
시스코는 3월 31일(목) 서울 삼성동 그랜드 인터컨티넨탈 서울 파르나스에서 ‘시스코 데이터센터 이노베이션 데이’를 개최했습니다. 이번 블로그에서는 행사에서 소개한 내용들을 자세히 전달드리고 클라우드에 대한 가시성 확보, 퍼블릭 클라우드의 출구 전략으로써의 프라이빗 클라우드 구성, 하이브리드 클라우드 구성시 성능과 비용 최적화와 같은 다양한 고민을 하고 계신 여러분들의 클라우드 전략 설정에 답을 드리고자 합니다.

<3월 31일(목) 시스코 이노베이션 데이 서울 행사 전경>
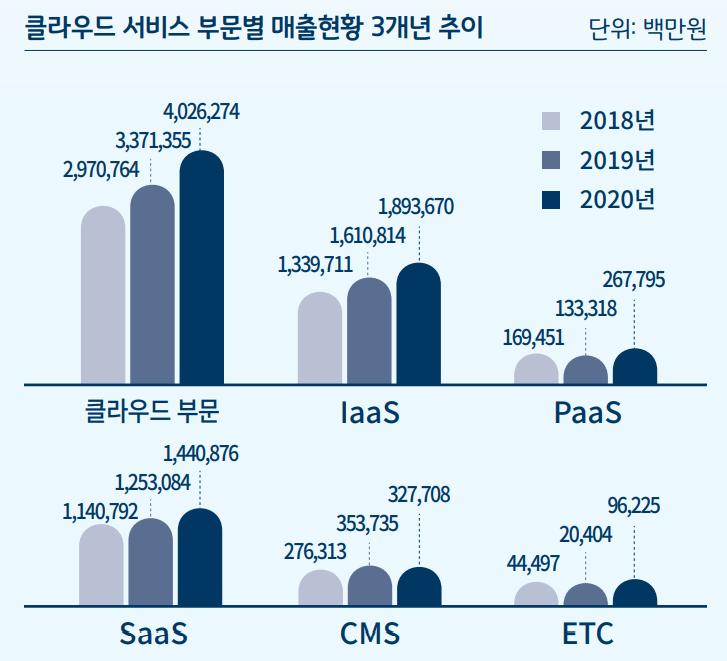
■ 2020년 국내 클라우드 시장 규모 4조원 돌파
2021 국내 클라우드 산업 실태조사 결과 보고서에 따르면 국내 클라우드 시장 규모는 가파르게 성장하여 2020년 4조원을 넘었습니다.
<이미지 출처 : KACI, 2021년 클라우드산업 실태조사 결과보고서>
부문별로 살펴보면 IaaS, PaaS, SaaS 할것 없이 전 부문 성장세를 보이고 있으며 특히 PaaS는 2019년 대비 2배 넘게 성장했습니다. 아마도 클라우드 네이티브 환경 확산이 큰 영향을 끼치지 않았을까 싶은데요. 이렇듯 국내 클라우드 시장은 매우 빠르게 성장하고 있으며, 이 추세는 앞으로도 변함이 없을 것으로 예측되고 있습니다.
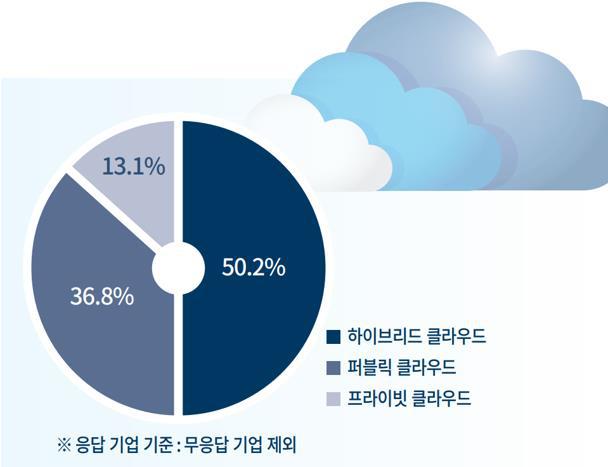
■ 클라우드는 이제 퍼블릭을 넘어 하이브리드가 대세
<이미지 출처 : KACI, 2021년 클라우드산업 실태조사 결과보고서>
앞서 살펴본 보고서에 따르면 클라우드 제공 형태 별 매출 비중의 경우 위와 같이 하이브리드 클라우드가 50.2%로 과반을 넘었습니다. 이미 국내의 많은 기업들은 지난 7년여 시간 동안 AWS를 비롯한 외산 클라우드를 통해 퍼블릭 클라우드를 충분히 경험했죠. 이 과정에서 퍼블릭 클라우드를 운영하면서 직면하게 된 인프라 운영의 불편함, 비용 이슈, 보안에 대한 걱정, 자사 데이터센터와의 연결성 등의 문제가 부각되었고, 이로 인해 다시 프라이빗 클라우드로 회귀하는 현상이 증가하고 있다고 합니다.
하지만 무조건 프라이빗을 고집하기에는 퍼블릭이 가진 민첩성과 유연성은 외면하기 어려운 시대적 흐름입니다. 그래서 프라이빗과 퍼블릭의 장점만을 결합한 하이브리드 클라우드가 각광을 받고 있고, 이에 대한 비중은 점차적으로 더 늘어날 것으로 예상됩니다. 이제 대세는 퍼블릭이 아닌 하이브리드라고 할 수 있겠습니다.
시스코는 네트워크 분야의 1위 기업으로 잘 알려져있지만 뿐만 아니라 클라우드 세상에서도 시스코는 어떤 산업이던 고객들의 클라우드로의 여정에 대한 고민을 해결할 수 있는 파트너 입니다.
Cisco Cloud Experience : Cisco Cloud Experience : 고객의 클라우드 여정을 위한 시스코의 핵심 전략 세가지

앞서 살펴본 바와 같이 국내 클라우드 시장은 하이브리드로 진화해가고 있습니다. 2020년 기준 매출 비중도 하이브리드가 50.2%였음을 확인했고, 위 장표의 왼쪽과 같이 국내 클라우드 산업 경기 전망 역시 기업의 종사자 수, 기업규모, 서비스 모델 모두 2021년 대비 2022년에 긍정 및 매우 긍정의 비중이 늘어나고 있음을 알 수 있죠. 우측의 레드햇에서 조사한 글로벌 기술 전망 보고서에 따르면 기업의 클라우드 전략 중 가장 높은 비중을 차지하는 것이 하이브리드 클라우드(2020 27% -> 2021 30%)인 것을 볼 수 있습니다.
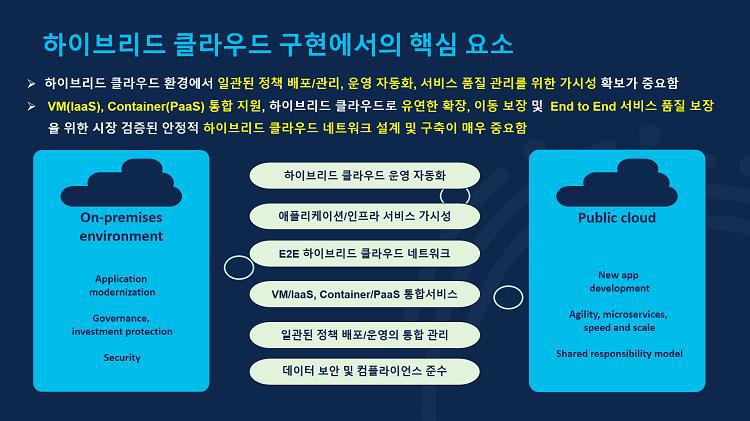
그렇다면 이렇게 높아진 하이브리드 클라우드에 대한 관심을 어떻게 실제 기업 환경에 적용할 수 있을까요? 하이브리드 클라우드 구현에 있어서 핵심 요소는 아래와 같이 6가지로 정리할 수 있습니다.
- 온프레미스 데이터 센터와 퍼블릭 클라우드를 단일화된 환경에서 효율적으로 관리할 수 있는 하이브리드 클라우드 운영 자동화
- 안정적인 서비스 품질 관리를 위한 애플리케이션/인프라 가시성
- 서비스를 사용하는 사람부터 운영하는 관리자, 그리고 온프레미스 데이터센터의 시스템과 퍼블릭 클라우드에서 운영 중인 리소스의 원활한 연결을 위한 하이브리드 클라우드 네트워크
- 기존 온프레미스의 VM부터 퍼블릭 클라우드의 컨테이너까지 아우르는 통합 지원 서비스
- 온프레미스, 클라우드 모두 일관된 정책 배포를 통한 관리
- 어느 환경에서든 높은 수준의 데이터 보안 및 컴플라이언스 준수
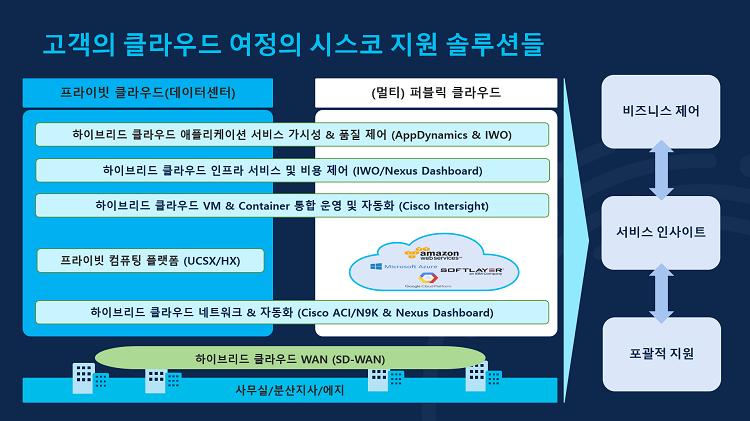
위와 같이 시스코는 온프레미스의 프라이빗 클라우드와 여러 개의 퍼블릭 클라우드를 사용하는 멀티 클라우드를 모두 커버할 수 있는 다양한 솔루션을 제공합니다. 가장 밑단에서 온프레미스와 클라우드의 원활한 연결을 위한 SD-WAN, 그리고 이 둘이 마치 하나의 네트워크로 운영될 수 있도록 지원하는 Cisco ACI와 Nexus Dashboard, 시스코의 차세대 프라이빗 컴퓨팅 플랫폼 UCS X-Series, 온프레미스의 VM과 클라우드의 컨테이너를 통합 운영 및 관리할 수 있는 Cisco Intersight, 인프라 성능 및 비용 최적화를 위한 IWO(Intersight Workload Optimizer) 및 Nexus Dashboard, 애플리케이션 성능 관리를 위한 가시성 확보 및 선제적 장애 예방을 통한 품질 제어 솔루션 AppDynamics와 IWO가 준비되어 있습니다.

