
Cisco Unified Computing System- O abordare diferită a provocărilor din domeniul Supercomputerelor
5 min read
Domeniul supercomputerelor este unul fascinant. Aceste calculatoare de dimensiunea unor stadioane de fotbal uneori sunt folosite de către cercetători din toată lumea pentru a afla răspunsul la întrebări sau probleme extrem de complexe: simularea unor tipare meteorologice complexe şi prezicerea furtunilor tropicale, simularea modului în care se modifică aerodinamică unui avion atunci când una dintre componentele acestuia îşi schimbă forma.
În ultimii ani, de exemplu, supercomputerele încearcă să modeleze dinamică moleculară (simularea şi analiza modului în care se deplasează atomii şi moleculele).
Pentru a putea analiza asemenea probleme este nevoie de calcule matematice extrem de complexe şi, în consecinţă, de o putere de procesare foarte mare. Niciun procesor din ziua de azi nu este cababil să realizeze singur calcule la această scară. De aceea, o abordare frecventă este utilizarea de algoritmi de calcul paralel care împart o problema complexă în multe sub-probleme mai mici. În consecinţă, supercomputerele sunt construite pentru a se mula pe această abordare şi sunt de fapt sute sau chiar mii de servere mai mici (denumite noduri) conectate între ele într-un cluster prin legături de mare viteză şi având acces direct la o memorie distribuită.
Într-un asemenea sistem paralelizat masiv viteza şi flexibilitatea legăturilor între nodurile de procesare este extrem de importantă. Această problemă este tratată în general prin utilizarea de tehnologii de interconectare speciale (Infiniband esteuna din tehnologiile de interconectare extrem de populară în HPC). Infiniband foloseşte adaptoare de reţea speciale instalate în servere precum şi echipamente de comunicaţie specifice (switch-uri Infiniband). Totuşi, o mare parte din supercomputerele extrem de puternice folosesc şi tehnologii standard de interconectare (mai bine de 200 din supercomputerele din Top 500 la nivel global folosesc drept tehnologie de interconectare reţele Ethernet 1/10 Gbit). Marele avantaj al folosirii tehnologiilor standard este cel legat de accesibilitatea tehnologiei (atât din perspectiva preţului, cât şi din perspectiva administrării şi utilizării sistemului).
Indiferent de tehnologia folosită pentru interconectarea nodurilor, în momentul în care un specialist sau pasionat de domeniul HPC (High Performance Computing) este întrebat care este principala provocare în construirea unor supercomputere mai performate răspunsul va fi invariabil acelaşi: latenţa în comunicaţie între nodurile care alcătuiesc cluster-ul.
Plecând de la această problemă, cercetătorii Cisco au realizat o analiză pentru a identifica modalităţile prin care pot îmbunătăţi latenţa în sistemele de tip HPC care folosesc drept tehnologie de interconectare standardul Ethernet. Rezultatele studiului sunt extrem de interesante: o componentă extrem de importantă a latenţei percepute de aplicaţie la comunicarea între 2 două noduri dintr-un sistem de tip HPC apare în interiorul serverului şi este cauzată de întârzierile apărute la procesarea datelor de către stiva TCP/IP a kernel-ului sistemului de operare. În urma studiului a rezultat că aproximativ 85% din latenţă end-to-end este cauzată de această traversare, restul latenţei fiind cauzată de latenţa plăcii de reţea, latenţa switch-urilor din reţea etc.
