
前回の投稿では、仮想化における運用面の課題を書きました。今回は、もう 1 つの大きな課題である性能面を検討します。
1) 仮想化環境における転送性能最適化について
仮想化アーキテクチャのインフラストラクチャとなるサーバは CPU に特化したハードウェアであるため、当然、NPU(Network Processing Unit)や ASIC(Application Specific Integrated Circuit)に比べると転送性能は低いです。さらに、ハードウェアで行う割り込みや I/O などの各種処理を仮想化レイヤにてエミュレーションする必要があるため、オーバヘッドが大きくなります。
これまで、データセンターの仮想化においては、転送性能よりも柔軟性やスケーリングといった効用の方が大きく上廻っていたため、あまり転送性能の最適化は問題視されてこなかったのだと思います。しかし、通信事業者の場合、ネットワークサービスの提供に必要な品質と性能を安定的に供給する必要があるため、やはり転送性能を重視することになります。
そのため、転送性能最適化の方法論が必要になる訳ですが、仮想化アーキテクチャにおいてどのように性能を最適化させるか、という問題は、仮想化アーキテクチャの理念にも関わります。
サーバ ハードウェア、ハイパーバイザ、Guest OS、アプリケーションが垂直統合されたシステムの場合は、各コンポーネントの提供する仮想化支援機構、 機能および動作振る舞いを全て掌握できるため、比較的容易に転送性能の最適化を行うことができます。しかし、仮想化の特性を最大限に活かすためには、垂直統合型よりも水平統合型アプローチの方が適しており、そのためには可能な限り、特定のベンダーや特定の技術組み合わせに依存せずに、性能最適化を行えるような方法論が必要となります。
2) 転送性能最適化に関する取り組み
シスコでは、高付加価値高性能な ASIC の設計開発に力を入れてきており、これは今後とも継続します。一方これと並行的に、市販ハードウェアを利用した性能最適化のための技術開発も恒常的に行っています。ここでは、それらの性能最適化技術をいくつか紹介したいと思います。
a) Hypervisor bypass
仮想化環境における最大のオーバヘッドは、ハイパーバイザ におけるパケットのコピー処理です。そこで、VM(Virtual Machine)が ハイパーバイザ をバイパスし、直接ネットワーク アダプタ との間でデータをコピーすることが、転送遅延およびCPU 負荷を軽減させるための最も確実な方法となります(図1)。
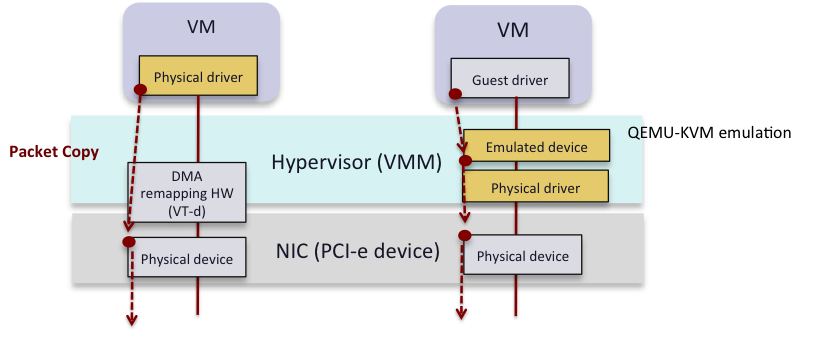
図1:Hypervisor bypass
Hypervisor bypass を実現し、かつ複数の VM(Guest OSが異なる場合もある)が 1 つの PCIe ネットワーク アダプタを共有できるようにするため、SR-IOV(Single Root I/O Vrituailization)が開発されました(図2)。 PCI-SIG(Peripheral Component Interconnect Special Interest Group)により、SR-IOV 技術の仕様策定および維持が行われています。