그렇다면 앞서 살펴본 다양한 시스코 솔루션을 사용해야 하는 이유는 무엇일까요?
가장 중요한 이유로 이미 시스코의 솔루션들은 시장에서 검증되었다는 것을 꼽을 수 있습니다. 프라이빗과 퍼블릭 클라우드를 하나의 네트워크처럼 운영할 수 있도록 도와주는 시스코 클라우드 네트워크 솔루션(ACI/N9K)을 사용하면 위와 같이 기존의 프라이빗 클라우드 네트워크를 AWS 인프라와 손쉽게 연결할 수 있으며 이 외에도 수많은 글로벌 사례를 통해 ACI의 효과를 검증받았습니다. 국내의 경우 우리은행 금융 프라이빗 클라우드, 우체국 금융의 SDN 솔루션으로 시스코 ACI가 공급되었습니다.

IWO(Intersight Workload Optimizer)의 효과는 글로벌 시장조사기관 포레스터의 조사로 명확하게 나타났습니다. 대규모 인프라를 운영하는 글로벌 대기업들을 조사한 결과 IWO를 통해 위와 같이 막대한 TCO 절감 효과를 거두었음을 알 수 있습니다.
특히 IWO는 ESG 경영을 앞세우는 기업들에게 효과적입니다. 대기업들은 ESG경영의 일환으로 인프라에 대한 전력 및 자원의 효율적인 소비에 대한 관심이 늘었고, 소위 그린 IT라는 전력 절감 이슈가 대기업들의 주요 이슈로 부각되기 시작했는데요. 이러한 기업들은 IWO를 활용해 인프라 자원 최적화를 꾀할 수 있기에 현재 우리 회사가 그린 IT라는 방향으로 제대로 나아가고 있는가 대한 점검이 가능합니다.

하이브리드 클라우드를 위한 시스코 솔루션들의 효과는 이 사례를 통해 보다 극명하게 나타납니다. 노란색으로 표시된 문구들을 주목하시면 좋은데요. 시스코 솔루션 덕분에 분산된 환경의 자원들을 단일 관리 툴로 간편하게 관리할 수 있게 되었고 3년간 3.5M$의 비용 절감과 더불어 애플리케이션 성능 최적화를 위해 선제적 대응이 가능해졌다고 Money Mart CTO는 전하고 있습니다. IWO를 활용한 성능 최적화를 통해 비즈니스 연속성이 보장된 것은 덤이고요.
특히 인상적인 문구는 좌측 상단의 ‘Hands-free IT is our goal’입니다. 솔루션이 알아서 관리해주는 자동화된 운영과 더불어 문제가 생겼을 때 대응 방법까지 알려주고 이 마저도 자동화 기능으로 수행될 수 있도록 하게 함으로써, 자신들은 인프라에 대한 관리는 완전히 시스코에 맡기는거죠. 이를 통해 자신들은 IT 인프라 관리에 최소한의 시간만을 들임으로써 보다 비즈니스 경쟁력 향상에 집중할 수 있게 되는 것이 목표라고 해석할 수 있겠습니다.
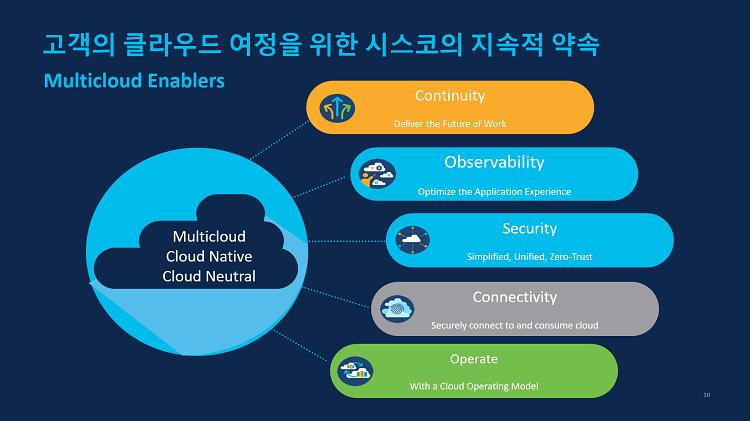
시스코는 위와 같이 고객의 클라우드 여정을 위해 아래와 같이 다섯 가지 키워드로 고객의 클라우드로의 전환을 지원합니다.
- Continuity : 클라우드 네트워크 솔루션을 활용한 프라이빗과 퍼블릭 클라우드의 연결
- Observability : 애플리케이션, 서비스에 대한 가시성과 관제
- Security : 데이터와 서비스에 대한 보안
- Connectivity : 엔드유저가 클라우드 서비스를 사용할 때 문제가 없도록 안정적인 네트워크 QOS 보장
- Operate : 자동화를 통해 운영 효율화 추구
Insight, Automate, Operate : 하이브리드 클라우드 인프라, 좀 더 편하고 쉽게 운영하기
■ 기업의 클라우드 전환을 빠르고 쉽게 수행하기 위한 시스코 전략과 솔루션들은 무엇인가?
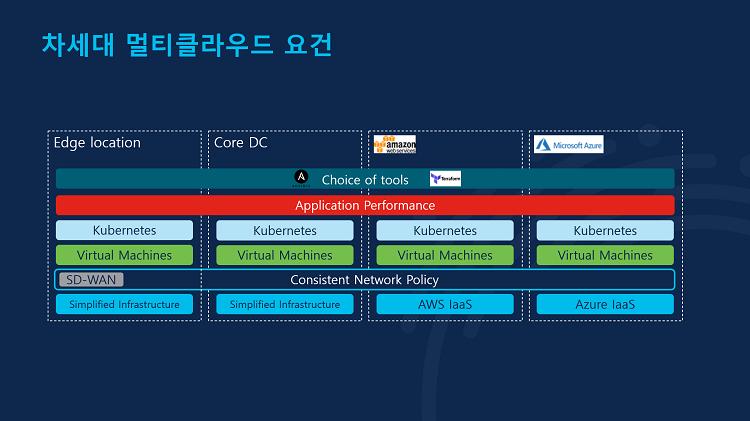
고객은 하나의 정책으로 다양한 인프라 환경을 운영하고 싶어합니다. 하지만 위와 같이 엣지, 프라이빗 클라우드(온프레미스 데이터센터)와 퍼블릭 클라우드 각각의 운영 방식이 다르기 때문에 운영 환경은 사일로화, 즉 개별적으로 운영하는 경우가 많죠. 그러나 이러한 상황에서도 네트워크가 하나로 이어질 수 있다면 이전보다 효율적인 운영이 가능할 것입니다. 여기에 운영 자동화도 적용될 수 있으면 금상첨화입니다. 따라서 차세대 멀티클라우드 요건은 기업의 인프라 환경이 어떻든지간에 하나의 단일화된 플랫폼을 통해 통합적으로, 그리고 자동화 기능을 사용해 보다 손쉽게 운영할 수 있어야 합니다.
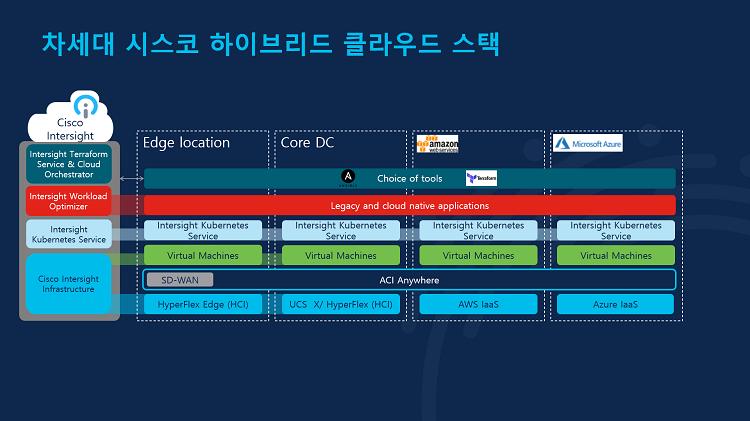
시스코는 고객이 어떤 인프라 환경을 가지고 있더라도 관계없이 시스코 하이브리드 클라우드 스택을 통해 통합 관리할 수 있도록 지원하기 위한 핵심 솔루션으로 Intersight를 제공합니다. 위와 같이 가장 밑단의 HCI와 같은 물리적 환경 및 퍼블릭 클라우드의 IaaS를 ACI로 연결하면 VM 인스턴스가 프라이빗에 있든 퍼블릭에 있든 동일하게 관리할 수 있게 됩니다.
나아가 컨테이너 역시 IKS(Intersight Kubernetes Service)로 관리되며, 이 위에서 운영되는 애플리케이션이 항상 최상의 성능으로 장애없이, 게다가 비용 효율적으로 돌아갈 수 있도록 Intersight Workload Optimizer로 최적화하고요. Ansible이나 Terraform과 같은 자동화 도구를 사용해 인프라 운영 전반을 자동화시킬 수 있으며, 이 도구를 Intersight에 통합시켜 관리자가 보다 쉽고 편리하게 이용할 수 있도록 지원합니다.
즉, 시스코는 프라이빗에서 퍼블릭, 나아가 멀티 클라우드까지 아우르는 넓은 범위의 하이브리드 클라우드 인프라를 ACI를 통해 하나로 묶고, 그 위에서 운영되는 모든 것들을 Intersight를 통해 동일한 정책으로 일관된 관리를 가능케 함은 물론 다양한 IaC 도구를 Intersight에 통합시켜 자동화 기능을 쉽게 사용할 수 있게 함으로써 인프라 운영 효율화를 지원하고 있다고 할 수 있겠습니다. 롯데그룹의 L.Cloud와 공공클라우드의 LX 국토정보교육원이 대표적인 국내 사례 입니다.
■ 특히 하이브리드 클라우드 구현 시 시스코가 바라보는 클라우드 네트워크의 의미와 핵심 고려사항은?