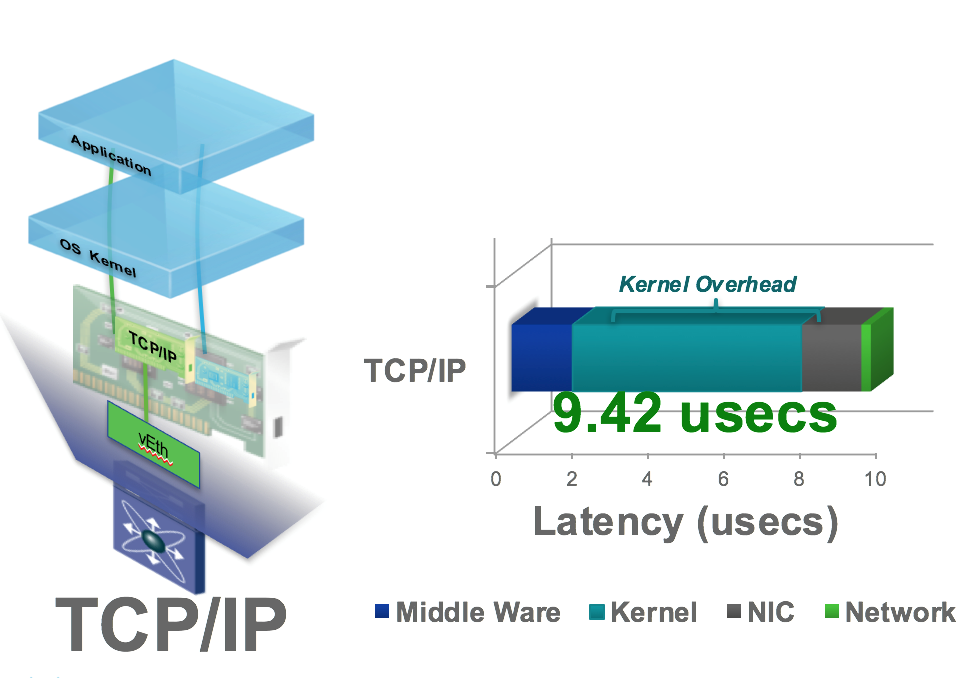
O concluzie evidentă a fost că reducerea acestei latenţe din interiorul serverului ar avea ca rezultat imediat o imbunătățire dramatică a latenţei între nodurile sistemului şi deci la o îmbunătăţire a performanţelor sistemului în ansamblu.
Dar această problemă a întârzierilor cauzate de traversarea datelor prin sistemul de operare părea cumva familiară, aşa că inginerii Cisco s-au întrebat dacă şi unde au mai văzut o problema similară. Răspunsul a venit foarte repede: o problema similară este întâlnită în sistemele IT tradiţionale atunci când se utilizează tehnologii de virtualizare a serverelor.
Şi în cazul virtualizării de servere un proces, o “aplicaţie” (o maşină virtuală) trebuie să comunice printr-o reţea cu o altă aplicaţie, datele “traversând” diferitele componente ale sistemului de operare (în cazul aceasta un hypervizor) pentru a putea ajunge la conexiunea fizică de reţea şi în final la destinaţie prin reţea. În domeniul virtualizării aceste probleme au fost rezolvate de câţiva ani prin dezvoltarea unor tehnologii hardware (pentru curioşi: Intel VT-d, SR-IOV) care permit maşinilor virtuale că în anumite situaţii, când performanţa şi latența sunt importante, să ocolească hypervizorul şi să primească acces direct la resursele hardware ale server-ului gazdă. Ce este şi mai interesant este că aceste tehnologii nu sunt disponibile numai în lumea virtualizării, ele sunt accesibile şi sistemelor de operare de tip Linux, cele mai populare sisteme de operare pentru supercomputer.
O dată identificată această rezolvare elegantă a problemei latenţei în comunicaţii apărută în interiorul serverelor, specialiştii Cisco s-au gândit cum ar putea utiliza aceste rezultate în domeniul supercomputerelor. Cisco produce începând din 2009 una dintre cele mai populare game de servere din lume, la introducerea lor pe piaţă aceste sisteme au revoluţionat intreaga industrie prin inovaţiile aduse precum şi prin abordarea diferită. În mare parte succesul serverelor Cisco UCS s-a datorat abordării inovatoare prin care acest sistem îmbrăţişează virtualizarea şi problemele pe care aceasta le aduce într-un centru de date (fie că ne referim la managementul serverelor, schimbarea tiparelor de trafic de date pe reţea, unificarea diferitelor tipuri de trafic şi aşa mai departe). Pentru UCS Cisco a dezvoltat un adaptor de reţea unificat (converged network adapter) denumit Cisco VIC (Virtual Interface Card), care este compatibil cu tehnologiile de virtualizare amintite mai sus şi care este extrem de efficient şi peroformant atunci când este folosit în medii virtualizate.
Îmbinând tehnologia deja dezvoltată de Cisco pentru sistemele server UCS (în mod particular adaptorul Cisco VIC de generaţie 2 sau 3) cu rezultatele cercetării în domeniul supercomputerelor despre care aminteam mai sus Cisco propune o abordare inedită şi revoluţionară a problemei latenței în domeniul supercomputerelor: tehnologia usNIC (User Space Network Interface Card). Această este o tehnologie care permite transformarea oricărui adaptor convergent Cisco VIC instalat într-un server UCS într-un adaptor cu latentă extrem de mică, cu aplicaţii în domeniul supercomputerelor.