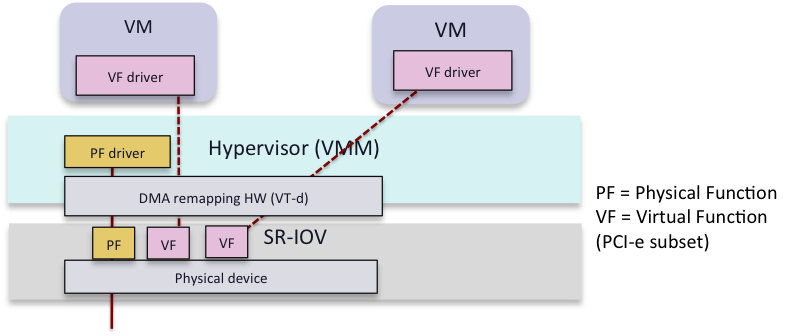
図2:SR-IOV
ハイパーバイザにおけるスイッチ処理をバイパスされたトラフィックは、ハードウェアによる折り返しスイッチが行われます。これを実現するのが Fabric Extender(FEX)技術です(図3)。シスコの FEX は IEEE802.1Qbg および IEEE802.1Qbh 標準に準拠し[1]、rate-limiting などの QoS 制御も可能です。 Linux-KVM を始めとするいくつかのハイパーバイザが、SR-IOV をサポートしています。

図3:Fabric Extender(FEX)概要
図4に、SR-IOV を実現する Linux-KVM のドライバ構成を示します。
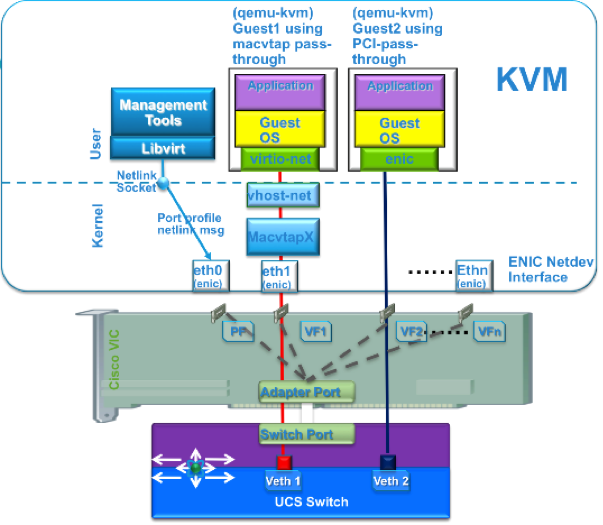
図4:VM-FEX with SR-IOV for Linux KVM
b) VPP (Vector Packet Processing)
VPP(Vector Packet Processing)は、シスコが開発した、汎用 CPU のためのパケット転送処理高速化技術(US Patent #US 7961636 B1)です。前項の Hypervisor bypass と同様、ハイパーバイザによるオーバヘッドを取り除き、かつパケット処理を並列化することにより、40Gbps(full duplex)の高スループットを実現します。
VPPでは、下記のように複数のインフラストラクチャをサポートし、できるだけ特定のインフラに依存しないようにしています。
- CPU:x86_64, Power PC, MIPS
- Hypervisor: KVM, ESXi
- NIC driver:
- Intel 82599 physical function / virtual function, intel e1000, virtio
- HP rebranded intel Niantic MAC/PHY
- Cisco VIC driver
- その他
また、単なる高速化支援機構ではなく、下記のようなプロトコル スタック機能を有します。
- VRF-awaeIPv4/IPv6 FIBs, L3 single-tagVLAN subinterfaces
- IPv4/v6 unequal cost multipath forwarding
- IPv6 ND, Router Discovery
- IPv6-L2TPv3 <-> L2 cross-connect
- GRE, MPLS-over-GRE tunnel encap/decap
