
これからのデータセンターに求められる要件はどんなものでしょうか。第一は、BCP(Business Continuity Plan:業務継続計画)/DR(Disaster Recovery:災害対策)の実現です。それにはデータセンターの「分散」が欠かせません。距離が離れた複数のデータセンターにシステムを分散することで、災害などによるサービス停止を防止できます。第二は、リソースの最適化・投資効率の向上です。これまで主に採用されていたアクティブ/スタンバイ構成の分散データセンターでは、待機系のリソースがほとんど使われず非効率でした。しかし「データセンターそのものを仮想化」して複数のデータセンターを 1 つのシステムとして運用できる仕組みを作れば、全データセンターを常時稼働させるアクティブ/アクティブ構成を容易に実現でき、負荷や必要に応じてデータセンター資源を適切に配分できるようになります。そのためリソースの無駄がありません。さらに仮想マシンをデータセンター間でシームレスに移動可能にすることは、BCP/DR の実現にも寄与します。
このような特性を持つデータセンターをシスコでは「分散仮想データセンター」と定義し、クラウド サービスのインフラを担うシステムになるものだと位置付けています。ここで言う仮想データセンターとは、サーバ仮想化技術を採用したデータセンターという意味ではなく、前述のようにデータセンターそのものを仮想化して複数のデータセンターを 1 つのシステムとして運用できるようにしたもののことです。ベンダーによってはマルチ仮想データセンターと呼ぶこともあります。シスコが考える分散仮想データセンターの構成は次のようなものです。
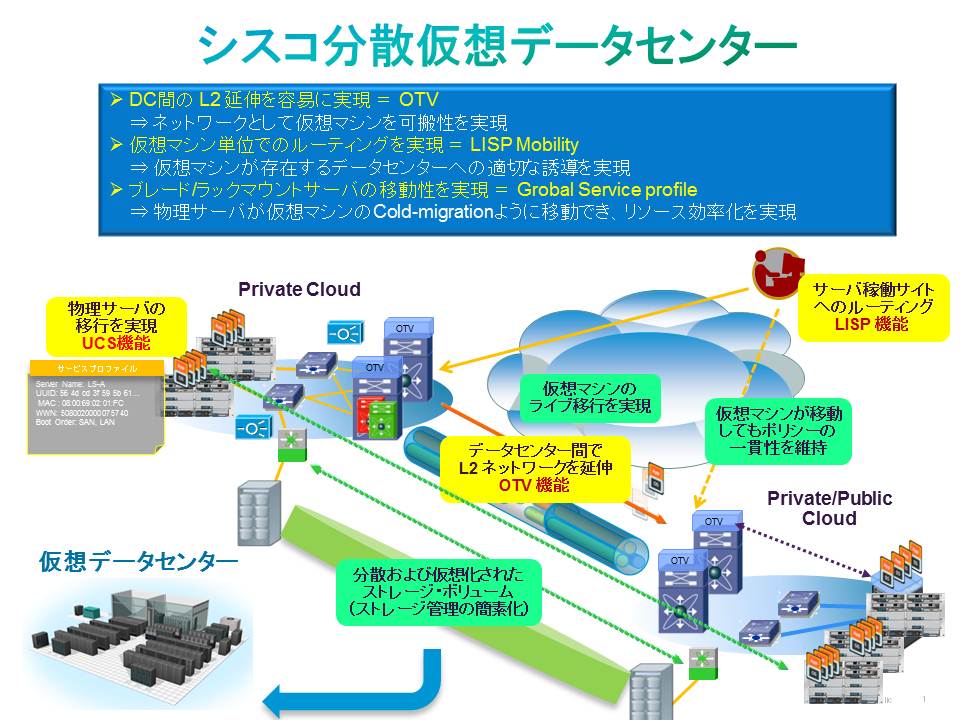
ポイントになるのは、データセンター間を L2 接続するための L2 延伸技術「OTV」(Overlay Transport Virtualization)と、仮想マシンがどこに移動してもルーティング可能にするルーティング プロトコル「LISP」(Locator/Identifier Separation Protocol)、物理サーバの移動性を実現する「Global Service Profile」の3つの技術です。
OTV や FabricPath による効率的な L2 延伸
データセンター間で仮想マシンを稼働させたまま移動(ライブ マイグレーション)するには、L2 延伸してデータセンター同士を L2 接続しなければなりません。L2 接続は VMware をはじめとするハイパーバイザー ベンダーが必須としている条件だからです。L2 延伸にはいろいろな方式があります。もっともシンプルで低コストなのは L2TP を使用する方法です。ただし単純に L2TP 接続するだけだと、回線冗長化によってループが発生します。ループが生じないように STP を使うと、せっかく冗長化した回線がアクティブ/スタンバイ構成になって高価な WAN 回線を十分に生かせません。また、MAC アドレス学習のためにブロードキャストを行う「フラッディング」によって大量のトラフィックが WAN 回線に流れる問題もあります。