고객은 다양하게 분산되어 있는 환경에서 데이터를 신속하게 수집하고 처리 후 상용화할 수 있느냐에 관심이 많습니다. 그리고 이 과정을 얼마나 신속하게 할 수 있느냐에 기업의 경쟁력이 좌우된다고 할 수 있는 시대가 되었죠. 즉, 비즈니스 민첩성이 점점 중요해지고 있다고 할 수 있습니다. 때문에 기업들은 클라우드로의 전환을 시도하는 것입니다.
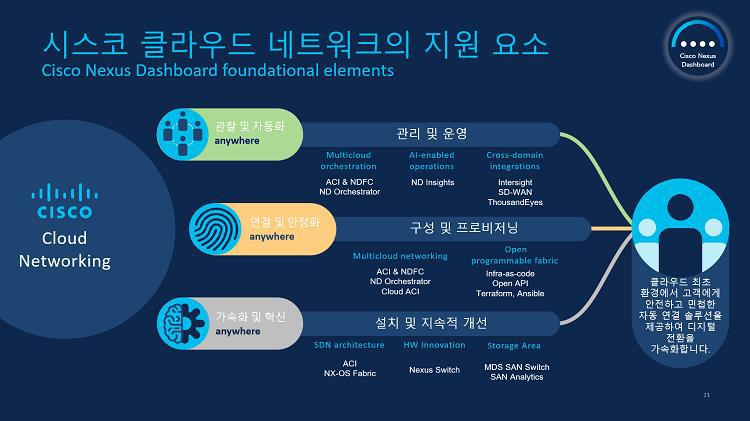
하지만 클라우드의 환경은 앞서 살펴본 바와 같이 프라이빗, 퍼블릭, 멀티, 그리고 하이브리드 클라우드로 분산되어 있습니다. 단순히 네트워크 인프라만 보더라도 프라이빗과 퍼블릭의 네트워크 환경은 구성 방식 자체가 다릅니다. 이렇게 각기 다른 클라우드 환경의 네트워크를 개별적으로 운영한다면 당연히 비용이 증가될 수 밖에 없죠. 때문에 통합관리가 필요하고, 그래서 시스코는 Nexus Dashboard를 출시해 분산된 클라우드 네트워크를 통합적으로 관리할 수 있도록 지원합니다.
시스코는 Nexus Dashboard를 통해 다양하게 분산된 네트워크 인프라의 가시성을 단일 플랫폼으로 제공합니다. 덕분에 하이브리드 클라우드의 각각 개별적으로 독립된 인프라(프라이빗과 퍼블릭)을 통합적으로 운영할 수 있게 됩니다. ACI로 연결하고 Nexus로 운영한다고 보시면 되고요. 여기에 AI 기반의 사전 장애예방 기능과 더불어 이미 자동화 도구도 함께 제공함으로써 효율성도 함께 챙겼습니다.
따라서 이렇게 다양한, 분산된 클라우드 인프라의 운영 효율화를 고민 중인 기업은 아래 네 가지 요건을 우선적으로 검토해 솔루션을 선택할 필요가 있습니다.
- 안정성 : 시장에서 검증되었는가
- 통합관리 : 사일로 관리가 아닌 통합 관리할 수 있는가
- 구성 변경 등의 이슈를 자동화로 처리할 수 있는가
- 서비스 인사이트 : 가시성을 통해 잠재적 장애요인을 사전 예방이 가능한가
당연히, 시스코는 ACI와 Nexus Dashboard로 위 네 가지 요건을 충족시키고 있습니다.
■ 시스코는 컨테이너 기반 Cloud Native 서비스 구현을 어떻게 지원하나요?

클라우드의 민첩성을 최대로 활용할 수 있는 것이 클라우드 네이티브입니다. 마이크로서비스 아키텍처를 기반으로 빠르게 애플리케이션/서비스를 개발하고 배포할 수 있기 때문이죠. 인프라 배포도, 개발도, 테스트 및 배포도 모두 빨리 빨리 처리하기 위한 DevOps가 각광받고 있고, 컨테이너와 쿠버네티스, 그리고 CI/CD가 주류인 클라우드 네이티브가 보편화되면서 이제 애플리케이션 운영 인프라는 퍼블릭 클라우드가 되었습니다. 그리고 이제는 이 환경이 멀티 클라우드로 확장되고 있습니다. 즉, 클라우드 네이티브 환경에서는 멀티 클라우드에서의 인프라 배포와 운영 자동화 필요성이 증가하고 있다고 볼 수 있겠습니다.
시스코는 이러한 시장의 니즈에 대응하기 위해 Intersight를 내놓았습니다. 인프라 관리 뿐만 아니라 VM, 컨테이너, 애플리케이션 리소스 관리부터 IaC를 통한 운영 자동화까지, 어찌보면 클라우드 네이티브 환경에 딱 알맞은, 꼭 필요한 솔루션이라고 할 수 있죠. Intersight는 다양한 기능을 제공하나 각각의 기능들은 모듈화 되어있어 기업의 환경에 맞게 취사 선택해서 사용할 수 있습니다.
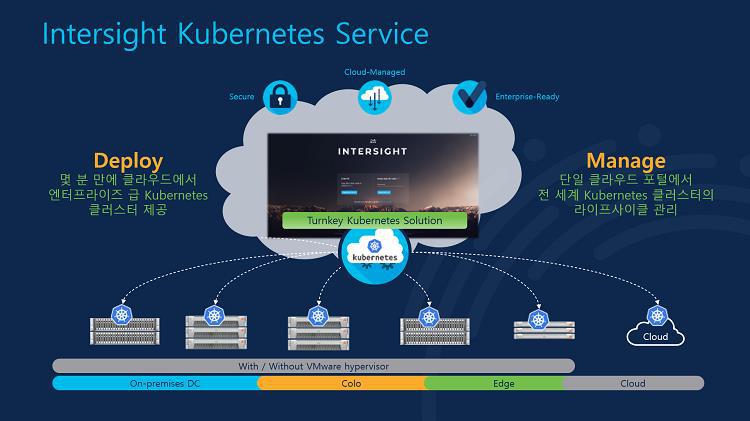
Intersight에서 제공하는 모듈 중 클라우드 네이티브 환경에 가장 중요한 것은 IKS(Intersight Kubernetes Service)입니다. 클라우드 네이티브에서 가장 중요한 것이 컨테이너이고, 이 컨테이너를 관리할 수 있는 플랫폼이 오픈소스인 쿠버네티스이며, 이 쿠버네티스를 기업 환경에서 안정적으로 사용하고 빠르고 기술지원을 받을 수 있도록 시스코가 제공하는 엔터프라이즈급 쿠버네티스 서비스가 바로 이 IKS입니다.
온프레미스에서는 VM이 주류였지만 클라우드에서는 컨테이너가 필수입니다. 하지만 온프레미스보다 훨씬 다루기 어렵고 복잡하죠. 오픈소스도 많이 사용하기 때문에 문제 발생 시 지원이 어렵고 컨테이너 상태에 대한 가시성이 부족한 것이 현실입니다. 시스코는 IKS를 통해 Intersight 화면에서 손쉽게 컨테이너 클러스터를 구축, 배포할 수 있으며, 오픈소스가 아니기 때문에 문제 발생 시 시스코의 즉각적인 지원을 받을 수 있습니다.

게다가 IWE(Intersight Workload Engine)을 통해 VM 없이도 컨테이너 구성이 가능합니다. IWE가 하이퍼바이저 역할을 하기 때문이죠. 덕분에 클라우드 네이티브 워크로드를 하이퍼바이저 + 클러스터 + 스토리지까지 풀스택으로 구성할 수 있습니다. 게다가 IWE는 별도의 라이선스 비용 없이 IKS를 사용하면 무료로 제공되기 때문에 하이퍼바이저 라이선스 비용을 아낄 수 있는 장점이 있습니다.
그리고 관리자가 다수의 컨테이너 POD들의 연결성과 이에 대한 모니터링을 원활히 할 수 있도록 시스코는 Cisco Service Mesh Manager를 제공합니다. 이 역시 IKS의 애드온 서비스로 Intersight 화면에서 손쉽게 추가해 사용할 수 있습니다.
■ 프라이빗 및 하이브리드 구현을 위한 시스코 인프라 솔루션은 무엇인가?
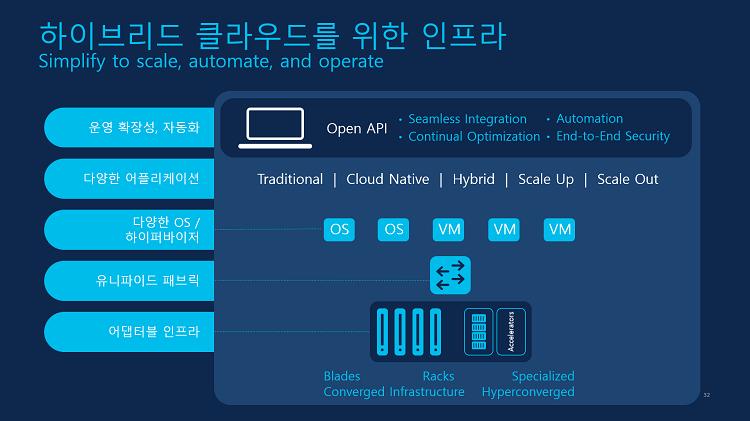
클라우드 네이티브와 같은 퍼블릭 환경이 아닌 프라이빗 환경을 위해 시스코는 차세대 컴퓨팅 플랫폼인 UCS-X Series를 발표했습니다. 퍼블릭 클라우드의 장점을 프라이빗 클라우드에 구현할 수 있도록 하는, 즉 레거시 하드웨어에서 퍼블릭 클라우드의 장점들을 누릴 수 있도록 하는 UCS X-Series는 블레이드와 랙 환경을 모두 지원하는 모듈형이며 스케일 업, 스케일 아웃 모두 자유롭게 가능합니다. 게다가 하나의 시스템에서 레거시 애플리케이션과 VM 워크로드, 클라우드 네이티브 애플리케이션까지 모두 운영할 수 있습니다.
