

ネットワークに接続されたデバイスは相互に通信することもできるので、デバイス間のトラフィックを分析することは常に関心の的となってきました。
ネットワークの複雑さが増すにつれて、トラフィック分析専用ツールの有用性が向上しました。ここ数年、Snort![]() や Wireshark といったツールが大きく進歩していますが、せっかくの便利なツールも、ツールに正確な情報を提供できないと役に立ちません。ネットワークを流れる情報のサブセットをモニタリングツールに送信するだけでは、アナリストがネットワークの状態を把握できるだけのデータが得られません。
や Wireshark といったツールが大きく進歩していますが、せっかくの便利なツールも、ツールに正確な情報を提供できないと役に立ちません。ネットワークを流れる情報のサブセットをモニタリングツールに送信するだけでは、アナリストがネットワークの状態を把握できるだけのデータが得られません。
これは、ほとんどの PLC が接続されているほぼすべてのバックプレーンネットワークに見られる問題です。ネットワークを横断するイーサネットトラフィックであればキャプチャして分析できますが、標準以外の通信や独自仕様の通信ではトラフィックを逃してしまうことが少なくありません。Talos では、この問題に Badgerboard で対処しようとしました。Badgerboard はこれまでアクセスできなかったバックプレーントラフィックのデータを開示するように設計された新しいコンセプト実証ツール![]() で、OT ネットワークオペレータはネットワークの現在の状態を深く理解できるようになります。
で、OT ネットワークオペレータはネットワークの現在の状態を深く理解できるようになります。
可視化の現状
バックプレーンネットワークで現在起きていることを可視化するのは新たに浮上した問題ではなく、不可能なことでもありません。ただし、ネットワークの全体像を把握することが目的の場合、簡単には入手できない情報も取得しなければならず、やや手間がかかります。
SPAN ポート
多くの PLC とその関連するネットワークモジュールには SPAN ポートとして設定できるイーサネットポートが搭載されているので、バックプレーンでトラフィックを分析できます。このとき問題となるのは、こうした SPAN ポートはイーサネットトラフィックを可視化するにすぎないことです。バックプレーンで発生するデバイス間のトラフィックがすべてイーサネットトラフィックであるとは限りません。
WeaselBoard
2013 年に、サンディア国立研究所が「WeaselBoard」というプロジェクトの詳細を説明したテクニカルレポートをリリースしました。WeaselBoard はサポート対象のバックプレーンに接続してトラフィックを可視化するための物理モジュールで、これがなければトラフィックを分析できませんでした。Allen Bradley ControlLogix 5000 バックプレーンと S7-300 バックプレーンに取り付けられた PLC のゼロデイ保護を実現する機能を備えており、これは基礎となるシステムに加えられた変更を分析することで達成していました。
WeaselBoard プロジェクトの追加情報については、サンディア国立研究所のプロジェクトサイト![]() にアクセスしてください。
にアクセスしてください。
Badgerboard の開発
Badgerboard の技術的背景を詳しく見ていく前に、このプロジェクトの目的が何なのか、そしてこちらの方が重要なのですが、プロジェクトの目的ではないものは何かを明確にしておきたいと思います。
Badgerboard の目的は、コンセプト実証研究プロジェクトとして、バックプレーンの可視化拡大が実現可能であることを示すことでした。隅々まで完全に設計されたソリューションや汎用的なソリューション、アクティブにサポートされるソリューションを構築することが目的でなかったことは、私たちの日々の業務を考えれば当然のことであり、現在のところ、そのようなソリューションだとは考えていません。私たちの願いは、このプロジェクトをきっかけに、お客様がベンダーにさらに高度で完全なモニタリングソリューションを強く求めていただくことです。
Modicon M580 と X80 バックプレーン
Modicon は Schneider Electric 社のプログラマブル自動化コントローラ製品で、Modicon M580 はその新製品です。Wurldtech Achilles Level 2 認定とグローバルポリシー制御を備え、さまざまなセキュリティ設定を簡単に実現できます。デバイスとの通信は、FTP、TFTP、HTTP、SNMP、イーサネット/IP、Modbus のほか、「UMAS」という管理プロトコル経由で行えます。
X80 バックプレーンは、Modicon M580 が取り付けられるハードウェア部品で、互換性のある他のモジュールと高速に通信できます。
このセットアップを選んだ理由は 2 つあります。1 つは、以前に作業した経験があるので、コントローラとその関連する EcoStruxure 環境をよく理解していたこと、もう 1 つは、この機器が当時の最上位機器を知るための優れた基準であったことです。Badgerboard で対処する根本的な問題は、M580 や Schneider Electric に固有のものではないことに留意してください。業界全体に見られる問題であり、ここでは入手しやすく馴染みのあることから選んだ機器でデモを行っているにすぎません。
X80 バックプレーンハードウェア分析
バックプレーンに搭載されているモジュール接続用ポートのレセプタクルは 2 つ 1 組になっています。1 つはイーサネット通信用で、もう 1 つは XBus 通信用です。