安全でループフリーな L2 延伸のためにシスコが開発した技術が OTV です。OTV では L2TP と同様にイーサネット フレームを IP カプセル化(MAC in IP)して送受信します。しかし L2TP とは違ってマルチパス化やループ防止機能付きの透過的マルチホーミングといった機能を備えています。また、OTV 対応スイッチ同士が MAC アドレス情報を独自の制御プロトコルでやり取りするためフラッディングが生じません。そのため WAN 回線を効率的に利用できます。イーサネットと IP を組み合わせた技術のため習熟も容易です。すでに Cisco Nexus 7000 シリーズのスイッチなどが OTV に対応しています。
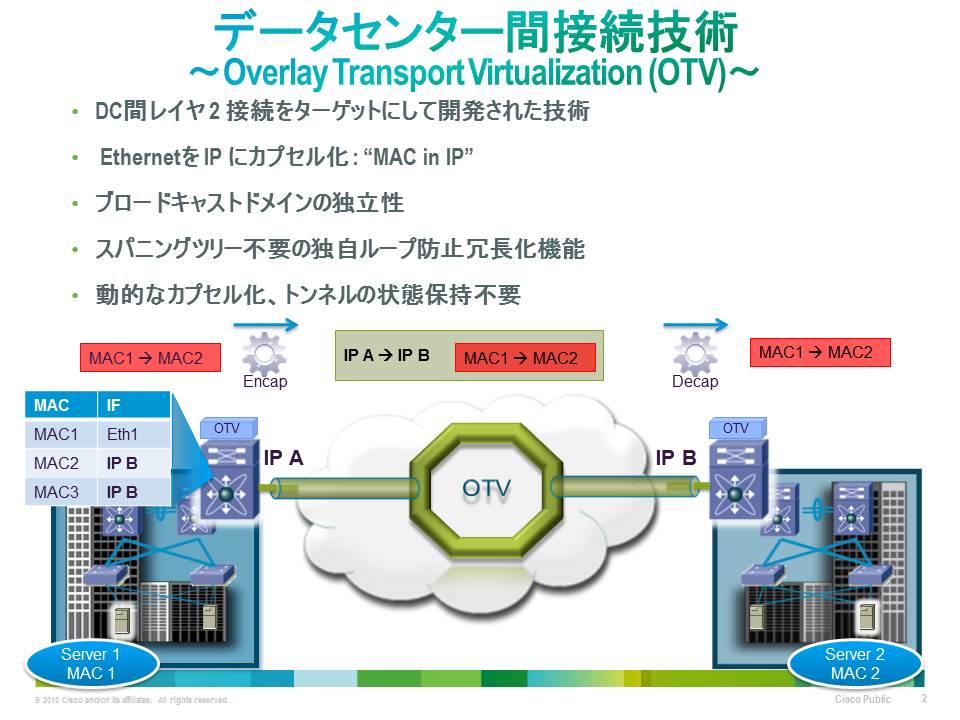
ただし OTV には弱点もあります。それは管理できる MAC アドレスの上限が 1万6000個と少ないことです。現在上限を 2万4000に増やす改良が進められていますが、複数のデータセンターを一体運用する分散仮想データセンターでの適用には、これでもまだ心許ない数字です。そのため筆者やシスコ日本法人では、収容する機器数が多いお客様に「FabricPath」という別の技術を提案することがあります。
FabricPath はデータセンター内部での STP に置き換わる技術として開発された L2 ルーティング技術です。OTV のようにループフリーですが、プロトコル上のMACアドレス数上限はなく、スイッチなどのハードウエアが許容するまでの MAC アドレスを収容できます。たとえば、Cisco Nexus 7000 を使うと 12万8000まで収容できます。さらに FabricPath には「Conversational MAC Learning」という、双方向通信の場合だけ MAC を学習するという MAC テーブル節約のための機能が実装されていて、MAC アドレスの収容能力は OTV とは文字通り桁違いです。ただ、FabricPath の経路選択方式にはやや癖があり、不用意に使用すると不適切な冗長経路を選択することがあります。これはデータセンター間接続の場合には 数10〜数100kmも迂回してデータが届くことを意味し、場合によってはサービスに悪影響を及ぼします。そのため FabricPath は一般的にはデータセンター内部で使用する技術と位置付けられています。しかし、3〜4 拠点接続のレベルであれば工夫次第で問題を避けることができますので、案件次第では十分に活用できると筆者は考えていますし、導入事例もすでに存在しています。
仮想マシン移動時にIPアドレスを変えない
仮想マシンのマイグレーションやレプリケーションの際に問題になるのが、IP アドレス情報を自分で抱え込んでいる「IP 埋め込み型」アプリケーションです。移動後や複製後に仮想マシンに割り当てる IP アドレスを変更しても、IP 埋め込み型アプリケーションが持つ IP 情報は変更されず、手動で切り替えなければサービスを正しく提供できません。手動作業が必要ということは切り替えに時間がかかることを意味しますし、緊急時の作業などではミスが発生する恐れも高くなります。お客様への聞き取り調査によると、こうした IP 埋め込み型アプリケーションは次第に増えつつあります。半分とはいかないまでも 3 割ぐらいのアプリケーションがIP埋め込み型であることは珍しくありません。そのため、仮想マシンの IP はできるだけ変えない方が良いのです。シスコでは、仮想マシンがどこに移動しても IP アドレスを変えずに済むための技術開発を進めています。
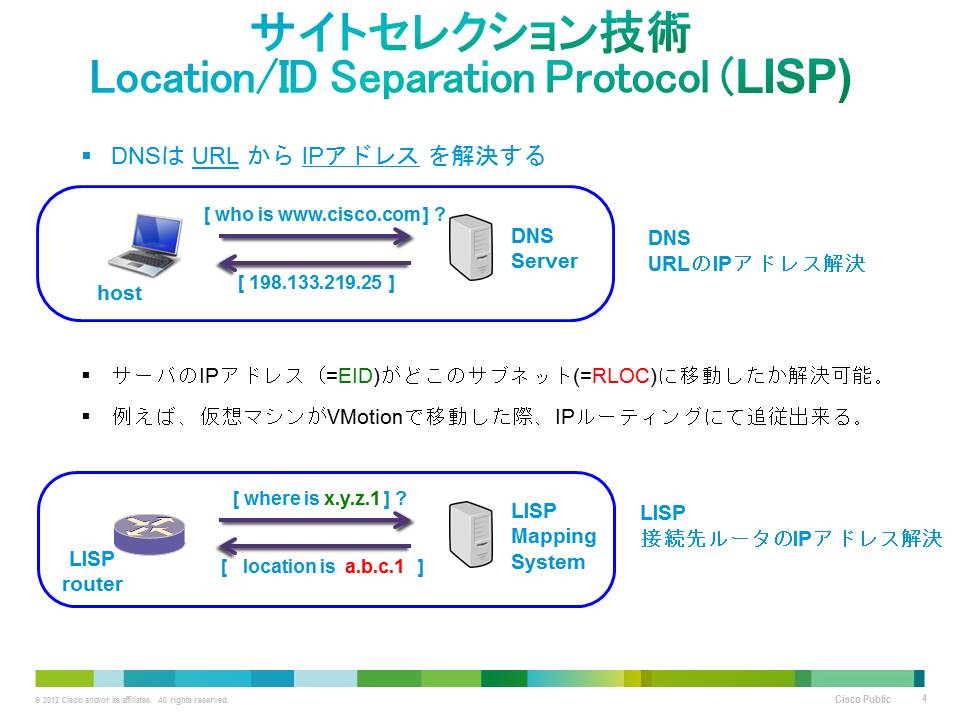