관리 방식도 기존의 레거시 환경에서 네트워크 기반으로 하는 것이 아닌 SaaS, 고객의 데이터센터 구축형, 이 둘을 혼합한 하이브리드 형태로 가져갈 수 있습니다. 장비는 온프레미스에, 관리는 클라우드에서 할 수 있다는 것입니다. 게다가 UCS-X는 인터커넥트로 GPU와 대용량 메모리 보드를 연결해 GPU 가속이 필요한 빅데이터 분석 및 고성능 VDI 애플리케이션, 많은 메모리가 필요한 CAD 애플리케이션을 단일화된 플랫폼에서 운영할 수 있습니다.
따라서 UCS-X는 각 애플리케이션마다 필요한 시스템을 갖추는 것이 아닌 하나의 시스템에서 다양한 애플리케이션에 대응할 수 있도록 설계된 시스템으로, 프라이빗 클라우드 인프라 운영의 단순화를 목적으로 한다고 볼 수 있습니다. 관리 방식은 하이브리드 형태로 장비는 온프레미스에, 관리는 클라우드에서 할 수 있습니다.
그리고 시스코는 HCI 플랫폼인 HyperFlex를 통해 엔터프라이즈급 고성능 스토리지를 프라이빗 클라우드의 데이터센터에서부터 엣지 영역까지, 나아가 멀티 클라우드까지 확장했습니다. 데이터가 수집되는 장소는 점점 다양해지고 있는데 이 데이터의 처리를 위해 다시 특정 시스템으로가져오는 것은 불필요한 시간을 낭비하는 꼴이죠.
때문에 시스코는 HyperFlex 데이터 관리 시스템을 데이터센터에서만 제공하던 것에서 나아가 엣지, 그리고 멀티 클라우드에서도 이용할 수 있게 했습니다. 덕분에 기업은 어떠한 유형의 애플리케이션이든 인프라 위치에 대한 고민 없이 바로 그 자리에서 높은 스토리지 성능을 제공할 수 있게 되고, 최종 사용자들은 어디에서든 최상의 애플리케이션 사용자 경험을 누릴 수 있습니다.
■ 클라우드 네트워크의 지능화 관리 방안: Cisco Nexus Dashboard

앞서 하이브리드 클라우드의 네트워크 인프라를 ACI로 연결해 일관되게 운영할 수 있다고 말씀드렸는데요. 일단 ACI를 통해 하나로 연결했다 하더라도 그 운영은 사람이 해야 합니다. 즉, 장애가 발생할 경우 예전보다는 수월해지긴 했지만 역시나 사람이 직접 장애요인을 분석하고 조치해야 한다는 것입니다.
그래서 시스코는 Nexus Dashboard Insights를 통해 보다 선제적으로 네트워크 장애 상황에 대응할 수 있도록 돕습니다. Nexus Switch에서 각종 텔레메트리 정보를 수집해 분석 플랫폼으로 전달하면, AI/ML 기반으로 분석해 잠재적 장애요소를 관리자에게 알려줌과 동시에 어떻게 해결하면 되는지 해결 방안까지 알려주는 솔루션입니다. 게다가 고객이 네트워크 구성 변경을 계획할 경우, 과거에는 실제 이를 수행하기 전에는 결과를 예측하는 것을 불가능했으나 이제 Nexus Dashboard를 통해 미리 사전 시뮬레이션해봄으로써 결과를 예측할 수도 있습니다.
<이미지 출처 : Cisco Nexus Dashboard Insights White Paper>
또한 Nexus Dashboard는 엔드투엔드 트래픽을 플로우로, 애플리케이션 노드 별로 어떻게 흘러가는지를 상세히 보여줍니다. 기존의 레거시 형태에서는 패킷 분석을 해야만 했기에 이러한 분석이 어려웠지만, 이제는 Nexus Dashboard가 GUI 형태로, 포인트 별로 콕콕 찝어주어 직관적으로 보줍니다. 논리적 환경의 애플리케이션에 대한 순간적인 장애 발생 시(Microburst) 실시간 모니터링으로 캐치해서 보여줄 수 있다는 것입니다.
그리고 운영 중인 하드웨어의 펌웨어, OS 버전에 따른 보안 취약성을 미리 고객에게 알려주어 대비할 수 있게 함은 물론 현재 사용 중인 장비의 OS 버전이 이러한 취약성이 있으므로 어떤 버전으로 OS 업그레이드를 하라고 권고도 합니다. 덕분에 관리자는 기존에 파트너를 통해 받아왔던 유지보수 관련 정기 리포트가 필요하지 않게 됩니다.
■ 프라이빗 및 하이브리드 클라우드 지능화 관리 솔루션이 있나요? 있다면 어떤 기능을 제공하나요?

시스코는 하이브리드 클라우드 인프라의 지능화된 관리를 위해 다양한 솔루션을 제공합니다. 먼저 Intersight를 통해 컴퓨팅과 스토리지 영역의 운영 환경 자동화 기능을 제공하고요. 보안 취약점의 경우 Advisories가 권고하는 내용을 통해 관리할 수 있습니다.
과거에는 보유한 장비에 장애 발생 시 로그를 수집해 어떤 장애인지 파악한 뒤 기술지원 요청을 했어야 했지만 Intersight는 장애에 대한 기술지원 케이스를 자동으로 열어 관리자가 보다 빨리 대응할 수 있게 도와줍니다. 게다가 장비의 펌웨어 업그레이드 전에 어떤 부분을 고려해야 하는지를 알려주며 관리자가 원한다면 Intersight에서 자동으로 업그레이드도 수행하게 할 수 있습니다.
이렇게 컴퓨팅 영역에 대한 지능화 관리는 Intersight가, 네트워크 영역에 대한 지능화 관리는 앞의 질문에 대한 답변으로 살펴본 Nexus Dashboard가 제공한다고 보시면 되겠습니다. 그리고 AI/ML 기반의 사전 장예 예방과 같은 AIOps도 가능한 것 잊지 않으셨죠?
■ 클라우드와 같이 온프레미스 환경에서도 인프라 자동화를 어떻게 실현할 수 있나요?

클라우드가 대세가 되면서 IT 업계에서 가장 몸값이 높은 직군은 개발자라는 것 잘 알고 계실겁니다. DevOps가 보편화되면서 개발자들이 운영 영역까지 들어오게되니 그들의 몸값은 더더욱 올라가게 되었죠. 이렇게 개발자들이 인프라 운영까지 커버할 수 있게 해 준 원동력은 IaC(Infra as a Code)입니다. 하지만 문제는, 기업이 완전히 퍼블릭 클라우드로 인프라를 이관한 것이 아닌 경우, 즉 여전히 온프레미스 데이터센터도 가지고 있다는 것입니다. 그렇다면 퍼블릭 클라우드에서 누리던 DevOps의 장점을 온프레미스 환경에서는 어떻게 적용해야 할까요?
먼저 운영자와 개발자의 서로 다른 관점의 차이부터 살펴봅시다. 개발자는 클라우드에서든 온프레미스에서든 동일한 환경에서 개발하고 싶어합니다. 그래서 운영자에게 퍼블릭 클라우드에서 자신이 사용하던 것과 같은 형태의 리소스를 요청하죠. 그러면 운영자는 어떻게 온프레미스에서 퍼블릭 클라우드와 동일한 개발 환경을 제공해야 하는지 고민에 빠집니다. 온프레미스와 퍼블릭 클라우드와의 네트워크 연결은? 보안 구성은? 오픈소스 코드 관리는? 리소스 관리는? 이렇게 운영자의 고민은 점점 깊어질 수밖에 없죠.

그래서 시스코는 널리 사용되는 IaC 도구인 HashiCorp Terraform을 Intersight와 통합해서 Intersight for Terraform이라는 솔루션을 제공합니다. 만약 Terraform을 온프레미스 환경에서 사용하려고 할 경우 장비 하나 하나마다 Terraform Cloud와 연동해야 하는 복잡한 과정이 필요했습니다.
하지만 시스코가 제공하는 솔루션은 다릅니다. 온프레미스의 모든 장비들은 Intersight와 연결되고, 장비들의 통합 관리가 가능한 이 Intersight가 Terraform Cloud와 연결되는 구조인 Intersight for Terraform Cloud를 SaaS형태로 제공합니다. 덕분에 관리자는 온프레미스 프라이빗 클라우드와 퍼블릭 클라우드의 인프라를 단일화된 환경에서 자동화 기능을 활용해 손쉽게 운영할 수 있습니다.
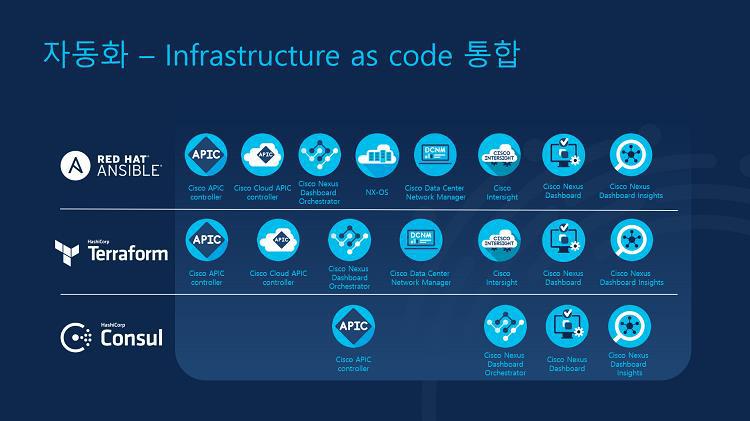
또한 시스코는 Red Hat Ansible, Terraform, Consul에서 제공하는 스크립트를 한데 모아놓은 라이브러리를 제공합니다. 관리자는 자신이 익숙한 IaC 도구 스크립트를 선택하기만 하면 빠르게 인프라 자동화를 구현할 수 있습니다. 물론 이러한 IaC 도구를 사용하지 않고 RestAPI를 통해 기업 환경에 맞게 자동화를 구현할 수 있습니다. 하지만 이는 리소스가 많이 들어가는 작업이기 때문에 IaC를 활용하는 것이 좋습니다.

능력있는 개발자들이 많다면 인프라 운영 자동화를 오픈소스로 구현할 수도 있습니다. 하지만 클라우드 인프라는 그 위에서 운영되는 애플리케이션에 따라 계속 변화합니다. 그리고 과거 레거시 환경 대비 인프라 변화 속도가 훨씬 빠르죠. 인프라가 변하면? 인프라 운영 자동화를 구현한 오픈소스도 변해야 합니다.