バックプレーンにモジュールを配置する場合、使用可能なレセプタクルのどちらか一方または両方にそのモジュールを接続できます。CPU モジュールの場合は、両方に接続できます。バックプレーン通信ボード上のこのプラグは、次に示すように、Molex 15922040 プラグ![]() と見事に一致します。
と見事に一致します。
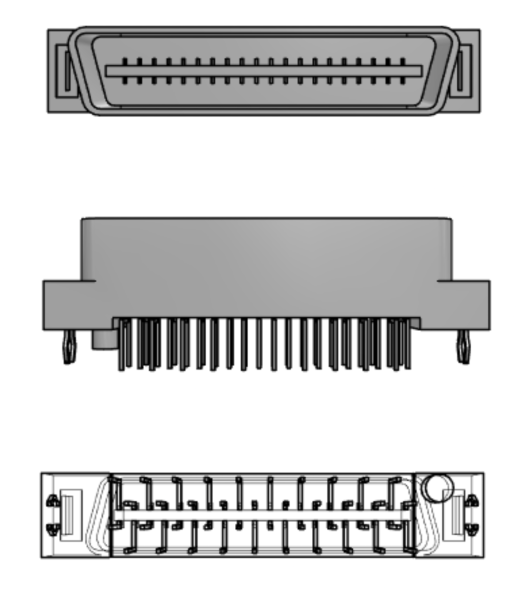
https://www.mouser.com/ProductDetail/Molex/15-92-2040?qs=ZwgtpdmWYYRx1M2EjzLg7w%3D%3D
イーサネット
CPU モジュールはイーサネットポートを搭載しているので、このモジュールを使用してイーサネットに使用するピンを決めることができます。
CPU モジュールの分析
CPU モジュールは、外部通信ボード(左)、処理ボード(右)、バックプレーン通信ボード(中央)の 3 つの部分で構成されています。外部通信ボードと処理ボードはバックプレーン通信ボードに接続し、バックプレーン通信ボードはバックプレーンに直接接続します。

外部通信ボードには、RJ-45 ポート(赤色の囲み)が 3 つあります。各ポートは信号変圧器(黄色の囲み)に接続され、それがスイッチチップ(紫色の囲み)へ、最終的にウエハーコネクタ(緑色の囲み)経由でバックプレーン通信ボードへとつながります。

イーサネットトラフィックは、バックプレーン通信ボードに接続されている場合、ボードでは確認できない配線で別の信号変圧器(黄色の囲み)に接続されています。信号変圧器は、プラグ(灰色の囲み)の下側にある 4 つのピン(赤線で示しているピン)に接続されます。


