
No es nuevo que vivimos en una cultura digital, donde la experiencia del usuario es crítica para cualquier negocio o servicio al ciudadano. Si tienes un negocio o trabajas en el sector público, con seguridad lo sabrás mejor que yo.
Además, la digitalización está empujando a las empresas a un modelo ágil en el desarrollo de sus aplicaciones, un modelo cloud-native, donde los contenedores y microservicios se distribuyen en varias nubes, pero tienen todavía muchas dependencias con entornos tradicionales.
¿Qué significa esto? Pues el resultado es un aumento en la complejidad en TI, donde diferentes departamentos trabajan para monitorizar el rendimiento de las aplicaciones, optimizarlas y remediar problemas sobre innumerables capas: apps, bases de datos, seguridad, redes, infraestructuras, servicios cloud etc.
Cada capa dispone de sus herramientas de monitorización, pero estas suelen trabajar de forma aislada sin correlacionarse de forma inteligente con el stack completo. Por suerte, en Cisco tenemos Full-Stack Observability que hace la gestión mucho más fácil.
¿Cómo funciona Full-Stack Observability?
Las empresas necesitan convertir esa visibilidad aislada en un modelo de información útil y global, correlacionando los fallos técnicos con el impacto en el negocio. El modelo de visibilidad debe ser extremo a extremo, observando las diferentes capas que soportan a la aplicación y su conectividad como un conjunto, empezando por la conectividad desde internet, pasando por las redes de comunicaciones privadas, la infraestructura del centro de datos, privado y público, hasta llegar a la capa de aplicación.
Para conseguir este objetivo, Full-Stack Observability proporciona un panel de control único que te muestra un análisis global de la experiencia del usuario con contexto de negocio y permite predecir y remediar problemas de forma ágil y guiada.
El panel de control que consolida y correlaciona el estado de salud de la aplicación se sustenta en la integración de estas soluciones:
AppDynamics: ofrece visibilidad completa del stack software de la aplicación
Intersight Workload Optimizer: proporciona visibilidad del stack de infraestructura de la nube híbrida
Thousand Eyes: da visibilidad del estado de la red extremo extremo ya sea privada o en Internet.
Ahora que ya sabes la teoría te daré un ejemplo práctico del funcionamiento de Full-Stack Observability con el caso de la empresa TeaStore que tiene un negocio de venta online de té.
TeaStore perdía pedidos online hasta que llegó Full-Stack Observability
TeaStore es una empresa que suministra té online. Su aplicación está desarrollada con micro-servicios sobre una infraestructura híbrida. En su centro de datos privado está desplegada la base de datos y en la nube pública está desplegado el front-end y el resto de servicios de la aplicación. El gateway de pagos es externo, por lo que la conexión se realiza vía Internet.
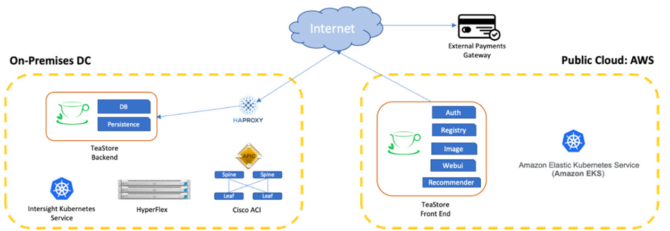
Un día, lunes 8 am (porque siempre estas cosas suceden un lunes 8 am cuando recién nos estamos recuperando del fin de semana) el departamento de operaciones de la empresa reporta:
Estamos perdiendo pedidos, ¿Qué pasa?
¿Está saturada la salida a Internet? ¿Nos está fallando algún equipo en la red del centro de datos? ¿Tenemos algún servidor con la CPU o la RAM saturada? ¿Las instancias de cloud funcionan correctamente?¿El último código que pasamos a producción está funcionando bien? Por favor, Que cada departamento analice si su dominio funciona correctamente. Uh, espera, espera…, ¿Seguimos usando herramientas aisladas donde la correlación de información útil es inmanejable?
