
En mi blog anterior sobre Full-Stack Observability os contábamos, con un ejemplo práctico, los beneficios que aporta Cisco FSO en los entornos de nube híbrida. Ahora que ya tenéis una visión general sobre esta solución, quizá pueda ser interesante hacernos esta pregunta: ¿tenemos claro cual es el problema que estamos intentando solucionar?
¿Qué problema queremos solucionar?
Según un estudio de Gartner, el coste de una caída de IT es, de media, unos USD 5.600 por minuto, que en cifras más redondas son unos USD 300.000 la hora, y si hablamos de servicios públicos al ciudadano, el coste directamente no se puede medir. Esto son solo cifras pero lo que es relevante es que las caídas de IT tienen un impacto muy negativo en el negocio o en el ciudadano.
Asimismo, cabe recordar que las demandas de usuarios de aplicaciones es cada vez más exigente: “always fast”, “always on”.
En este escenario complejo, ¿adivinad sobre quién recae la presión? ¿Quizá sobre los mismos departamentos de IT y de operaciones que tienen que dar soporte a los nuevos entornos distribuidos sin descuidar a los tradicionales?
Veamos cómo suele responder IT a una caída de forma tradicional:
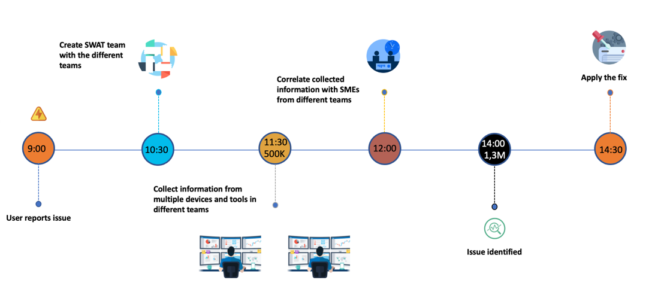
Si tenemos en cuenta el coste medio por minuto de una caída, quizás estos tiempos ya no son aceptables, y no se trata de un problema de capacitación de los departamentos de IT. Los nuevos entornos híbridos distribuidos y las complejas interdependencias entre ellos suponen una presión insostenible que llega desde los departamentos de operaciones.
Es claro que para poder reducir estos tiempos de resolución de una incidencia se hace necesario buscar nuevas formas de operación.
Si es necesario reducir el tiempo de resolución de incidencias, ser proactivos y evitar riesgos es ahora fundamental. Así, la imagen de abajo representa un modelo más ágil y proactivo de operación:
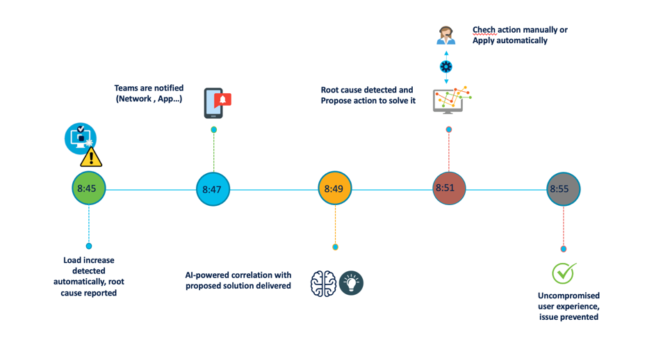
Si miramos con un poco de detalle los dos modelos anteriores se puede ver cuál es la principal diferencia entre ellos:
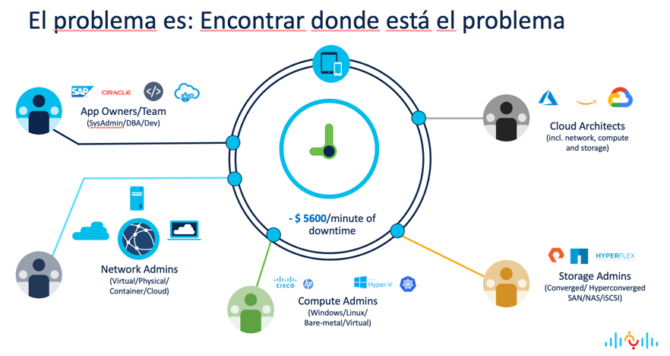
A los pilares de este nuevo modelo de operación, que nos debe guiar a la causa raíz del problema ágilmente, Gartner los denomina “Observabilidad”:

Tras identificar el problema a solucionar, Cisco ha desarrollado su plataforma de Full-Stack Observability que se sustenta en tres soluciones:

Desde un panel de control único ofrecemos visibilidad completa de la experiencia del usuario para cada aplicación:
- Appdynamics cuidará de la salud del código de la aplicación.
- Intersight Workload Optimizer vigilará, en tiempo real, de que la aplicación disponga de los recursos de infraestructura que necesite al menor coste.
- ThousandEyes velará para que las comunicaciones extremo a extremo, desde el usuario a la aplicación, cumplan los niveles de servicio que garanticen su experiencia.
La integración entre estos elementos, sumado a un contexto de negocio, nos indicará el impacto que una anomalía técnica tiene en las operaciones y en la experiencia del usuario y nos sugerirá cómo remediarlo.
En mis siguientes blogs me gustaría desarrollar, con más detalle, una de las soluciones que componen Cisco FSO, que es Intersight Workload Optimizer.
Os anticipo un poco en este video corto de IWO en acción.
¡Hasta la próxima!
Leer más
5 seminarios para aprender a gestionar la infraestructura híbrida en la nube
5 beneficios de consolidar la operación de la nube híbrida con Intersight
Full Stack Observability: la solución que optimiza la experiencia del usuario
Authors
2 Comentarios