하지만 오픈소스의 경우 인프라 구성 변경에 대해 빠른 대처가 어렵습니다. 때문에 아직까지 오픈소스를 통한 인프라 운영 자동화 구현은 한계가 많다고 볼 수 있죠. 그래서 시스코는 Ansible이나 Terraform과 같은 검증된 IaC 도구를 자사의 Intersight와 통합해 보다 기업 환경에 알맞은 엔터프라이즈급 자동화 방안을 제공하고 있는 것입니다.
Visibility and Insights : 클라우드 인프라의 자원과 비용을 최적화할 수 있는 시스코만의 방법
■ 시스코는 클라우드 애플리케이션의 가시적 품질 관리 방안이 있나요?
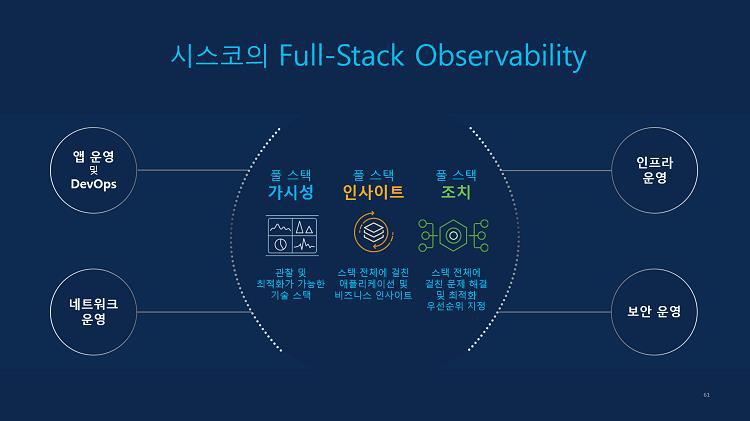
클라우드 네이티브 애플리케이션은 마이크로서비스 아키텍쳐 기반으로 개발되어 잘게 쪼개진, 모듈화된 형태로 운영되고 있습니다. 게다가 하나의 퍼블릭 클라우드가 아닌 다수의 멀티 클라우드에서 돌아가고 있는 경우가 많아 온프레미스 애플리케이션 대비 가시성을 확보하기가 더욱 어렵습니다.
또한 하나의 클라우드 네이티브 애플리케이션에는 위와 같이 다양한 부서의 이해관계가 얽혀져 있습니다. 그리고 이렇게 각기 다른 부서에서 애플리케이션을 모니터링하기 위해 사용하는 도구 역시 다 다르죠. 때문에 애플리케이션에서 문제가 발생했을 때 개별적으로 대응할 수 밖에 없어 완벽하게 장애를 해결하기까지 오랜 시간이 걸리는 구조적 한계가 있습니다.
그래서 클라우드 네이티브 애플리케이션의 모니터링을 위한 솔루션은 풀스택 가시성을 제공해야 함은 물론 관리자가 어떤 조치를 취해야 하는지도 알려줄 수 있어야 합니다. 예를 들어 피재배달 애플리케이션이 느려졌다는 상황이 발생다고 가정해 봅시다. 이 애플리케이션은 AWS 인프라에서 운영되나 DB는 온프레미스에 있습니다. 그럼 애플리케이션이 느려진 현상은 과연 어디의 문제일까요? AWS? WAN? DB? 전통적인 모니터링 도구로는 원인을 정확히 파악하기 어렵습니다. 때문에 풀스택 가시성이 필요한 것입니다.
시스코는 FSO(Full-Stack Observability)를 통해 애플리케이션이 운영되는 데에 필요한 전체 스택에 대한 플로우 세션을 실시간으로 모니터링합니다. 그리고 장애 발생 시 해당 포인트 별로 원인을 분석하며 어떻게 대응해야 하는지에 대한 가이드도 AI기반으로 분석해서 관리자에게 제공합니다. 덕분에 관리자는 전체 애플리케이션에 대한 품질 관리 체계를 수립할 수 있고, 자사의 고객들에게 안정적으로 서비스를 제공할 수 있게 됩니다.
■ 클라우드 네트워크에 관한 서비스 가시성과 인사이트 제공 방안도 있나요?

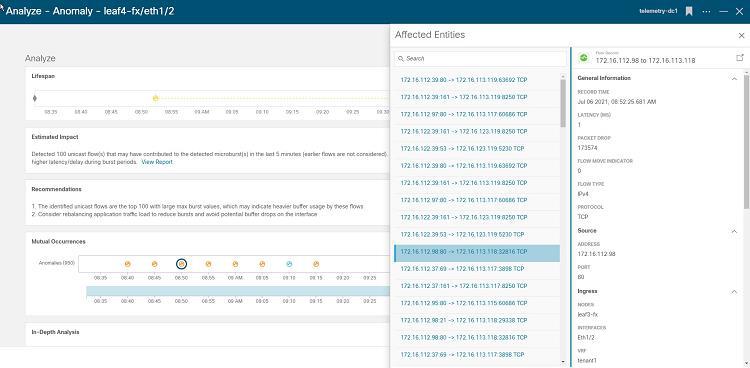
Nexus Dashboard Insights를 통해 클라우드 네트워크에 대한 가시성을 제공합니다. 단일 화면에서 멀티 데이터센터 패브릭을 볼 수 있고, 다양한 장비들의 헬스 모니터링합니다. 나아가 장비들의 잠재적 장애 요소를 파악하고 실제 발생한 장애 로그를 확인하며 방화벽, 스위치 등 노드들의 연결 흐름 및 경로 추적도 가능하고요. 그리고 각 장비의 구간마다 패킷 로스 및 지연 현황도 보여줌으로써 클라우드 네트워크에 대한 완벽한 가시성을 제공합니다.
이를 통해 관리자는 클라우드 네트워크를 효율적으로 운영할 수 있죠. 하지만 가장 큰 이점은 아마도 Microburst(마이크로버스트) 상황에 대처할 수 있는 능력을 갖게 된다는 것이 아닐까 싶습니다. Microburst가 발생할 경우 애플리케이션의 성능이 순간 느려지긴 하지만 다시 정상적으로 복구되어 관리자는 별 이상이 없다고 판단할 수 있습니다. 하지만 이는 잠재적 장애요인이기 때문에 반드시 해결해야 합니다. 이것이 원인이 되어 나중에 큰 장애가 발생할 수도 있으니까요.
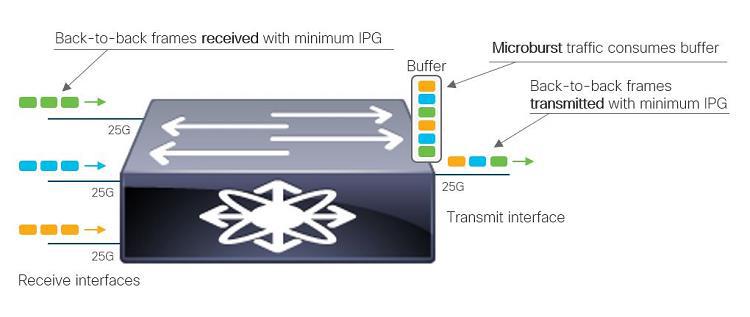
<이미지 출처 : Cisco Blog, Nanosecond Buffer Visibility with Hardware-Based Microburst Detection>
그러나 전통적인 네트워크 트래픽 모니터링 도구로는 이러한 Microburst 현상을 잡아내기 어렵습니다. 하지만 Nexus Dashboard Insights는 7일 ~ 30일까지의 텔레메트리 정보를 가지고 있고 이것을 다시 돌려볼 수 있습니다. 쌓여있는 데이터를 통해서 과거로 돌아가 Microburst를 찾아내고 분석해낼 수 있다는 것입니다.
또한 관리자는 Nexus Dashboard Insights를 통해 각 장비의 처리 한계치에 도달하기 전에 한눈에 장비 현황을 확인할 수 있어 장비의 리소스가 임계치에 다다랐을 때 갑자기 장비를 추가해야 하는 이슈를 미연에 방지할 수 있습니다. 거기에 클라우드 네트워크와 연관된 애플리케이션 성능 모니터링도 가능하죠.
정리하면, Nexus Dashboard Insights는 전통적인 NMS기능을 넘어서 플로우 기반의 가시성을 제공하고, 장애 발생 후 대응하는 리액티브가 아닌 장애 발성 전에 대응하는 프로액티브로 진화할 수 있도록 지원합니다. 이를 통해 관리자가 장비의 이상 징후에 대해 선제적으로 대응할 수 있도록 돕는 지능형 네트워크 분석 서비스라 입니다.
■ 시스코는 클라우드 서비스의 비용 제어 및 서비스 품질 최적화 방안이 있나요?
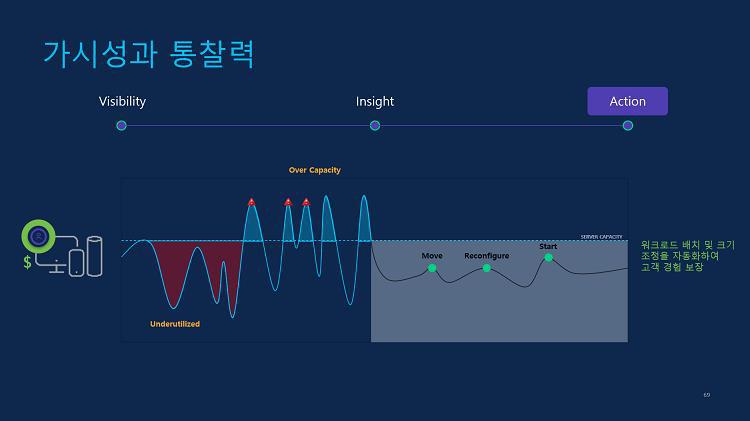
하이브리드 클라우드 인프라 운영 관점에서 관리자가 중요하게 신경써야하는 것 중 하나는 바로 리소스 사용량 제어입니다. 만약 프라이빗 클라우드에서 VM 및 컨테이너의 리소스 사용량을 확인하지 않고 계속 인프라를 배포하기만 한다면 언젠가 전체 데이터 센터의 리소스 사용량에 한계가 올 것이고, 결국 추가적으로 물리적 인프라 증설에 투자해야 할테니까요.
