
Hvor mange ingeniører trenger man for å finne skadelig programvare i kryptert trafikk? I Cisco sitt tilfelle, er kjernen i maskinlærings-teamet som muliggjør kryptert trafikk analyse (Encrypted Traffic Analytics – ETA) ca. 50 ingeniører. Teamet består av sikkerhetsforskere og forskere på kunstig intelligens basert i Europa og USA. Målet er forholdsvis enkelt å beskrive, men langt vanskeligere å oppnå. De sørger for at Cisco sine kunder blir beskyttet mot skadelig programvare til tross for at en stor del av trafikken nå er kryptert. Samtidig ser vi også at en stor andel av den skadelige trafikken har tatt i bruk TLS, Tor eller andre krypterte protokoller.
Vårt svar er basert på ETA-telemetri levert av et voksende utvalg av Cisco rutere og switcher. ETA-telemetri er konseptuelt veldig enkelt. I tillegg til den normale Netflow-eksporten, produserer switchen eller ruteren ytterligere datafelt som legger til informasjon for å spesifikt adressere våre målrettede brukersenarioer. Den opprinnelige datapakken (IDP) inneholder nyttelasten fra den første pakken av hver enkelt strøm. For TLS, vil klient- og server-IDP inneholde klienten og serverens «hello’s», for HTTP vil den inneholde den første forespørselen og responsen. The Sequence of Packet Lengths and Times (SPLT) inneholder informasjon om størrelse og tidspunkt for forbindelsens initielle pakker. Denne informasjonen gjør at vi kan skille mellom ulike kategorier av kommunikasjon inne i TLS-tunnelen, for eksempel nettlesing, e-post nedlastinger, fil opplastinger, nedlastinger og annen type kommunikasjon. Netflow- og ETA-informasjonselementene blir behandlet lokalt av Stealthwatch-systemet, mens malware analysen blir gjort i Cisco-skyen.
Maskinlæring og AI er nøkkelen til ETA
Så, hvordan kan vi sikre noe vi ikke kan dekryptere og inspisere på innholdsnivå? Vårt svar er basert på en kombinasjon av moderne maskinlæring og automatisert kommunikasjonsanalyse utført i en global skala. ETA-malware-deteksjon er basert på Cognitive Threat Analytics (CTA), som er en skybasert adferdssdeteksjonsmotor.
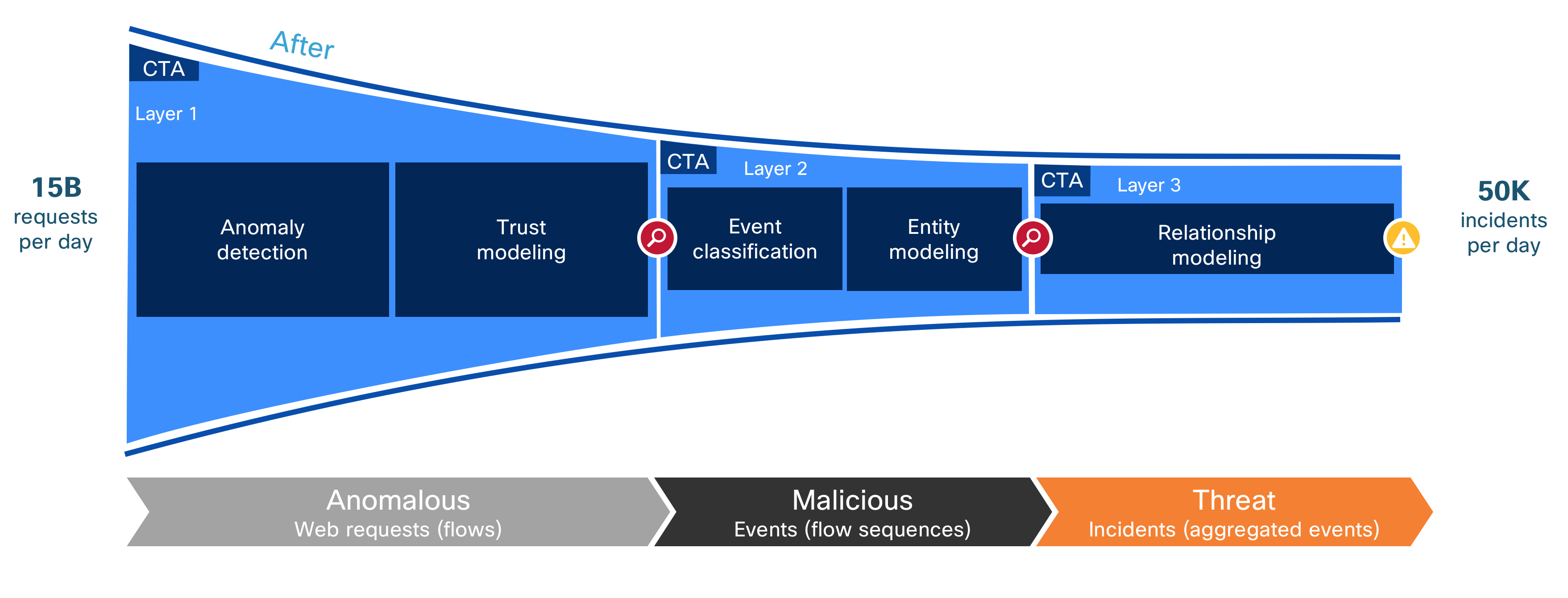
CTA mottar og behandler telemetridata fra Cisco klienter og returnerer en liste over klienter som med stor grad av sannsynlighet er infisert med skadelig kode. I tillegg får man en estimering av risiko, oversikt over skadelig programvare samt annen informasjon som er kritisk for senere etterforskning. CTA behandler daglig mer enn 15 milliarder Netflow forespørsler og proxy logger, i tillegg til dette mottar vi informasjon fra flere andre kanaler. Alle trafikkstrømmer og forespørsler tilskrives en bestemt kunde, og det meste av analysen og behandling er kundespesifikk. Dette gjør det mulig for oss å beskytte mot informasjonslekkasje som kan oppstå hvis vi skulle behandle adferdsdata på tvers av flere kunder.
