
Après quelques billets sur SAP HANA il n’est peut-être pas inutile de revenir sur la notion de « in memory » et sa mise en œuvre dans des appliances.
Rappelons tout d’abord que le principe du « in memory » est de placer toutes les données en mémoire pour accélérer le traitement.
Je ne reviens pas en détail sur la prolifération des données qui a donné lieu au phénomène du Big data, je rappelle juste que l’on parle à présent de Zetabytes d’informations et que le développement des objets connectés va encore amplifier le phénomène.
Etre capable de traiter ces volumes d’informations permet des analyses plus fines pour prendre des décisions rapides mais permet également de pouvoir interagir avec des personnes ou des objets. Le champ d’application est large et nous n’en sommes qu’au début.
Si on regarde l’évolution des technologies de stockage on s’aperçoit que si la capacité a cru d’environ 100.000 fois, le débit n’a quant à lui augmenté que de 100 fois dans le même laps de temps.
L’enjeu : combler le GAP entre capacité et débit des disques
Pour combler ce gap entre capacité et débit on a donc été amené à revoir les architectures avec deux philosophies :
- Le traitement en mémoire du serveur (in memory) orienté temps réel (SAP HANA)
- Le parallélisme des accès sur de multiple disques « commoditisés » orienté batch (Hadoop)
Si quelques fois on oppose ces deux approches, elles sont malgré tout complémentaires. Hadoop étant censé pouvoir prendre en compte des gigantesques volumes de données alors que SAP HANA ciblera des besoins forts en temps réels. Il existe par ailleurs des possibilités d’intégration entre les deux qui permettent de lire des données provenant d’Hadoop pour les charger dans une base HANA.
Disposer de toutes les informations en mémoire améliore le traitement de manière considérable (accès aux données 10.000 fois plus rapide que disque !!).
Pour garantir la stabilité des performances et la disponibilité SAP a défini un certain nombre de caractéristiques imposées aux fournisseurs d’infrastructures pour concevoir des « appliances » validées par SAP pour HANA.
- Le choix des processeurs :
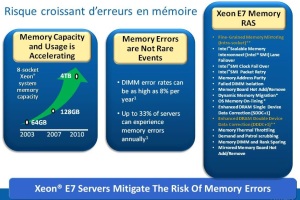

Seuls les processeurs Intel Xeon X7560 ou E7-X870 sont supportés. Ce choix s’explique sans doute en partie par les technologies mises en œuvre par Intel pour augmenter la fiabilité des systèmes. En effet 8% des DIMM et 33 % des serveurs sont sur un an susceptibles d’avoir une donnée corrompue en mémoire. Un phénomène qui s’accroit avec la quantité de mémoire.
- Des limitations en mémoire :
SAP a volontairement limité à 128 GB par socket la taille de la mémoire. Cette taille est inférieure aux possibilités des serveurs mais permet d’assurer un compromis performances/capacité stable dans le temps. Par contre cette limitation nécessite une approche dite « scale out » pour évoluer. C’est-à-dire qu’on ne peut pas augmenter la mémoire seule, l’augmentation se fait par l’ajout de nœud.
- Le rôle du stockage :
Si le traitement en mémoire positionne l’ensemble des données dans la mémoire du serveur, elle ne nous dispense pas pour autant de disposer de disques physiques mais leur rôle est limité à l’aspect sauvegarde. On trouvera sur ces disques les « logs » et les « save points ».
La taille des disques sera supérieure à celle de la mémoire puisque la mémoire utilise un facteur de compression qui peut aller de 3 à 7.
- Les évolutions :
On distingue deux types d’appliances :
– Des appliances “single node”destinés à des environnement de tests ou de petite production . Ces appliances ne sont pa évolutives et disposent de disques internes. On trouvera chez Cisco des applinaces de taille XS (128GB),S (256GB)et M (512GB) comme les tee shirts…Les serveurs utilisés sont des serveurs UCS en rack .

– Des appliances scale out construits autour de serveurs en lames UCS avec du stockage EMC ou NetApp. La configuration de base commence avec un module de base composé de serveurs UCS B 440 et l’évolution se fait par ajour d’un ou plusieurs modules extension composés de 4 serveurs en lames UCS 440. La taille mémoire sera par module d’extensionde 2TB hors compression (4 serveurs x 4 sockets x 128GB).

.
Authors
