
Maparea fully shared a bufferului pe switch-uri, o inovație marca Cisco Silicon One
6 min read
Una din axiomele rețelisticii spune că eficiența rețelei este strict și direct influențată de cea a switch-urilor incluse. La rândul ei, performanța switch-urilor depinde de sistemul de buffering, respectiv de dimensiunea buffer-ului utilizat pentru a face față congestiei traficului din rețea.
Pentru a avea o imagine mai clară, haideți să intrăm puțin în „anatomia“ unui sistem de buffering.
Dimensiunea optimă a buffer-ului este dictată de:
- Tiparele de trafic, care sunt determinate de aplicațiile care rulează în rețea. Aplicațiile moderne – precum cele de stocare distribuită, căutare etc. – creează tipare care generează supraîncărcări la nivel de switch. Să luăm ca exemplu o interogare de căutare: sarcina de extragere a datelor relevante este distribuită către mai multe servere din rețea. Când fiecare mașină finalizează căutarea, rezultatele obținute sunt trimise înapoi, ceea ce duce la apariția unei creșteri de trafic către serverul care a inițiat căutarea. Atunci când traficul TCP depășește capacitatea buffer-ului switch-ului Ethernet, își face apariția fenomenul de Incast care crește întârzierea în recepționarea pachetelor de date și scade throughput-ul la nivel de aplicație sub lățimea de bandă a conexiunii disponibile.
- Round-Trip Time (RTT) reprezintă timpul necesar unui pachet de date pentru a parcurge traseul de la sursa de trafic la destinație și înapoi. Este un parametru important, pentru că determină în mod direct cantitatea de date pe care o sursă de trafic o poate trimite în rețea înainte de a primi confirmarea, necesară pentru ca algoritmii de evitare a congestiilor de trafic să funcționeze și pentru a garanta livrarea pachetelor. De exemplu, un client atașat unei rețele 10 GbE printr-o conexiune cu un RTT de 16us are permisiunea de a trimite un pachet de date de cel puțin 1,6 Mb (16 us x 100 Gbps) înainte de a primi confirmarea.
În protocolul TCP, acest lucru este definit prin parametrul specific „Congestion Window“ (CWND), care determină câte pachete pot fi trimise o dată – cu cât este mai largă „fereastra“, cu atât este mai mare throughput-ul.
În mod ideal, buffer-ul unui switch ar trebui să fie îndeajuns de mare pentru a putea acoperi suma „ferestrelor“ tuturor fluxurilor de date care trec prin el. Astfel, am avea garanția că, în cazul apariției unui fenomen de Incast, acesta nu va duce la o supraîncărcare a buffer-ului, respectiv nu ne vom confrunta cu riscul pierderii de pachete.
În cazul routerelor Internet, regula e simplă, fiecare port având nevoie de un buffer calculat astfel: valoarea medie RTT x rata de transport a respectivului port.
În centrele de date, situația diferă. Astfel, în timp ce un router Internet poate gestiona, de exemplu, 10.000 de fluxuri printr-un singur port, cu cea mai mare a lățimii de bandă distribuită în 1.000 de fluxuri, în cazul unui switch dintr-un Data Center cea mai mare parte a lățimii de bandă este distribuită în câteva fluxuri cu lățime mare, regula fiind că un port are nevoie de întreaga lățime de bandă a switch-ului, nu doar a portului. Prin urmare, formula este: valoarea medie RTT x lățimea de bandă a switch-ului.
În practică însă, nu se prea întâmplă ca întreg traficul de pe un switch să fie concentrat pe un singur port.
Pentru a înțelege cum funcționează RTT într-o rețea, haideți să apelăm la un scenariu concret, ținând cont de faptul că valoarea acestui parametru este dată de timpul necesar unui pachet de date pentru a parcurge rețeaua fizică de la sursă la destinație și înapoi, la care se adugă întârzierile introduse de switch-urile intermediare și de nodurile finale (adaptoarele de rețea și stiva software aferentă).
Acum să trecem la date concrete: pachetele de date se deplasează prin fibra optică cu aproximativ 5 microsecunde (μsec) per kilometru. Prin urmare, atunci când două host-uri dintr-un Data Center comunică între ele printr-o rețea de fibră optică cu lungimea de 500 m, valoarea de start a RTT este de 5 μsec.
Întârzierea introdusă de switch este compusă din întârzierea de procesare a instrucțiunilor („Pipeline delay“) și cea introdusă de buffer („Buffering delay“). Teoretic, în cazul switch-urilor performante, valoarea „Pipeline delay“ este de sub 1 μsec. Atenție însă! – această valoare este calculată pentru un model ideal, în care un singur pachet trece prin switch. În practică, un switch suportă simultan mai multe pachete, provenind din surse diferite, prin urmare este necesar un buffer minimal. Dar chiar și un buffer mic, de 10KB, generează o întârziere de 1 μsec pentru o conexiune de 100 Gbps.