퍼블릭 클라우드라도 상황은 크게 다르지 않습니다. 사용자 별로 리소스 사용량을 제한하지 않는다면 비용은 기하급수적으로 증가할 수 있습니다. 때문에 한번 사용되어 용도가 폐기된 인스턴스는 그때그때 폐기하고 사용된 리소스를 회수해야 하며, 사용자 별로 사용량을 제한할 수 있어야 합니다. 그래서 하이브리드 클라우드 인프라를 위한 비용 관리 방안이 필요합니다.
이러한 이유로 시스코는 IWO(Intersight Workload Optimizer)를 통해 하이브리드 클라우드 인프라를 위한 탁월한 비용절감 방안을 제시합니다. 일반적으로 관리자가 비용 절감을 위해 사용하는 리소스를 낮추면 애플리케이션의 성능이 하락하는 문제가 발생할 수 있습니다. 게다가 보통의 경우 애플리케이션은 배포된 VM 혹은 컨테이너에 할당된 리소스를 모두 사용하는 것이 아닌 훨씬 적게 사용하고, 특정 시간 대에 트래픽이 몰릴 경우 리소스 사용량이 피크를 치게 됩니다.
그렇다고 관리자가 이 피크치는 상태에 맞게 리소스를 할당할 수는 없습니다. 그렇게 하면 너무 많은 클라우드 비용이 부과될테니까요. 그렇다고 언제 트래픽이 피크치는지를 24시간 모니터링하다가 그때를 대비해 리소스를 더 많이 할당해 둘 수도 없는 노릇입니다. 이러한 문제를 IWO가 해결해 줍니다.
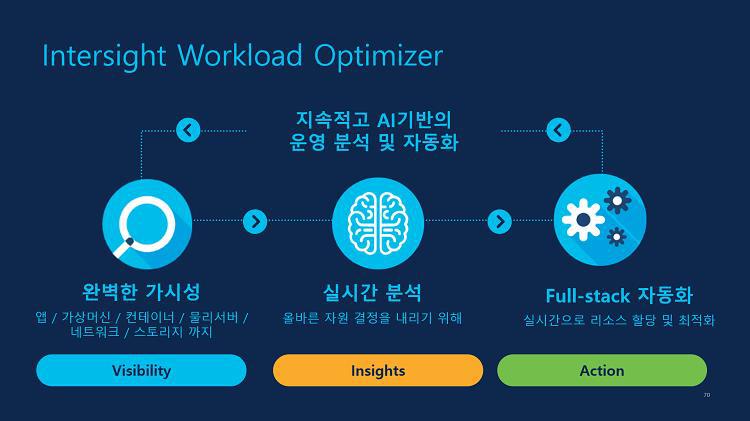
<이미지 출처 : Cisco, Cisco Services for Cisco Intersight Workload Optimizer At-a-Glance>
IWO는 애플리케이션 인프라 전체의 가시성을 제공하기 때문에 어느 스택에서 리소스를 어떻게 사용하고 있는지 한눈에 파악할 수 있습니다. 그리고 AI 기반의 실시간 분석 및 조치 방안을 제안해 주며 고객이 원하면 정책 기반으로 운영 자동화를 통해 제안받은 조치를 수행할 수도 있고요. 예를 들어 인프라의 리소스 사용량이 70% 넘기면 vGPU를 추가하거나 메모리를 추가하라는 명령을 자동화 기능을 통해 수행할 수 있습니다. 그리고 퍼블릭 뿐안 아니라 프라이빗에도 동일하게 이 기능을 활용할 수 있습니다.
게다가 IWO를 사용하면 온프레미스에서 퍼블릭 클라우드로, 퍼블릭 클라우드에서 프라이빗 클라우드로의 마이그레이션도 시뮬레이션할 수 있습니다. 단순히 시뮬레이션하는 것을 넘어 비용을 더욱 아끼기 위해 어떤 조치가 필요한지도 제안해주거든요. 이는 기업의 ESG 경영 실현에 있어 매우 유용한 솔루션이 될 수 있다는 의미도 됩니다. 클라우드 마이그레이션을 통해 온프레미스의 인프라 전력비용을 얼마나 아낄 수 있는지를 미리 파악함은 물론 비용 최적화 방안까지도 알 수 있을테니까요.
만약 기업이 하이브리드 클라우드 전략을 수립했다면, IWO로 컴퓨팅 및 스토리지 영역을, 앞서 언급한 Nexus Dashboard로 네트워크 영역을 최적화하면 되겠죠?
2. 세션 03 데모시연
■ Nexus Dashboard 네트워크 가시성 데모
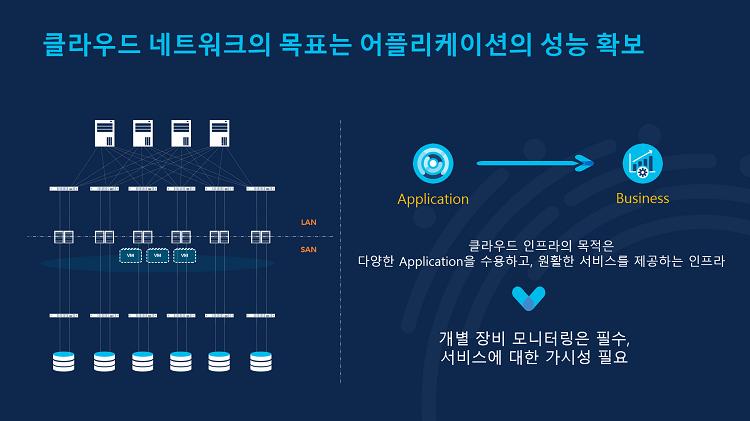
클라우드 네트워크 인프라의 목적은 다양한 애플리케이션을 안정적으로 운영함과 동시에, 언제 어디서든 사용자가 애플리케이션을 이용하는 데에 불편함이 없도록 최상의 성능을 제공하는 것입니다. 그렇기 때문에 클라우드 네트워크 인프라에는 다양한 정보가 연계된 가시성이 필요하며, 이를 위해 관리자는 장비의 상태정보 뿐만 아니라 장비를 실제 거쳐가는 데이터를 볼 수 있어야 합니다.
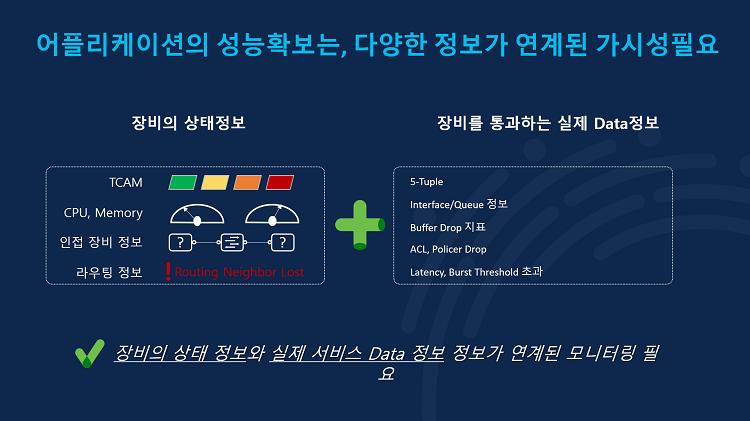
Nexus Dashboard는 수집된 정보를 토폴로지 형태로 그려서 트래픽의 흐름을 보여줍니다. 이를 통해 관리자는 각각의 애플리케이션과 데이터 센터 장비의 연결 상태를 확인할 수 있고요. 장비의 상태 확인 뿐만 아니라 현재 보고있는 Nexus Dashboard에서 네트워크 인프라 배포도 가능합니다.
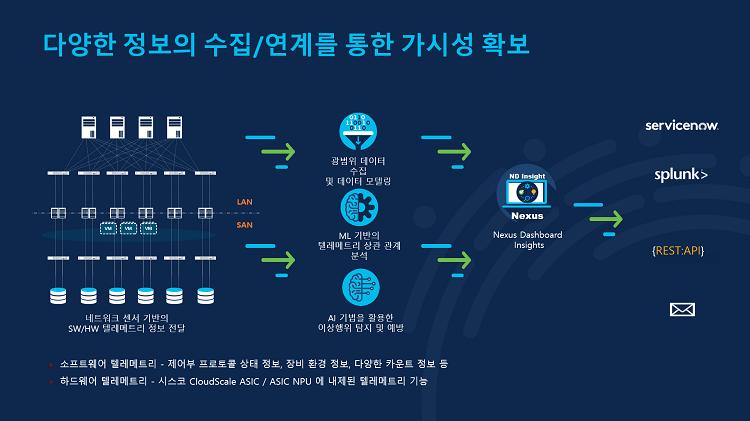
기존의 레거시 환경에서는 네트워크에 심각한 이슈가 발생했 때는 쉽게 알아차릴 수 있는 반면 네트워크가 정지된 것이 아닌 그냥 느리다라는 것은 확인하기 어려웠습니다. 과거에는 와이어샤크와 같은 도구를 통해 패킷을 분석해야 했지만 Nexus Dashboard는 모든 패킷을 수집해 플로우 형태로 화면에 보여줌으로써 관리자에게 네트워크 상태에 대한 높은 가시성을 제공할 수 있습니다.
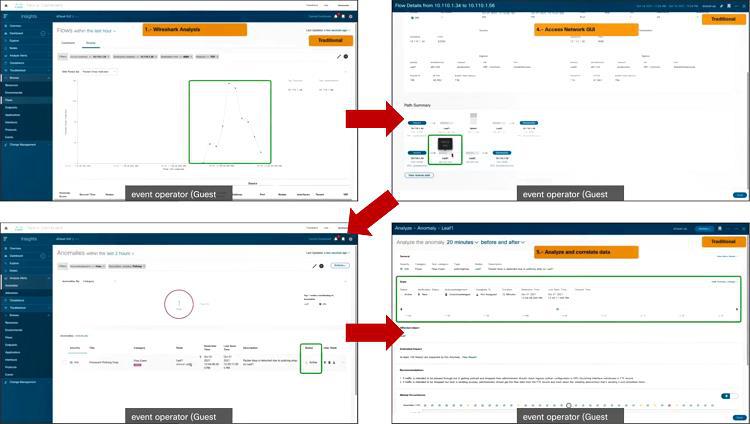
따라서 이런 시나리오가 가능합니다. 관리자는 패킷 드랍 카운트를 통해 어느 호스트에서 통신이 되지 않고 있다는 것을 확인한 뒤, 해당 호스트로 이동해 어느 플로우에서 문제가 생겼는지 확인합니다. 이후에 정책 적용 문제로 인한 QOS 문제임을 확인하고요. 가장 최초로 발생한 시간이 언제인지 파악할 수 있을 뿐더러 Nexus Dashboard가 여전히 동일한 문제가 발생하고 있으니 이런 조치를 취해야 한다라는 제안까지 해줍니다.
