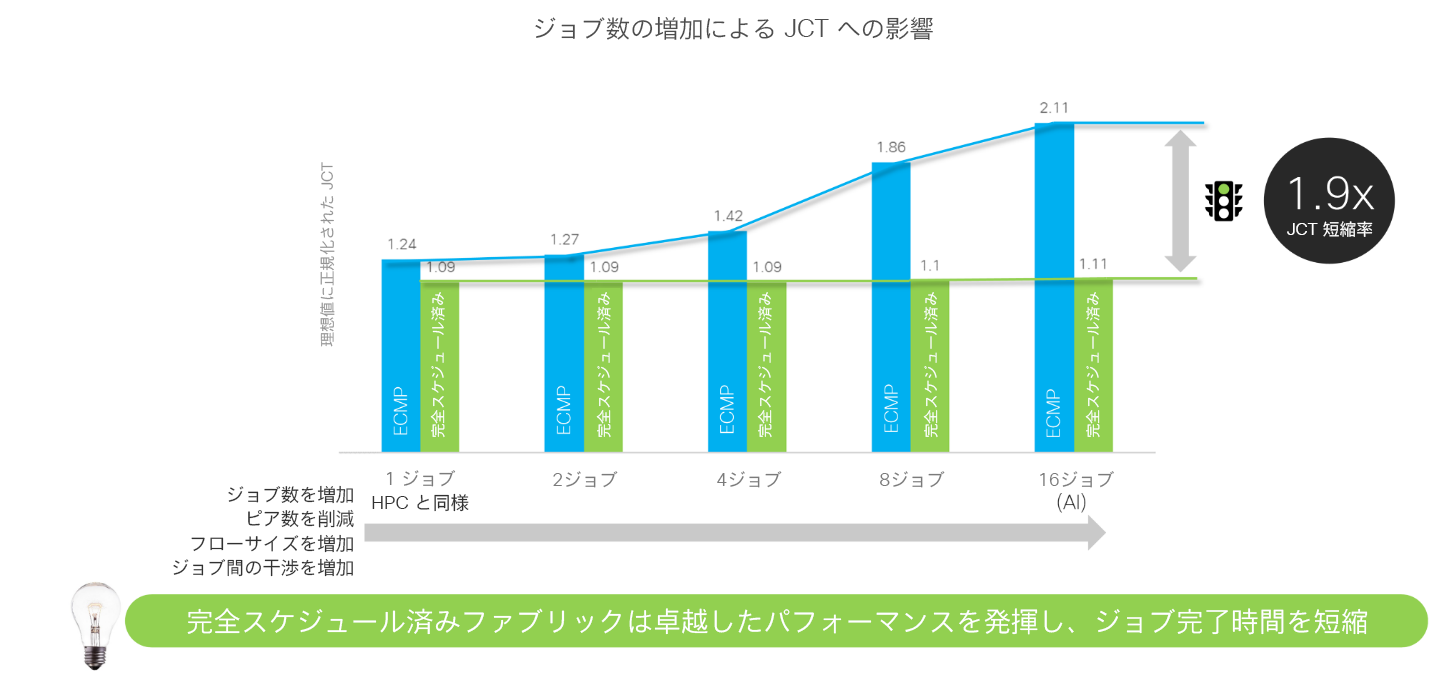
図 4. イーサネットとフルスケジュールドファブリックでのジョブ完了時間の比較
別の方法でのデータの調査として、ネットワークから GPU に送信されるプライオリティフロー制御(PFC)の量をモニタリングしたところ、GPU のうち5% の速度が、残りの 95% の GPU よりも低下しました。それとは対照的に、フルスケジュールドファブリックは完全なノンブロッキング パフォーマンスを実現し、ネットワークによって GPU が一時停止することはありません。
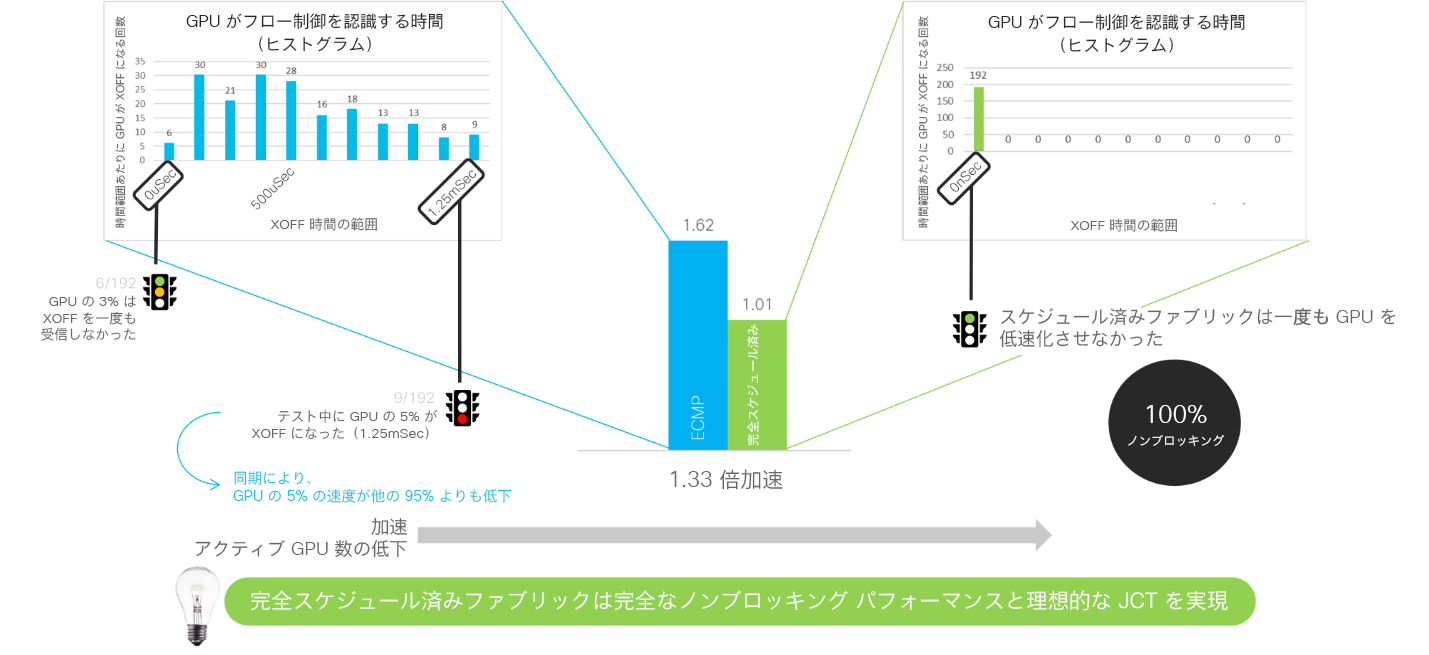
図 5. GPU に送信されるフロー制御の比較では、イーサネットと比べてフルスケジュールドファブリックは 1.33 倍の速度を達成
これは、フルスケジュールドファブリックを使用したネットワークでは、同じサイズのネットワークと比べ、接続できる CPU の数が 2 倍になることを意味します。標準のイーサネットのパフォーマンスを向上させるために、テレメトリアシスト型イーサネットでは、輻輳をシグナリングして、ロードバランシングをより効果的に決定できるようにしています。
前述のとおり、各テクノロジーに伴うメリットは、お客様によって、また時間の経過によっても変わってくるでしょう。イーサネットやテレメトリアシスト型イーサネットはフルスケジュールドファブリックよりもパフォーマンスに劣るとは言え、非常に貴重なテクノロジーであり、AI/ML ネットワークに広範に導入されるはずです。