În fine, ajungem la adaptoarele de rețea, unde chiar și cele mai performate echipamente introduc o latență de cel puțin 2 μsec, dar adesea mai mult de atât.
Dacă tragem linie și adunăm, rezultă că, într-un centru de date mic, cu o rețea de fibră de 500 m și 3 switch-uri, vom avea o valoare RTT minimă de 16 μsec.
Din nou, însă, se impune precizarea că acesta este un model ideal și că, în realitate, dimensiunea rețelelor fizice este substanțial mai mare, iar echipamentele de rețea – considerabil mai multe. Prin urmare și valoarea RTT este mult mai mare.
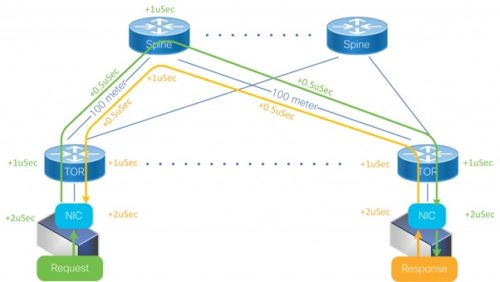
EXPLICAȚIE FOTO: O rețea Data Center simplă cu un RTT minim
După cum se poate vedea mai sus, pentru a suporta un RTT de 32 μsec pe un switch de 25.6 Tbps avem nevoie de un buffer de 100 MB. Teoretic, cei 100 MB reprezintă atât capacitatea buffer-ului total necesar pentru întregul switch, cât și buffer-ul maxim de care poate beneficia orice port. În cazul în care tot traficul de intrare vizează un singur port – vezi fenomenul de Incast amintit mai sus – este folosit întregul buffer pentru a absorbi excedentul. În cazul mult mai frecvent în care fenomenul de congestie afectează mai multe porturi, buffer-ul se distribuie proporțional între acestea, în funcție de nivelul de supraîncărcare.
Switch-urile de nouă generație, care au buffer-ul integrat la nivel de core („On-die buffering“), permit alocarea dinamică a resurselor între porturi, însă adesea există restricții ale modului în care distribuția poate fi realizată.
Metodele actuale de mapare a buffer-ului, în funcție de nivel și orientare, sunt următoarele:
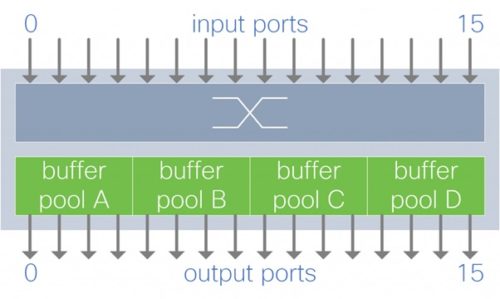
EXPLICAȚIE FOTO: Buffer mapat per grupuri de porturi de ieșire
Fiecare alocare de buffer gestionează traficul destinat unui subset de porturi de ieșire.

EXPLICAȚIE FOTO: Buffer mapat per grupuri de porturi de intrare
Fiecare alocare de buffer preia trafic de la un subset de porturi de intrare.
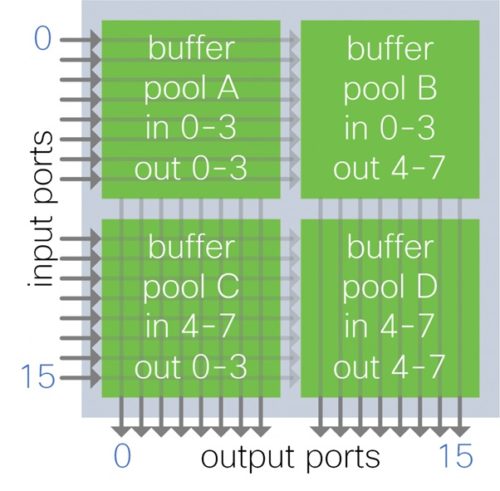
EXPLICAȚIE FOTO: Buffer mapat per grupuri de porturi de intrare-ieșire
Fiecare alocare de buffer preia traficul de la un subset de porturi de intrare pentru un subset de porturi de ieșire.
Toate cele trei metode menționate au însă restricții ale modului în care se realizează partajarea resurselor, iar dimensiunea buffer-ului alocat pentru preluarea supraîncărcării la nivel de port este impredictibilă, depinzând de tiparul traficului.