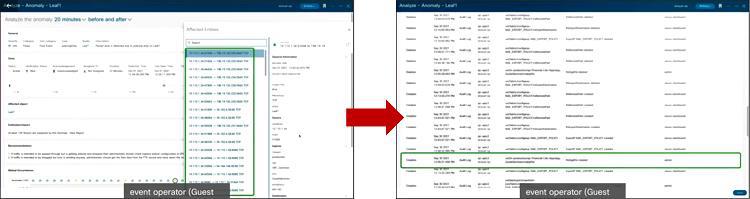
게다가 Nexus Dashboard가 실제 어떤 애플리케이션이 영향을 받고 있는지도 알려주기 때문에, 관리자는 정책 설정 변경을 통해 문제를 빠르게 해결할 수 있습니다. 이후에는 문제 발생부터 해결까지의 전 과정이 기록되어 다른 담당자가 관련 내용을 쉽게 파악할 수 있고요. 만약 설정 변경이 필요할 경우, 미리 시뮬레이션을 통해 설정을 변경했을때 인프라와 애플리케이션이 어떻게 동작하는지, 어떤 영향을 끼치는지에 대해 미리 예측해볼 수도 있습니다.
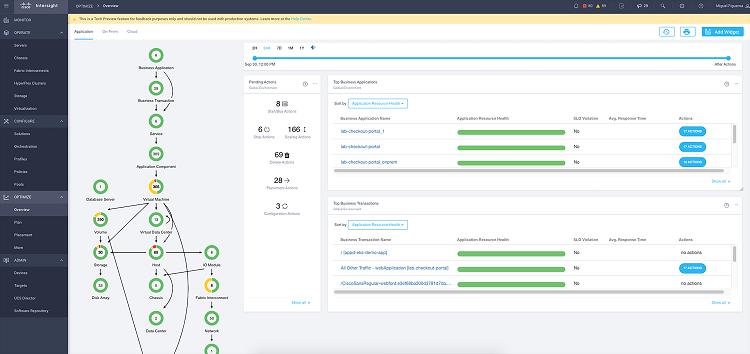
■ Intersight Workload Optimizer 컨테이너 가시성 데모
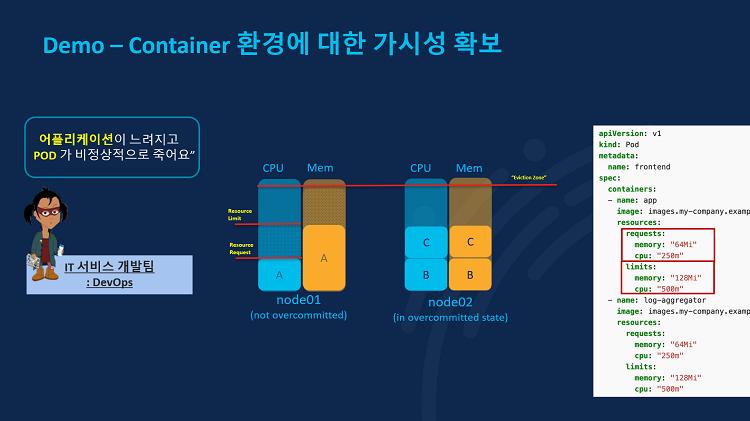
이번에는 애플리케이션이 운영되는 컴퓨팅 노드에 대한 가시성 확보 데모시연입니다. IWO 활용 데모이고요. 예를 들어 위와 같이 개발팀에서 배포한 애플리케이션이 느려지고 컨테이너 POD가 비정상적으로 자꾸 죽는다는 요청이 접수됐다고 해봅시다. 그럼 운영자는 쿠버네티스에서 POD의 상태를 점검해봐야 합니다.
일단 운영자는 배포된 노드 2개에 총 3개의 POD가 운영되고 있음을 알았습니다. 그런데 이런 상황에서 트래픽이 몰리게 될 경우, POD는 노드에 할당된 리소스를 더 가져다 사용해서 POD 수를 늘리는 스케일 아웃을 실행합니다. 위 장표 우측의 requests에 있는 사양 만큼의 리소스가 충분하다면 POD가 늘어날 수 있고, 1번 노드는 리소스에 여유가 있기 때문에 POD A가 스케일 아웃이 될 수 있는 상황인 것입니다.
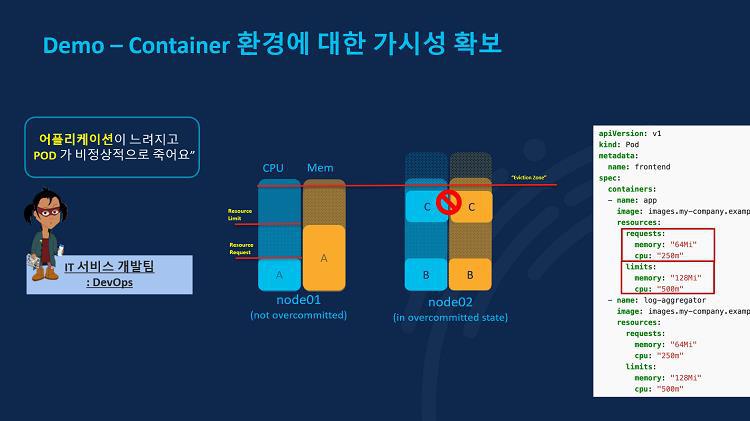
하지만 2번 노드의 상황은 좀 다릅니다. POD B와 C가 운영되고 있는 2번 노드의 경우 트래픽이 늘어날 경우, 스케일 아웃으로 POD가 늘어날만한 충분한 리소스가 확보되지 않은 상태입니다. 만약 이 때 2번 노트에 트래픽이 몰린다면 원활한 성능 확보를 위해 POD는 CPU를 더 필요로 하게 될 수 있죠. 하지만 노드에 할당된 CPU 리소스가 한정되어 있기 때문에 POD의 CPU는 쓰로틀링이 걸리고 강제적으로 클럭을 낮춰서 부족한 CPU를 보충합니다. 이 경우 애플리케이션은 작동하나 성능 지연 현상이 발생하게 됩니다.
그런데 문제는 CPU가 아닌 Memory 리소스입니다. 쿠버네티스는 노드에서 애플리케이션이 운영되는 POD에 할당할 CPU가 부족하면 앞서 언급한것과 같이 쓰로틀링을 발생시켜 클럭을 낮춰 부족한 CPU 리소스를 확보하지만, Memory가 부족해지면 그냥 해당 POD를 죽여버립니다. 그래서 2번 노드와 같이 B, C 두개의 POD가 동시에 운영되고 있고 트래픽이 몰려 Memory가 부족해지는 상황이 발생하면 POD가 죽어버리는 것입니다. 그래서 개발자는 ‘난 분명 애플리케이션 정상적으로 테스트하고 오픈했는데 왜 자꾸 죽음?’이라고 운영자에게 문제를 제기할 수 밖에 없는거죠.
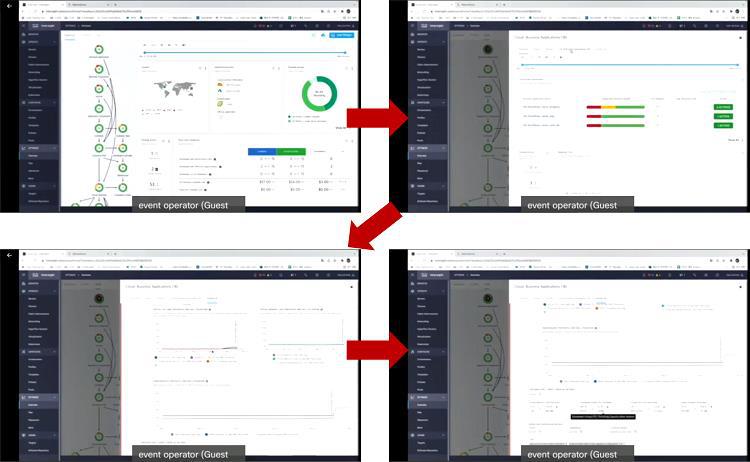
이런 경우 운영자는 IWO에서 애플리케이션이 돌아가고 있는 POD를 토폴로지뷰 형태로 확인할 수 있습니다. IWO는 운영되는 서비스를 중심으로 POD들을 한눈에 보여주며, 각각의 POD가 어느 네임스페이스, 어느 호스트에 존재하는지도 확인할 수 있습니다. 이런 관계도는 운영자가 스스로 그릴 수도 있으나 이는 크게 의미가 없습니다. 클라우드 네이티브 애플리케이션 특성 상 관계도는 계속 변하기 때문이죠. 그래서 IWO는 매번 변경된 사항을 확인해 운영자에게 최신의 관계도를 보여줍니다.
관리자는 문제가 있는 POD를 확인한 다음, 해당 POD를 클릭해 드릴다운해서 세부 내용을 확인할 수 있습니다. IWO가 권고하는 내용이 무엇인지도 확인할 수 있고요. 이 상황에서 IWO는 Front End에서 CPU 쓰로틀링이 발생하고 있는 반면 Memory는 애초에 너무 적게 책정되어있기 때문에 POD가 죽는 것이라고 알려줍니다. 그래서 Memory 리소스를 더 많이 할당함으로써 POD가 죽는 문제를 해결할 수 있다고 알려주고, 어느 정도 Memory를 늘리는 것이 좋으며 그 때 전체적인 리소스 사용량 및 POD에 끼치는 영향은 어느 정도인지도 운영자에게 알려줍니다.
이 데모시연의 의미는 컨테이너의 운영방식은 온프레미스의 VM을 운영하던 방식과 다르다는 데에 있습니다. CPU 사용량이 낮지만 쓰로틀링이 발생하는 이유, 이 때문에 애플리케이션의 성능이 저하되는 이유를 기존의 성능 모니터링 도구로는 확인하기 어렵죠. 그리고 비정상적으로 POD가 죽는 이유도 파악하기 어려울테고요.