- IPv4 arp cache with per-interface, per-addressrange proxy arp support
- Per-interface, per-protocol stats
- 5 tuple (really 6 tuple) classification
VPP は、Kernel ではなく User Space Process として動作します(図 5)。このことにより、万が一障害が起こったとしても障害を局所化でき、また、メンテナンス作業やソフトウェア アップグレード等を、システム全体をリブートすることなく行うことができる、などのメリットがあります。
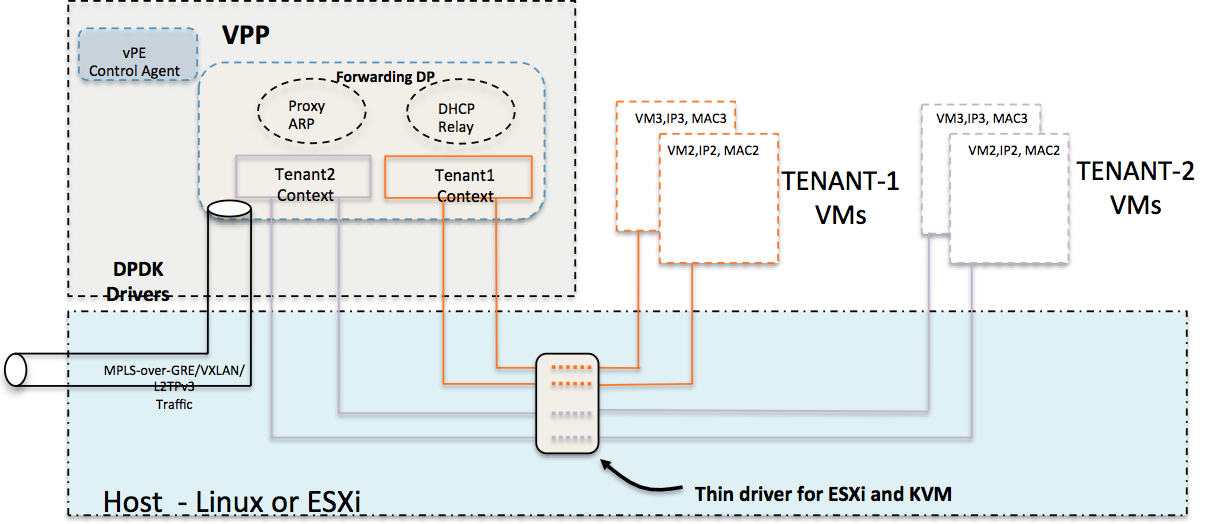
図5:Virtual Packet Processor
VPP は、まずはマルチテナント 仮想マネージドサービス(Cloud VPN/vMS) 向けのネットワーク制御を対象としたフォワーディング インスタンスとして実装されています(図6)。
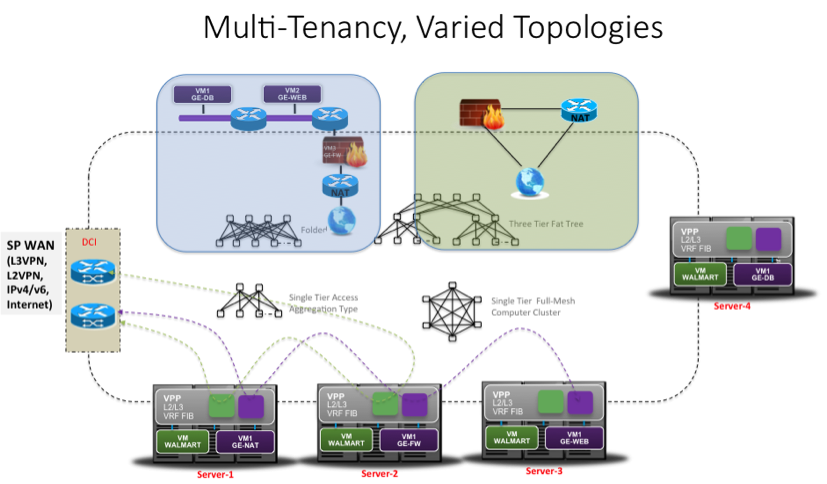
図6: 仮想マネージドサービス(vMS)向け Network Control と VPP
さらに、仮想スイッチ(Nexus 1Kv)とも統合され、Service ChainingのためのVirtual Forwarderとしても使用可能になります。[(2015年2月14日)このforwarderを使用して、NTT研究所様とのIETF Service Header方式によるService Chaining検証実験に参加させて戴いておりましたが、それがプレスリリースされましたので追記させて戴きます。Service Chaining実証実験 プレスリリースのURL ]
なお、これを独自技術のままにしてしまうとオープンなシステムとは言えないので、このフォワーディング インスタンスを制御管理するための YANG data model について、現在 IETF において標準化作業中です[2]。
c) Netmap
場合によっては、SR-IOV や VPP などの技術は、Linux Bridge や Open vSwitch に比べて少し大掛かりすぎるという懸念があります。そこで、シスコの仮想ルータである CSR(Cloud Services Router)では、性能最適化のために Netmap[3][4]を使用することにしています。
Netmap は Open Source の I/O インフラストラクチャ パッケージであり、下記の特徴を持ちます。
- Thin I/O stack
- LinuxのNetwork Stackをbypassする
- Zero copy
- ユーザ空間のデータプレーンが直接メモリにアクセスする
- シンプルな同期
- Ring操作の最小化
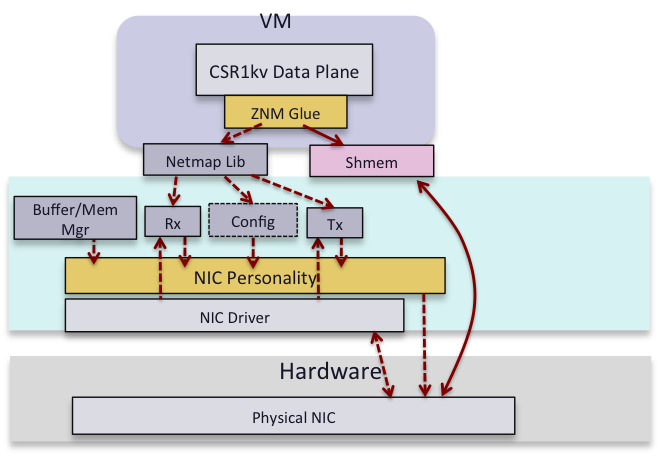
図11:CSR1KvによるNetmapの使用