În cazul buffer-ului mapat per grupuri de porturi de ieșire, eficiența metodei este limitată de dimensiunea fiecărei alocări. De exemplu, într-o arhitectură de tipul „Output buffer“ cu patru alocări, fiecare port de ieșire poate beneficia de cel mult 25% din totalul memoriei disponibile. O asemenea restricție face ca evoluția buffer-ului în cazul apariției fenomenelor de Incast să fie total imprevizibilă.
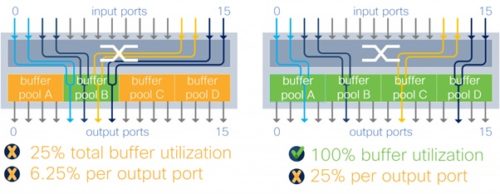
EXPLICAȚIE FOTO: Switch cu Output buffer în congestie (4×2:1)
În cazul buffer-ului mapat per grupuri de porturi de intrare, nivelul de absorbție a vârfurilor de excedent depinde de tiparul traficului. De exemplu, în cazul unui tipar de supraîncărcare în proporție de 4:1 pe un switch al cărui buffer total este împărțit în patru alocări, capacitatea de absorbție variază între 25 și 100% din totalul memoriei.
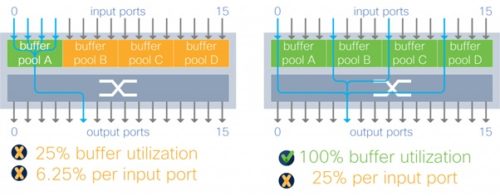
EXPLICAȚIE FOTO: Switch cu Input buffer în congestie (4:1)
În cazul buffer-ului mapat per grupuri de porturi de intrare-ieșire, în cazul unei arhitecturi cu patru alocări, un port este restricționat din start la jumătate din capacitatea totală a buffer-ului. Această arhitectură limitează și mai mult utilizarea bufferului în funcție de tiparele de trafic – în exemplul de mai jos un port de ieșire poate utiliza doar 12,5% din capacitatea buffer-ului în loc de 50%.
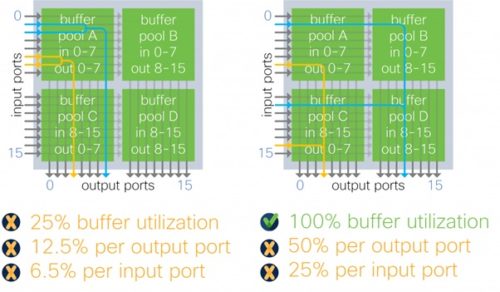
EXPLICAȚIE FOTO: Switch cu Input-Output buffer în congestie (2×2:1)
Cisco Silicon One elimină toate aceste limitări, permițând maparea totală a buffer-ului prin modelul de arhitectură „Fully shared“, prin care toate alocările din buffer sunt disponibile și pot fi distribuite dinamic pe orice port. Eliminarea restricțiilor eficientizează și optimizează utilizarea memoriei disponibile, asigură predictibilitate asupra modului în care evoluează buffer-ul și este independentă de tiparul de trafic.
În exemplele prezentate mai sus, arhitectura „Fully shared“ utilizată de switch-urile Cisco dotate cu Silicon One asigură o dimensiune a buffer-ului de cel puțin 4 ori mai mare decât ceea ce oferă alte echipamente. Aceasta înseamă că, de exemplu, un switch de 25.6 Tbps cu un buffer total de până la 100 MB poate asigura per port exact 100 MB. Pentru a obține o performanță similară, un switch cu o arhitectură de tipul „Partially shared“ cu patru alocări de buffer necesită o capacitate de memorie de patru ori mai mare.
Câștigurile de eficiență obținute prin maparea fully shared a buffer-ului se extind și în cazul folosirii tehnologiei Remote Direct Memory Access (RDMA), care utilizează protocolul User Datagram (UDP) pentru a preveni pierderea de pachete. UDP nu folosește un mecanism de feedback pentru semnalizarea apariției congestiilor (ca în cazul TCP) și se bazează pe metoda Priority-based Flow Control (PFC) pentru a controla fluxurile și a preveni pierderea pachetelor în fazele de congestie. Dezavantajul major al metodei PFC – reprezentat de faptul că poate stopa anumite fluxuri și genera congestii prin blocarea porturilor neafiliate – este atenuat prin arhitectura „Fully shared“ utilizată de Cisco Silicon One. Logica e simplă: dimensiunea mare a buffer-ului disponibil asigură o capacitate mai mare de gestionare a congestiilor, prin urmare se reduce drastic nevoia de declanșare a mecanismelor PFC.
Dacă doriți să aflați mai multe detalii despre avantajele arhitecturii „Fully shared“ utilizată de switch-urile Cisco dotate cu Silicon One vă invităm să ne contactați la solutiicisco@cisco.com
Authors