No, con Cisco Full-Stack Observability disponemos de un panel de control único, para nuestra app de venta online de té, que integra y correlaciona los problemas técnicos con las métricas de negocio definidas.
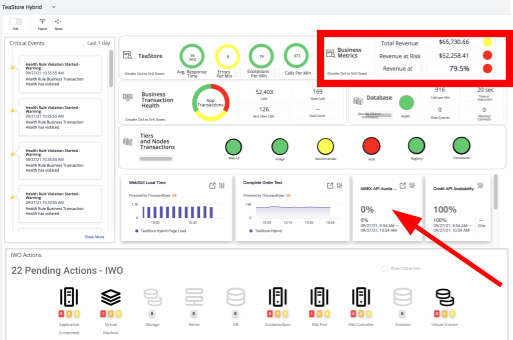
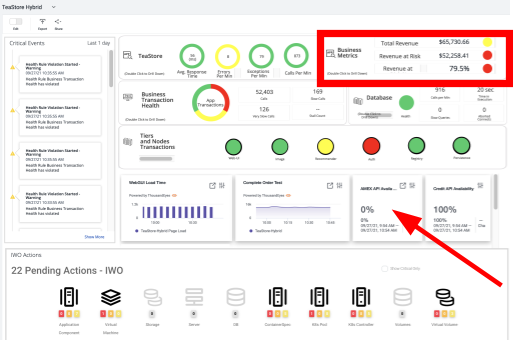
Panel FSO de la App TeaStore
Un vistazo rápido a las métricas de negocio nos muestra un claro impacto en los pedidos. También se observa la disponibilidad del 0% del API del gateway de pago de AMEX. ¿Qué es lo que provoca esta indisponibilidad del medio de pago?
Resolviendo la incidencia
Veamos cómo, los diferentes equipos implicados en la operación de TeaStore, trabajan de forma coordinada y en paralelo para confirmar la anomalía y remediar la causa de la misma.
En primer lugar, el equipo de operación de la infraestructura de la nube híbrida se pregunta:
¿Está funcionando bien nuestra infraestructura híbrida? ¿Por dónde empezamos? Muy sencillo, primero observamos que el panel de Full-Stack Observability nos indica que hay 22 recomendaciones para optimizar nuestra infraestructura, veamos cuáles son.
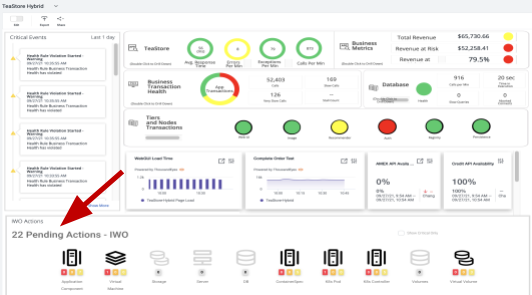
Con un solo click Full-Stack Observability no redirige a la visión que Intersight Workload Optimizer tiene sobre la infraestructura que soporta la app de ventas de TeaStore.
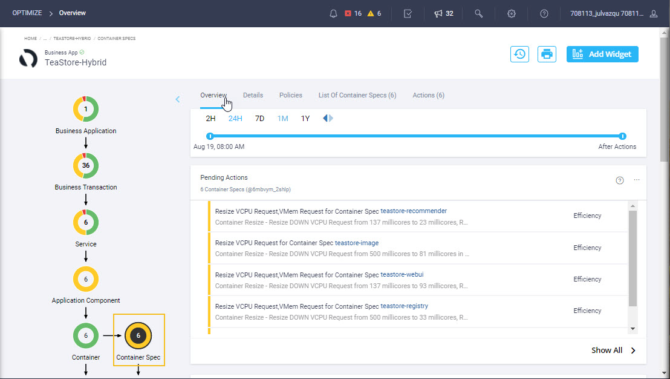
Visibilidad de la aplicación TeaStore en IWO
La integración entre AppD e IWO le permite a este último entender con mucha granularidad qué recursos demanda la aplicación de ventas TeaStore en cada capa de la nube híbrida. IWO nos muestra recomendaciones de optimización, pero no observamos ninguna crítica. La infraestructura de nuestra nube híbrida no es la causa del problema, pero tiene margen de optimización.
