
この記事は、プロダクト&ソリューション マーケティング チームのシニア マーケティング マネージャー Bill Shields によるブログ「Cisco UCS 480 ML M5 Server – Performance and Capacity for AI」
(2018/9/10)の抄訳です。
KD のブログは、AI が 50 年代半ばからどのように開発され、新しい IT の時代をどのように定義しているかについての優れた概説です。今回の記事では、お客様が自社データから最大限の価値を得るのに必要となるハードウェアについて深く掘り下げます。
シスコが M5 シリーズのサーバを発表したとき、個人的に注目したのはモジュラ設計![]() が特徴の UCS C480 M5 でした。UCS C480 M5 は 6 つの GPU をサポートしていますが、PCIe バスをベースにしています。AI/ML/DL(人工知能、機械学習、深層学習)のシステム設計を最適化しようとする場合、PCIe バスは実際に阻害要因になる可能性があります。そこでシスコのエンジニアは、優れたモジュラ設計を採用し、深層学習に特化させました。
が特徴の UCS C480 M5 でした。UCS C480 M5 は 6 つの GPU をサポートしていますが、PCIe バスをベースにしています。AI/ML/DL(人工知能、機械学習、深層学習)のシステム設計を最適化しようとする場合、PCIe バスは実際に阻害要因になる可能性があります。そこでシスコのエンジニアは、優れたモジュラ設計を採用し、深層学習に特化させました。
パフォーマンスと容量の妥協のないバランス
 AI コンピューティングのリーダー企業である NVIDIA 社との協力で開発された UCS C480 ML M5 ラック サーバは、8 つの NVIDIA Tesla V100 Tensor Core
AI コンピューティングのリーダー企業である NVIDIA 社との協力で開発された UCS C480 ML M5 ラック サーバは、8 つの NVIDIA Tesla V100 Tensor Core![]() GPU と NVIDIA NVLink 相互接続
GPU と NVIDIA NVLink 相互接続![]() をサポートします。V100 は、深層学習分野における 100 テラフロップスの壁を、桁外れとなる 640 個の Tensor コアで初めて打ち破った GPU です。NVLink は PCIe の 10 倍の帯域幅を提供し、超高速 GPU に最適なパフォーマンスを提供するポイントツーポイント ネットワーク(ハイブリッド キューブ メッシュ)ですべての GPU を接続します。
をサポートします。V100 は、深層学習分野における 100 テラフロップスの壁を、桁外れとなる 640 個の Tensor コアで初めて打ち破った GPU です。NVLink は PCIe の 10 倍の帯域幅を提供し、超高速 GPU に最適なパフォーマンスを提供するポイントツーポイント ネットワーク(ハイブリッド キューブ メッシュ)ですべての GPU を接続します。
 非常に強力な V100 に電力を供給して冷却するため、エアーフローに優れたモジュラ型シャーシと高低差ヒートシンクを利用しています。写真では、下部に 24 の SFF ドライブ ベイ、中程に CPU トレイ、上部に空きトレイを示しています。
非常に強力な V100 に電力を供給して冷却するため、エアーフローに優れたモジュラ型シャーシと高低差ヒートシンクを利用しています。写真では、下部に 24 の SFF ドライブ ベイ、中程に CPU トレイ、上部に空きトレイを示しています。
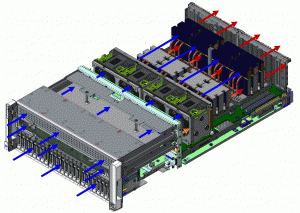 4 つの 92 mm ファンがハード ドライブ ベイと CPU/空きトレイを通るように冷気を引き込み、最初の 4 つの GPU を直接冷却します。では 1 番目の GPU の並びの後ろに配置されている 2 番目の並びはどのように冷却されるのでしょうか。レンダリングを見ると、4 つの背面 GPU ヒートシンクは前面の 4 つより高くなっています。これにより空きトレイのエリアからの冷気が邪魔されず、温まらないまま背面のほとんどのヒートシンクまで直接流れ、冷却ができるのです。
4 つの 92 mm ファンがハード ドライブ ベイと CPU/空きトレイを通るように冷気を引き込み、最初の 4 つの GPU を直接冷却します。では 1 番目の GPU の並びの後ろに配置されている 2 番目の並びはどのように冷却されるのでしょうか。レンダリングを見ると、4 つの背面 GPU ヒートシンクは前面の 4 つより高くなっています。これにより空きトレイのエリアからの冷気が邪魔されず、温まらないまま背面のほとんどのヒートシンクまで直接流れ、冷却ができるのです。