では、お客様は何を基準にテクノロジーを選ぶのでしょうか。
多額の投資を厭わず、オープンスタンダード、そしてイーサネットの費用と帯域幅の関係の力学を利用したいというお客様は、AI/ML ネットワークにイーサネットを導入すべきです。この場合、テレメトリに投資し、ネットワークの負荷を最小限に抑え、インフラストラクチャに AI ジョブを慎重に配置することで、パフォーマンスを向上させることができます。
AI/ML ネットワークにフルスケジュールドファブリックを導入すべきお客様は、イングレス仮想出力キュー(VOQ, Virtual Output Queue)のノンブロッキング パフォーマンスを十分に活用し、フルスケジュールドや分散転送およびリオーダーが可能なファブリックを利用することにより、ジョブ完了時間を 1.9 倍加速したいと考える方です。ネットワーク装置を削減してコストと電力を節約しつつ、イーサネットと同じパフィーマンスを実現し、同じネットワークで GPU を 2 倍以上に増やしたいというお客様にも、フルスケジュールドファブリックがお勧めです。
コンバージドアーキテクチャと業界をリードするパフォーマンスによって、どのソリューションにも対応できるのは Cisco Silicon One だけです。

図 6. Cisco Silicon One でお客様のネットワークを進化
詳細:
Cisco Silicon One にアクセスする
Authors