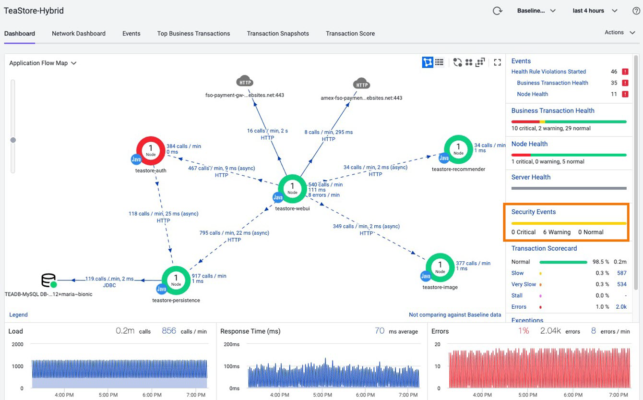
En segundo lugar, el equipo de operación de la aplicación revisa el panel de control. Allí se pueden observar algunos problemas en algunas transacciones de la aplicación.
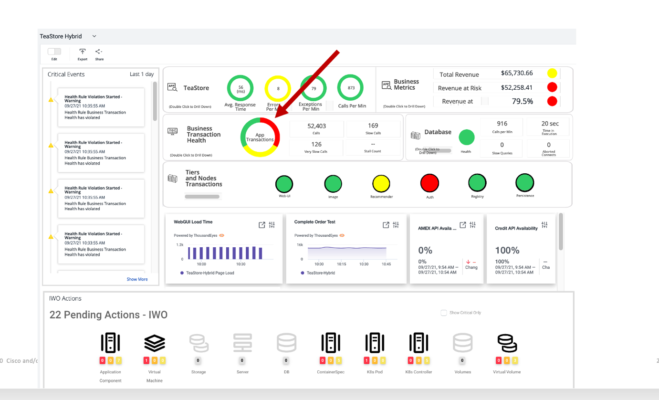
Con un solo click sobre el icono, el panel de control nos redirige a la visión que AppD tiene de la aplicación TeaStore. Es una visión completa del despliegue en nube híbrida.
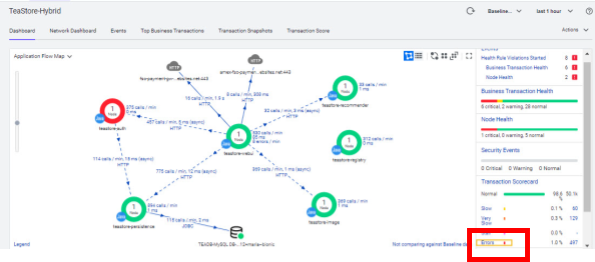
Dependencias entre los tier de la app TeaStore
Un segundo click en los errores nos muestra el detalle del código al más bajo nivel y nos confirma que el API del Gateway de pago está dando un error 403, indicando que no está disponible. Confirmamos que nuestra aplicación funciona bien.
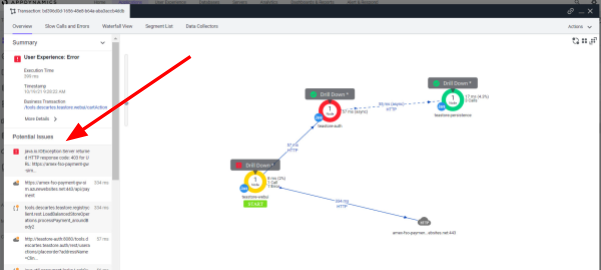
Sin embargo, sigue habiendo preguntas por responder. ¿Qué pasa con el medio de pago? ¿Por qué no está disponible? ¿Qué es lo que está fallando? ¿El gateway de pago o las comunicaciones?