Cognitive Threat Analytics
Det første trinnet i behandlingen er et oppførselsbasert anomali-deteksjonsfilter. Det er ikke basert på en enkelt algoritme, men sammensatt av omtrent 70 forskjellige algoritmer som modellerer ulike aspekter ved adferds relatert til individuelle klienter, bedriftsmønstre og samspillet mellom interne klienter og eksterne servere. For eksempel modellerer noen algoritmer aktiviteten til de enkelte enhetene i løpet av dagen, mens andre modeller konsentrerer seg om ukentlig, månedlig eller enda lengre perioder. Andre modeller er bygget for å estimere de forskjellige applikasjonene som brukes på hver klient for bestemte oppgaver, og for å identifisere eventuelle uventede uoverensstemmelser.
Noen av de mest avanserte oppførselsmodellene er spesifikke for ETA-kunder. De ETA dataspesifikke modellene baserer seg på metadata fra TLS og informasjonen fra SPLT-feltet. Disse dataelementene brukes for å bygge opp modellen av kryptografiske primitiver som brukes av programvaren på en gitt klient eller som blir valgt av en gitt server. ETA informasjonen gjør at Netflow produsert av ETA kompatible enheter ser ut som det som produseres av en proxy, dette muliggjør adferdssmodellering som ellers bare kunne brukes på proxy-logger og ikke på ren Netflow. Denne informasjonen kan videre korreleres med flere applikasjonslagprotokoller eksportert i IDP-informasjonselementet, for eksempel HTTP, DNS, FTP etc.
Informasjonen vi trekker ut fra ETA hjelper oss spesielt til å bygge svært detaljerte modeller av oppførselen for spesielt server siden av kommunikasjonen. I motsetning til de normale adferdsmodellene, bruker de Internett baserte server modellene all den globale informasjonen som er tilgjengelig for Cisco. Basert på denne informasjonen og disse modellene har vi mulighet til å kunne forutsi om en gitt server er i bruk nå, eller i fremtiden kan bli brukt i skadelig økosystem. Dette er ikke et kappløp rundt omdømme. Vi kartlegger og sporer helt legitime tjenester og muligheter som ofte brukes av malware forfattere, deretter vurderer vi risikoen knyttet til godartede servere som eventuelt kan utnyttes og misbrukes i fremtiden. Det faktum at servermodellene er konstruert (og automatisk verifisert) på en global skala gjør dem mindre følsomme for unnvikelses forsøk.