컨테이너 환경에서는 컨테이너가 필요한 리소스와 앞으로 필요할 리소스가 얼마인지 알 수 있어야 합니다. 즉, 컨테이너 환경에는 과거의 모니터링이 아닌 컨테이너에 알맞은 새로운 모니터링 방식이 필요하다는 의미로 해석할 수 있겠습니다.
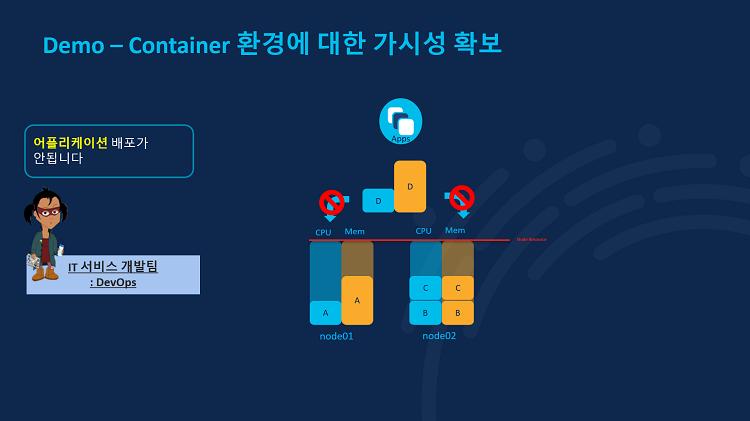
이번에는 개발팀에서 애플리케이션 배포가 안된다는 요청이 접수되었다는 사례를 살펴봅시다. 이러한 경우 보통 개발자는 운영자에게 메모리가 얼마나 필요하다고 구체적으로 알려주지 않습니다. 따라서 운영자는 노드 별로 일단 알아서 리소스를 할당해 POD를 배포할 수 밖에 없죠. 위와 같은 상황에서는 개발자가 배포하려는 D 애플리케이션을 위한 POD가 생성될 공간이 1번 노드에도 2번 노드에도 없습니다. 그래서 개발자는 애플리케이션 배포가 안된다는 요청을 운영팀에 한것이죠.
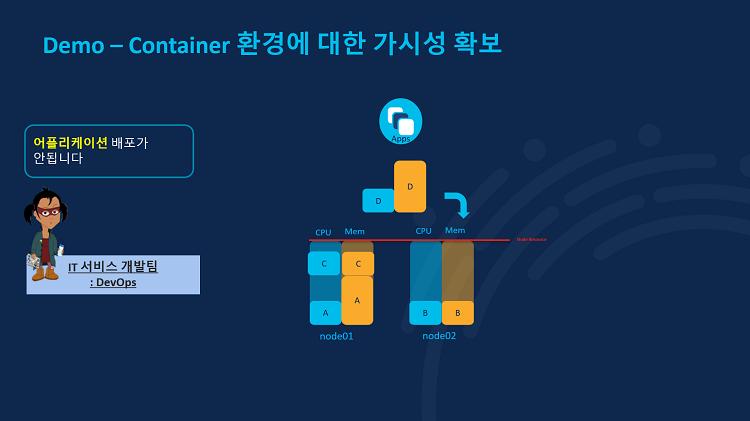
만약 이런 상황에서 위와 같이 2번 노드의 POD C가 1번 노드로 이동한다면 어떨까요? 2번 노드의 리소스에 여유가 충분히 생겨 POD D가 2번 노드로 배포될 수 있습니다. 하지만 안타깝게도 쿠버네티스에는 운영 중인 노드에서 POD를 이렇게 옮겨주지 않습니다. 그나마 다행인것은 쿠버네티스는 노드가 운영되기 전에는 노드 별 리소스를 확인해서 POD를 자동으로 배포하기 때문에, 아직 운영중이지 않는 노드라면 이와 같은 노드의 리소스가 부족해 POD 배포가 불가능해지는 상황을 방지할 수 있다는 것입니다.
하지만 말씀드렸듯이 노드가 운영 중이라면? 쿠버네티스는 이런 작업을 수행하지 않습니다. 한번 운영을 시작한 노드의 리소스는 이미 정해져있기 때문에 추가적인 애플리케이션 배포를 위해 POD가 생성될 공간이 없죠. 그래서 개발팀에서 애플리케이션 배포가 안된다는 요청이 접수되는 것입니다.
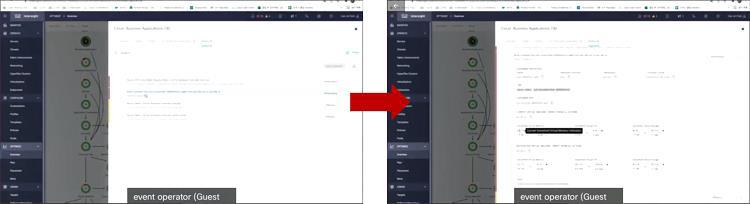
이러한 상황에서 IWO가 있다면 문제를 쉽게 해결할 수 있습니다. 위와 같이 운영자는 IWO에서 2번 노드의 POD C를 1번 노드로 옮기라는 권고사항을 확인할 수 있고요. 이렇게 POD를 이동시킬 경우 2번 노드의 Memory 사용량이 줄어들어 개발팀에서 계획중인 새로운 애플리케이션 배포를 위한 POD D의 배치가 가능해집니다. 즉, IWO를 사용하면 쿠버네티스에서 제공하지 않는, 운영 중인 노드에서 POD를 이동시킴으로써 노드 별 부하를 분산할 수 있다는 것입니다.
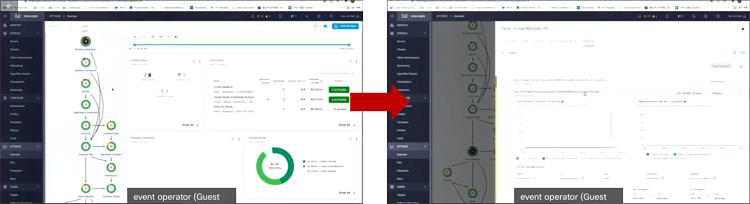
게다가 IWO는 노드 별 부하분산 뿐만 아니라 비용 절감 방안도 제시합니다. IWO가 현재 운영 중인 VM의 타입을 파악해 더 저렴한 VM 타입으로 변경하라는 권고를 하는 것인데요. 위와 같이 AWS에서 이미 배포된 EC2 타입을 IWO가 보고, 최근에 새로 나온 더 최신 타입의, 하지만 월 비용은 조금 더 저렴한 EC2 타입으로의 변경을 권고할 수 있습니다.
그리고 이렇게 조치했을 때 얼마만큼의 비용이 절감되는가도 미리 확인할 수 있고요. IWO가 애플리케이션 운영 비용 최적화를 위해 필요한 최적의 EC2를 파악해 운영자에게 제안하는 것으로 이해하시면 됩니다.
![]()
결론 : 새 술은 새 부대에, 하이브리드 클라우드 인프라에는 그에 알맞은 검증된 솔루션을 사용해야
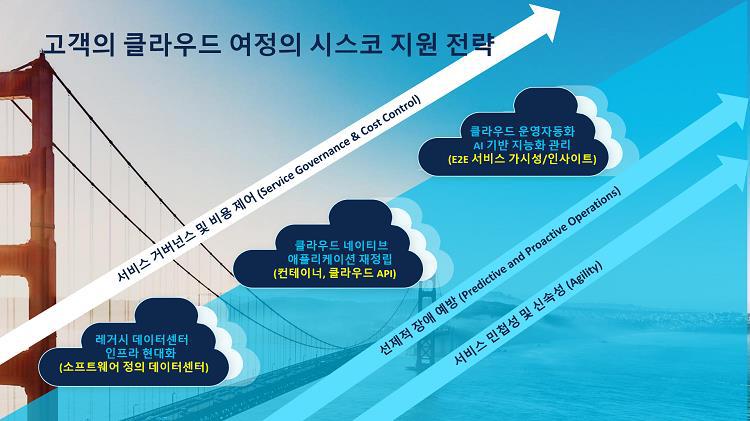
지금까지 데이터센터 이노베이션데이 세미나에서 소개된 내용을 정리해 보았습니다. 마지막으로 요약하면, 시스코는 고객의 클라우드 여정을 위해 시스코는 크게 세 가지 전략을 가지고 있습니다.
- 기존 레거시 데이터센터 현대화 : SDDC로 구현, 온프레미스 데이터 센터를 클라우드 네이티브 – 컨테이너 기반의 아키텍처로 전환해 프라이빗 클라우드를 위한 SDDC로 구현, 이를 위해서는 인프라 설계 및 모니터링 요건이 잘 갖춰져 있는 솔루션인지 검토해야 함
- 클라우드 애플리케이션 재정립 : 클라우드 인프라에서 운영되는 애플리케이션/서비스에 대한 가시성(상호 인과관계, 연계성, 시각화 + 실시간 모니터링), 특정 영역에 대해 이슈가 발생했을 때 AI 기반의 해결 방안을 제시하며 장애에 대한 사전 예방을 통해 서비스 연속성을 안정적으로 유지할 수 있는 환경 구축
- 클라우드 운영자동화, AI 기반 지능화 관리 : 검증된 IaC 도구가 통합된 Intersight, ACI로 연결된 클라우드 네트워크를 위한 Nexus Dashboard를 통해 하이브리드 클라우드 인프라의 운영 자동화 및 AI 기반 지능화 관리 구현
시스코는 위 세 가지 전략의 성공적인 수행을 위해 분산된 클라우드를 하나의 네트워크로 연결하는 클라우드 네트워크를 중요하게 생각합니다. 하이브리드 클라우드 네트워크는 공용 IP 주소를 사용하는 것이 아니기 때문에 클라우드 네트워크 설계가 매우 중요합니다. 때문에 ACI를 통해 하이브리드 클라우드 네트워크의 QOS, 즉 서비스 품질을 안정적으로 관리하는 것이 무엇보다 중요하다고 세미나 도중 여러번 언급되었고요.
이 기반 위에서 네트워크의 지능화 관리는 Nexus Dashboard, 컴퓨팅 운영은 Intersight에 맡기고 세부적인 애플리케이션의 성능 관리 및 비용 최적화를 IWO, Nexus Dashboard Insights를 통해 수행한다면, 기업은 하이브리드 클라우드 인프라를 효율적으로 운영하면서 비즈니스 경쟁력 향상에 더욱 역량을 집중할 수 있습니다.

Authors