UCS C480 ML M5 のもう 1 つの主要な特徴は、サポートされているストレージの容量です。24 の SFF ドライブ ベイは、182 TB を上回る SSD ストレージをサポートします。これは、多くの異なるデータ セット用の余地があり、外部ストレージに依存する必要がないため、ソリューション全体のコストを削減することに繋がります。SSD よりもさらに高速のストレージが必要な場合、ベイのうちの 6 つは NVMe をサポートします。
UCS C480 ML M5 のその他の特徴は以下の通りです。
- 最大 28 コアのデュアル Intel Xeon スケーラブル プロセッサ
- 128 GB の 2666 MHz DDR4 DIMM を使用した最大 3 TB のメモリ
- 100G Cisco UCS VIC 1495 または他のアダプタ用の 4 つの PCI Express(PCIe)0 スロット。
- モジュール型の内部 Flex ストレージ オプション:2 SATA
- Cisco Integrated Management Controller(IMC)
- 2 つの 10Base-T Gbps LOM イーサネット ポート
データセンターにおけるデータ
GPU を搭載したサーバは各社から提供されています。シスコの違うところは、シスコのみがシステムを提供できるということです。ここにおけるシステムとはどういう意味でしょうか。UCS をひとことで言えば、一元化管理モデルを備えたファブリック中心アーキテクチャです。すべてのシスコのサーバ:B シリーズ ブレード、C シリーズ ラック、Sシリーズ 高密度ストレージ サーバ、および HyperFlex は単一のツール、Cisco Intersight で管理可能です。Intersight はクラウド ベースのシステム管理プラットフォームであり、解析と機械学習によって強化されます。これにより組織はより高いレベルのオートメーション、シンプルさと効率を達成することができます。サーバ フォーム ファクタ、ワークロード、場所を問わず、分散型コンピューティング環境を管理する全体的で統合されたアプローチを提供します。シスコだけが、ポートフォリオ内のどのサーバが問題を解決するのに最適であるかに関係なく、エッジであってもデータセンターであってもデータの処理をサポートする統合システムの一部として AI/ML/DL ソリューションを提供できます。Intersight は、UCS Manager の機能を拡張します。すべての UCS サーバは、VIC を Fabric Interconnect および UCS Manager とともに使用できます。UCS Manager は、サービス プロファイルにより、すべてのサーバの統合された組み込み管理機能を提供します。サービス プロファイルにより、ハードウェアを設定および管理できます。
Cisco Intersight または UCS Manager を使わなければならないのでしょうか。もちろん、そのようなことはありません。すべての Cシリーズ ラック サーバと同様、UCS C480 ML M5 には CIMC があります。CIMC、API、または業界標準管理プロトコル(たとえば Redfish![]() や SNMP など)によりサーバを管理できます。
や SNMP など)によりサーバを管理できます。
まとめ
GPU 対応サーバの恩恵を受けることができる使用例には、ごく数例を挙げるだけでも、不正行為検出、医療研究、エクスペリエンスのパーソナライズ、的を絞ったマーケティングなどがあります。業界に関係なく、NVIDIA Tesla V100 Tensor コア GPU を搭載した C480 ML M5 より優れたパフォーマンスを発揮するものはありません。このシステムは UCS プラットフォームの一部として利用しやすく、高いパフォーマンスを発揮します。業界で唯一の、一環したクラウド ベースの自動運用モデルが特徴です。
何週間ものコンピューティング リソースを消費する AI モデルも、数時間でトレーニングできます。トレーニングの時間を大幅に短縮することで、まったく新しい領域の問題が AI により解決可能になります。これは、エンタープライズ規模の深層学習を IT によって実現できるスケーラブル ソリューションです。
人工知能および機械学習用のシスコの新しいプラットフォームについてさらに詳しく情報を得たい場合には、シスコ セールス チームまたはシスコ パートナーにお問い合わせください。お客様の AI/ML/DL ワークロードについてお尋ねし、UCS C480 ML M5 サーバがどのようにニーズを満たすかご説明します。
UCS C480 ML M5 の詳細については、www.cisco.com/jp/go/ai-compute もご覧ください。
Cisco UCS ポートフォリオ全体の詳細については、https://www.cisco.com/c/ja_jp/products/servers-unified-computing/index.html をご覧ください。