En tercer lugar, interviene el equipo de operación de la red quienes en paralelo a las tareas de operación del grupo de aplicaciones, están depurando el estado de la red.
Con un click en el icono del API de Amex vamos directamente a la información de red relevante para el acceso a este medio de pago monitorizado por ThousandEyes.
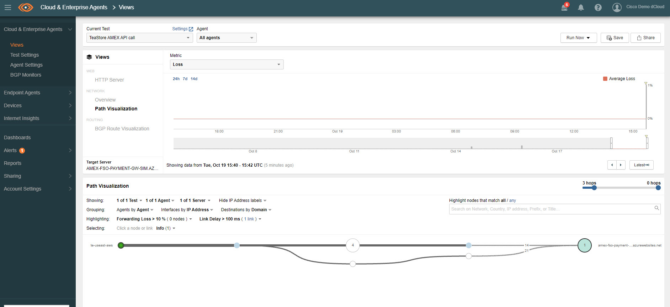
Monitorización de conectividad del Gateway de pago
Los agentes de ThousandEyes confirman, de forma gráfica, que la conectividad es correcta pero el API del medio de pago no responde a las llamadas. Confirmamos que la red no es el problema y se concluye que es un problema externo del servicio de pagos.
Por último, el equipo de operación de seguridad confirma que también está chequeando el estado de seguridad y vulnerabilidad de nuestra aplicación e infraestructura puesto que la detección rápida de vulnerabilidades es vital.
Nuestra solución de AppD nos muestra, también, visibilidad sobre el estado de las vulnerabilidades reconocidas (CVE) para las versiones de software y librerías de la aplicación de ventas de TeaStore.
Los operadores de seguridad observan el estado de seguridad de la aplicación con el detalle necesario para poder analizar las vulnerabilidades halladas y su impacto.
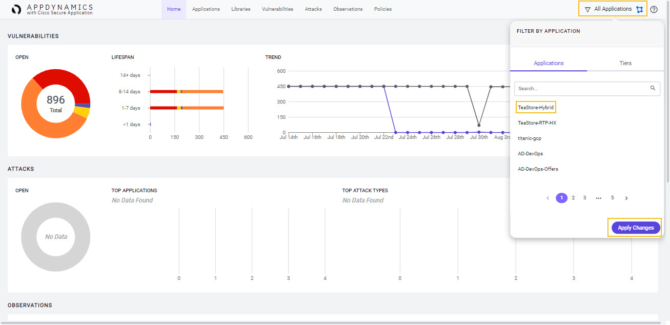
Vulnerability Dashboard de TeaStore
En conclusión, la resolución de la incidencia finalizó con el servicio de pago reparando el caso que abrimos y TeaStore reanudó la venta online. Los diferentes departamentos de operaciones revisaron sus dominios gracias a que Full-Stack Observability que fue capaz de mostrar, en un panel único de control, el impacto directo en el negocio.
De este caso me parece interesante destacar cómo Cisco Full-Stack Observability proporciona a los clientes la capacidad de evolucionar sus silos de monitorización a un entorno de observabilidad global de la experiencia del usuario, permitiéndoles dar una experiencia digital excepcional y mantener la seguridad y el rendimiento a un precio óptimo.
¿Te gustaría saber más sobre la herramienta o quieres compartir tu experiencia? Déjame tu comentario abajo.
Leer más
5 seminarios para aprender a gestionar la infraestructura híbrida en la nube
5 beneficios de consolidar la operación de la nube híbrida con Intersight
Aumentando la visibilidad del tráfico de red con Cisco Nexus Dashboard Data Broker
Authors
1 Comentarios