そもそも、なぜ、仮想マシンの位置が変わると IP アドレスを変更しないといけないのでしょうか。それは IP アドレスにはそれ自体に、ネットワーク アドレスやプレフィックスと呼ばれるネットワーク内の位置を示す情報が含まれているからです。そのため、例えばサブネットが変われば、IP アドレスも変えざるを得ません。実際のネットワーク位置と乖離した IP アドレスを付けてしまうとルーティングに問題が生じて正しく通信できなくなります。これを逆に考えると、IP アドレスと位置情報の対応を DB に格納し、ルーティングの際にその DB から IP アドレスに対応する位置情報を取り出す仕組みさえ用意すれば、IP アドレスそのものに含まれる位置情報は使わなくても正しくデータを配送できることが分かります。つまり「IP のモビリティ化」を実現できるわけです。この考えに基づいてシスコが中心になって開発・標準化を進めているのが、LISP というルーティング プロトコルです。
LISP では、DNS のような仕組みで IP アドレスに対応する位置情報を割り出します。DNS サーバに相当するマップ サーバに、IP アドレスに対応する位置情報を格納しておき、配送時にはマップ サーバに問い合わせることで一次配送先となる位置情報(仮想マシンが存在するデータセンターのエッジ ルータまたはコア スイッチのグローバル IP アドレスなど)を割り出します。この一次配送先情報を宛先に設定した IP ヘッダーを元の IP パケットに付加することで、IP アドレスがどこにあっても正しいルーティングを実現するのです。マップ サーバへの情報登録は、仮想マシンの移動などを検知した LISP 対応スイッチなどが実施します。
LISP の利用には既存のネットワークをそれほど変える必要はありません。まず必要なのは出入口となるエッジ ルータ(WAN ルータ)を LISP 対応のものに変更すること。シスコでは、Cisco ISR 800 シリーズのような小さな LISP 対応ルータを販売していますから、変更コストもそれほど高くありません。それに加えて、仮想マシンの移動検出と LISP マップ サーバ登録機能を持つ Cisco Nexus のようなスイッチ、そして LISP マップ サーバを稼働できる Cisco ASR ルータや Nexus 7000 などのスイッチがあれば十分です。LISP は IETF で一部標準化が終わっており、シスコ以外のベンダーからも対応製品が今後出てくると予想されます。そうなると LISP 対応はより手軽になるでしょう。シスコでは、x86 サーバのような汎用サーバで LISP マップサーバを稼働できるような OS も現在研究中です。
物理サーバを「移動可能」にする Cisco UCS Manager
データセンター内、あるいはデータセンター間をシームレスに仮想マシンが移動できるようになったとしてもそれだけでは不十分です。仮想マシン上で稼働させるソフトウェアには、ハードウェア情報に紐付いたライセンス体系を採用するものがあるからです。たとえば SAP は、サーバのシャーシに割り当てられた UUID を基にライセンスを発行しています。仮想マシンの移動によってこうしたハードウェア情報が変わってしまうと、こうしたソフトのライセンス費用が嵩むことになります。