Hele poenget med det adferdsmodellerende laget er å filtrere bort de trafikkstrømmene som ikke inneholder trusler eller skadelige kode. Alle trafikk strømmer som har en lav anomali-score kan kasseres før ytterligere behandling. På dette punktet ser systemet på de resterende uregelmessige strømmene og forsøker å forklare deres eksistens og årsaken til deres avvik. Annonsering, brukersporing og noen medieoverføringer er svært ofte statistisk avvikende, noe som gjør at disse kategoriene kan identifiseres og fjernes før videre behandling. Deretter tar vi i bruk flere hundre «classifiers» for å kategorisere de resterende strømmene som enten skadelig eller mistenkelig.
Strømmene i den første kategorien kan umiddelbart klassifisere som skadelig. Maskinlæringsalgoritmene som tar denne avgjørelsen, er enten opplært til å identifisere generiske angrepsteknikker (feks. bruk av genererte domener eller botnet command & control), eller er opplært til å identifisere trafikkmønstre som er spesifikke for malware kategorier (f.eks. Adware, kryptominering, ransomware). En annen kategori av algoritmer identifiserer mønstrene som er spesifikke for individuelle trusselaktører som systemet har oppdaget tidligere. På generelt grunnlag kan man si at hvis noen allerede uregelmessige trafikkstrømmer detekteres av noen av disse spesifikke algoritmene, er det sterk nok indikasjon til at systemet vårt kan generere en alarm.
ETA data elementene er avgjørende, da det gir oss mulighet til å videreutvikle eksisterende algoritmer og gjør det mulig å designe ytterligere algoritmer som spesifikt retter seg mot malware´ens bruk av kryptografiske teknikker. Disse algoritmene kombinerer ETA-data, trafikkstrømsdata, klient adferds data og serverinformasjon. En av disse algoritmene er basert på den originale ETA proof-of-concept klassifiseringen [1], mens de andre utvider det nåværende settet av algoritmer inne i CTA.
SPLT and server adferd
Det viktigste spørsmålet er fortsatt: Hvordan klassifiserer vi en strøm som ikke åpenbart er skadelig eller legitim? Denne kategorien er mye større enn skadelige strømmer. Å klassifisere disse strømmene korrekt er kritisk fordi de inneholder en blanding av uvanlig, men likevel helt legitim oppførsel kombinert med ny malware adferd som ingen har sett tidligere. Generelt er en enkelt strøm eller en kortsiktig observasjon sjelden tilstrekkelig til å dømme denne klassen av skadelig programvare. Derfor bruker vi en kaskade av teknikker hvor vi grupperer strømmer inn i aktiviteter [2]. Hver aktivitet blir så individuelt klassifisert. Alle aktivitetene som oppstår på den aktuelle klienten blir da betraktet som en gruppe, og CTA systemet bestemmer om det er samlet inn nok bevis til å utløse et varsel. Observasjonsperioden kan variere dramatisk – noen slike hendelser utløses i løpet av minutter, mens andre kan ta timer til uker. Forsinkelsen avhenger åpenbart av hvor sofistikert malwaren er og omfanget av nettverksaktivitet.
Kombinasjonen av ulike kategorier av klassifiseringsalgoritmer er helt bevisst. De spesifikke klassifiseringsalgoritmene gjør det mulig for systemet å raskt kunne oppdage kjente angrep. De fleste spesifikke klassifiseringsalgoritmene annoterer også funnet med risikovurdering, trusselinformasjon og i mange tilfeller kan de aktuelle filer som kan finnes på den infiserte klienten, samt eventuell annen systemskade. De mer generiske og langsiktige klassifiseringsalgoritmene gir systemet muligheten til å finne ny malware samt skille den ut fra andre kjente angrep. Systemet begynner også å bygge nye adferdsmodeller som beskrevet nedenfor.