3) 転送性能最適化に関する今後の方針について
シスコでは、仮想環境においても転送性能の最適化は必須と認識し、さまざまな技術に取り組んでいます。しかし、いくつか留意しないといけないことがあります。例えば、性能を上げる為に CPU に過度な負荷をかけてしまうと、肝心の処理に CPU を使えなくなってしまいます。また、垂直的な依存性を作ってしまうと、仮想化のメリットであるオープン性を活かせなくなってしまいます。シスコは仮想化専業ベンダーではありませんから、垂直統合にするくらいだったら ASIC の開発をした方がずっとよいのです。
さらに、オープンソースとの統合も大きな課題です。これら高速化技術が、例えばOpenstackから使えなければ運用性を欠きますし、オープンソースの進化を見据えながらVMではなくContainerなどに移行した方が良い場合があります。そのため、取り組みにあたって、次のような基本方針を掲げています。
- できる限り水平統合的アプローチを志向する
- オープンで適切な仮想化支援機構があれば、それを積極的に活用する
- ある特定の技術に拘泥されることなく、必要な技術を必要に応じて使用する
- オープン性にコミットする
- オープンソースを利用する
- コミュニティに貢献する
- 標準化
[1] ホワイトペーパー 「仮想マシン ネットワーキング:標準とソリューション」
[2] Rex Fernando, Sami Boutrous, Dhananjaya Rao, et al “Interface to a Packet Switching Element (IPSE)”, draft-rfernando-ipse-01.txt, October 2014
[3] Luigi Rizzo, Giuseppe Lettieri, Vincenzo Maffione, Speeding up packet I/O in virtual machines, IEEE/ACM ANCS 2013
[4] http://info.iet.unipi.it/~luigi/netmap
Authors


3 コメント
いつも楽しく見させていただいています。
特許登録番号が違っていませんか?
以下ではなく
US Patent #7961631 B1
これの気がします。
Vectorized software packet forwarding
US 7961636 B1
ついでに気が付きましたが
図5のところで、ESXiとするべきところが、EXSiになっています。
酒井さん、ご指摘のとおり、タイプミスがありました。どうもありがとうございます!こうして読んで下さっている方がいらっしゃるということに、身の引き締まる思いでおります。今後ともどうぞよろしくお願い致します。
修正いたしました!また、ちょうどNTT研究所殿との実証実験でVPPを使用したService Chainがプレスリリースされたので、それも追記しました。どうもありがとうございます。