Cisco UCS シリーズは、MAC アドレスや FC の WW ネーム、シャーシの UUID、BIOS やブート ローダー設定といったハードウェア固有の情報を「UCS サービス プロファイル」としてハードウェアから分離して管理できます。UCS サービス プロファイル情報を Cisco UCS Manager で一元管理し、各プロファイル情報を任意の UCS サーバにダイナミックに割り当てることができるのです。仮想マシンが稼働するハードウェアが変わっても、元のプロファイル情報を適用すれば、前述のようなライセンス問題は発生しません。また、各種のハードウェア設定も引き継げますから管理コストも削減できます。

この UCS サービス プロファイルの管理・割り当ては、従来、データセンター内部でしか実施できませんでした。しかしシスコでは、データセンターをまたがった管理・割り当てを可能にする「グローバル サービス プロファイル」という技術を開発し、2013年 6月頃から順次製品に盛り込んでいく予定です。これによって、データセンターが変わっても同じサーバをベアメタルで瞬時に立ち上げられるようになります。定期メンテナンスなどで、あるデータセンターが停止するような場合でも、すぐに別のデータセンターで必要なサーバを用意できます。
今回は、私たちが考える分散仮想データセンターのあるべき姿と、その主要な構成技術について紹介しました。
分散仮想データセンターの構成方式は、ここで紹介したもの以外にもいくつかあります。特に L2 延伸に OpenFlow などの SDN 技術を活用する方式が注目されています。しかし筆者は、大多数のネットワーク管理者にとっては、シスコが提案する方式の方がメリットが多いと考えています。OpenFlow/SDN は、プログラム次第で自由にネットワークを構成できる柔軟性が高い技術です。シスコでも OpenFlow コントローラの開発や、SDN 戦略である「Cisco Open Networking Environment(Cisco ONE)」を進めていますし、活用次第では非常に効果的な技術なのも確かです。
ただ、OpenFlow/SDN のメリットを十分発揮できるのは、「フロー制御」という新しい視点での設定やプログラミングに精通し、新しいネットワークアーキテクチャを設計できる人に限られるように思えます。「OpenFlow/SDNで初めて実現できた」とされることが、実は車輪の再発明で、既存のネットワーク装置で十分実現できることだったりすることも多数目にしてきました。一方、シスコが提案する OTV や FabricPath は、既存のネットワーク技術者にとって習熟・理解が容易な技術で、また、その機能は「完成品」としてネットワーク製品にすでに実装済みです。新たにプログラミングする必要はありませんし、設定を加えるだけで機能します。少なくとも分散仮想データセンターの構築という目的には、これで十分ではないかと筆者は考えています。
最後にシスコ本社の社員が作成した「LISP の歌」を紹介して、本エントリの締めくくりとさせていただきます。LISP の動作や目的を良く表現できていると LISP 技術者に評判の楽しい歌です。是非聴いてみてください。
Authors
2 コメント
I can’t hear anything over the sound of how awseome this article is.
That kind of thinking shows you’re an eexprt