Global Synlighet
Det neste steget i behandlingen er ikke lenger kundespesifikt. CTA systemet konsoliderer hendelsene som er identifisert på tvers av alle kunder, noe som gjør at noen hendelser kan tilskrives kjente ondsinnede aktører. På bakgrunn av denne informasjonen er adferdssmodellene som representerer disse aktørens teknikker, taktikker og ressurser oppdatert. Adferdsene til hendelser som ikke kan tilskrives kjente aktører, blir krysskoblet med informasjon som kommer fra andre Cisco sikkerhetsprodukter som AMP og ThreatGrid. Denne foreløpige modellen kan da brukes for å skape en modell av en ny ondsinnet aktør. Disse modellene blir deretter gjort om til nye klassifiseringsalgoritmer som igjen blir brukt på dataene i klassifiseringsfasen.
CTA utnytter den globale intelligensen samlet på tvers av flere produkter som tilbys av Cisco. Spesielt lar denne korrelasjonen mellom data fra endepunkts baserte sikkerhetsprodukter som AMP og ThreatGrid sammen med data fra nettverksbaserte sikkerhetsprodukter, at Cisco kan spore skadelige kampanjer samt servergrupper som brukes av legitime applikasjoner i sann tid.
Mens overvåking av nettverksadferd av kjente og veletablerte legitime applikasjoner på endepunktene kan virke overflødig, er det faktisk avgjørende for effektiviteten til systemet. CTA har oversikt over legitime servere som vanligvis brukes av disse applikasjonene, samtidig lager vi adferds modeller av disse serverne og applikasjonene. Både servermodellene og applikasjons adferds modellene brukes da i ETA klassifiserings algoritmene for å forbedre presisjonen og redusere falske positiver.
Sporing av nettverksoppførselen til kjente malware familier gjør at vi kan opprette adferds modeller av ondsinnet oppførsel. En konsekvens av dette er at vi da kan oppdage endringer i oppførselen til aktuelle malware-familier raskt, og adferdss modellene kan oppdateres. Dette gjør det vanskeligere for trusselaktørene å unngå at de blir oppdaget. Dette gjør det også mulig å kontinuerlig forbedre klassifiseringsalgoritmene.
Globalt er vårt system basert på to hovedprinsipper. Det er bygget opp rundt en kaskade av hundrevis klassifiserings algoritmer, som gradvis analyserer dataene og deretter kasserer alt som er normalt. Dette gjør det mulig for oss å løse problemet med (base-rate) normalisering (siden malware bare utgjør en liten del av trafikken) samtidig som systemets evne til å oppdage ny malware opprettholdes. Det andre prinsippet er tilbakemelding. Kunnskapen som genereres av de mer komplekse klassifiseringsalgoritmene og delsystemer dypt inne i systemet, brukes til å kontinuerlig generere oppdaterte klassifiseringsalgoritmer og parametere for de tidlige stadiene i systemet. Oppdaterte klassifiseringsalgoritmer produserer så enda bedre data og informasjon og starter en selvforbedringssyklus.
Å finne malware i kryptert trafikk (eller til og med ikke-kryptert trafikk) er ikke noen enkel jobb, men det er en jobb vi tar seriøst og er lidenskapelig opptatt av. Det er ikke magi! Alt vi oppnår er resultatet av det harde arbeidet til et lidenskapelig og dedikert team. Våre ingeniører slipper 5 eller 6 nye versjoner av programvaren hver uke og sørger for at plattformen hele tiden kan motta, behandle og prosessere de enorme mengder med inngangsdata. Våre forskere utvikler kontinuerlig nye algoritmer for å finne enda mer malware. Våre sikkerhetsforskere er engasjert i en daglig kamp mot angriperne, dette for å sørge for at resultatene vi gir deg, er så fullstendige og konkrete som mulig.
[1] Blake Anderson, David McGrew; Machine Learning for Encrypted Malware Traffic Classification: Accounting for Noisy Labels and Non-Stationarity; KDD, 2017
[2] K Bartos, M Sofka, V Franc; Optimized Invariant Representation of Network Traffic for Detecting Unseen Malware Variants; USENIX Security Symposium, 2016
[3] M Grill, T Pevny; Learning combination of anomaly detectors for security domain; Computer Networks, Vol. 107, 2016