Soluţia propusă este una software, care pune la treabă capabilităţile adaptoarelor de reţea din serverele Cisco UCS. Prin intermediul unui firmware specific instalat pe plăcile Cisco VIC şi folosind o suită de drivere şi biblioteci pentru sistemul de operare Linux soluţia permite unei aplicaţii de tip HPC să ocolească stiva TCP/IP din sistemul de operare şi să comunice în mod direct cu adaptorul de reţea pentru a transmite şi primi date. Mai mult, toate componentele software sunt oferite în system OpenSource de către Cisco.
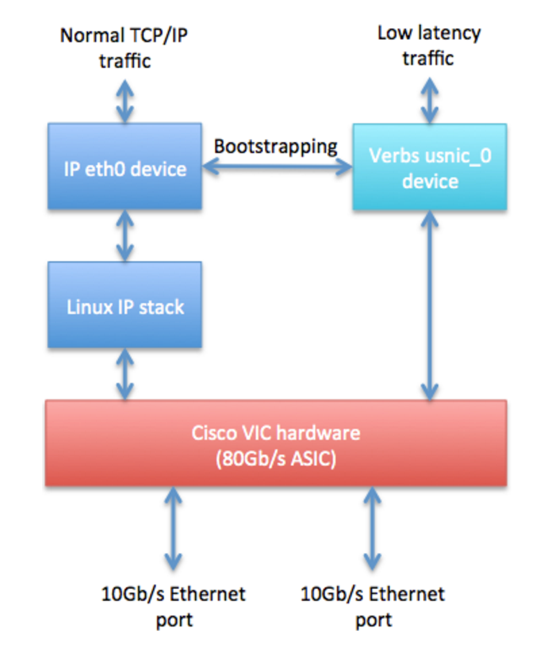
Soluţia este cu atât mai interesantă având în vedere că permite ca pentru acelaşi adaptor fizic să fie prezentate către sistemul de operare Linux atât interfeţe de reţea “normale” cât şi interfeţe de reţea cu latenţă scăzută usNIC. În felul acesta se poate realiza o unificare a traficului într-un cluster HPC, atât traficul de date între nodurile clusterului, cât şi celelalte tipuri de traffic (management hardware, management system de operare, etc), vor folosi aceeaşi conexiune fizică de mare viteză.
Dacă îmbinăm această soluţie elegantă şi extrem de eficientă din perspectiva costurilor (aşa cum spuneam, software-ul dezvoltat este pus la dispoziţia utilizatorilor de sisteme server Cisco UCS în regim OpenSource) cu noile standarde Ethernet (40 Gbit Ethernet) rezultă o soluţie pentru clustere HPC cu performanţe excelente şi accesibile din perspectiva preţului. La aceste performanţe adăugăm şi simplitatea în administrarea platformelor de calcul Cisco UCS şi obţinem o soluţie extrem de interesantă. Rezultatul: primele clustere de supercomputere folosind tehnologie Cisco, inclusiv tehnologia usNIC descrisă mai sus, au fost deja achiziţionate de către mai multe universităţi din Statele Unite ale Americii şi sunt în present utilizate de către cercetătorii respectivelor universităţi.
Cisco propune pentru sisteme de tip Supercomputer o arhitectură simplă, bazată pe standarde folosite la scară largă în industria IT şi eficienţă din perspectiva costurilor precum şi a simplităţii în utilizare:
- Servere UCS M4 folosind procesoare Intel din seria E5-2600 v4 şi co-procesoare grafice Nvidia Tesla.
- Adaptoare de reţea cisco VIC de generaţia 3 care oferă două port-uri 40 Gbit Ethernet şi support pentru tehnologia usNIC.
- Switch-uri Cisco Nexus 9000 cu latenţă scăzută şi care folosesc standardul 40 Gbit Ethernet.
- Trafic unificat peste o singură conexiune fizică între nodurile sistemului.
- Suport pentru majoritatea uneltelor de management pentru clustere de Supercomputere.
Abordarea diferită în rezolvarea unor probleme este o trăsătură deja prezentă în ADN-ul soluţiilor Cisco pentru centre de date, şi în special a sistemelor de calcul Cisco UCS. Prin dezvoltarea acestei tehnologii Cisco demonstrează încă o dată că UCS este o platformă de servere revoluţionară cu aplicaţii atât în domeniul sistemelor IT tradiţionale cât şi în domeniul supercomputerelor. Mai multe informaţii despre portofoliul Cisco pentru centrele de date sunt disponibile aici.