信号変圧器の分析
ピン割り当ての決定にあたっては、信号変圧器のデータシート![]() を参考にしました。変圧器では 100Base-Tx 通信のみがサポートされているため、必要になるワイヤは 4 本だけです。例示した用途の回路を見ると、ピン割り当ては次のようになっています。
を参考にしました。変圧器では 100Base-Tx 通信のみがサポートされているため、必要になるワイヤは 4 本だけです。例示した用途の回路を見ると、ピン割り当ては次のようになっています。
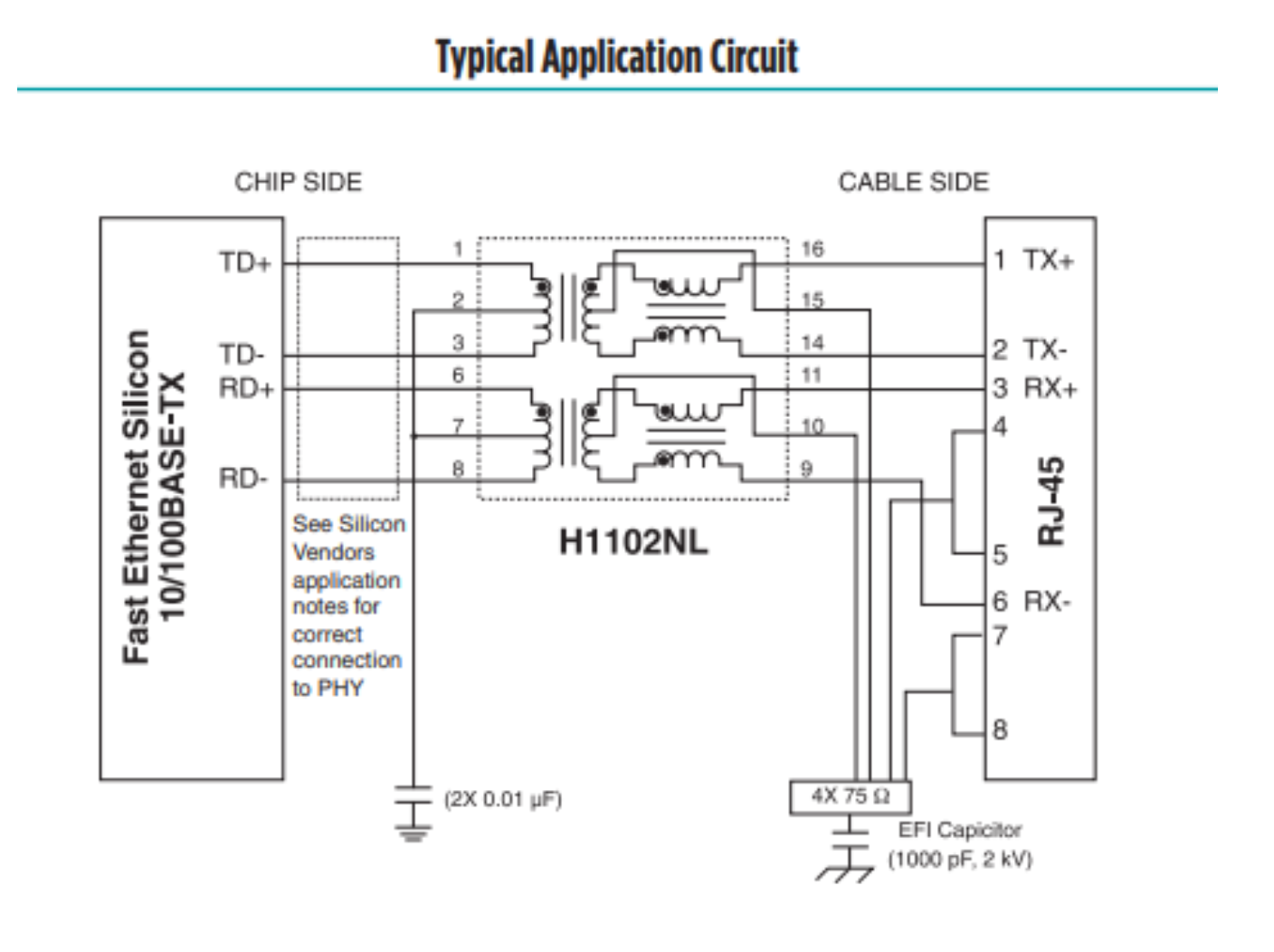
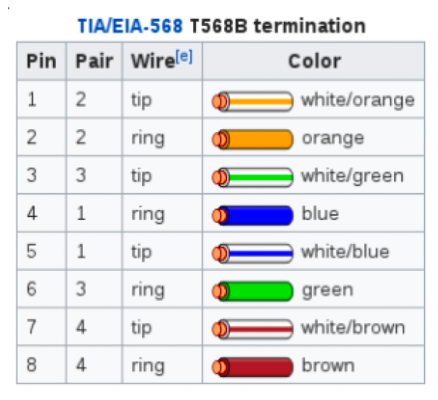
使用するワイヤを決めるときは、TIA/EIA-568 T568B ターミナルのピン割り当てを確認してください。
https://ipnet.xyz/2009/05/category-6-utp/![]()
ピン割り当て
この情報を使用して、他のイーサネットネットワークの場合と同じく、以下のマークしたピンに標準の Cat5e イーサネットケーブルを接続して、トラフィックを検査できます。

トラフィックの分析
バックプレーンネットワークの確立
前の「ハードウェアの分析」セクションで説明したピン割り当てを使用すると、次のステップに従ってバックプレーンにケーブルを接続できます。
- TIA/EIA-568 T568B に配線されたイーサネットケーブルを手に取ります。
- 一端に切れ目を入れ、被覆を剥いて、ツイストペアを剥き出しにします。
- 緑、白に緑線、オレンジ、白にオレンジ線のワイヤの被覆を剥きます。
- 上図に示すように、ワイヤをはんだ付けします。
- バックプレーンの電源がオフになっていることを確認します。
- ケーブルを差し込みます。
- バックプレーンの電源をオンにします。
物理的に接続したら、192.168.10.2 ~ 253 の範囲で IP を指定します。正常に完了すると、Wireshark に(とりわけ)大量の ARP トラフィックが表示されるはずです。
デフォルトでは、ネットワーク接続に問題が発生することが少なくありません。192.168.10.1 を ping すると、問題があるかどうか確認できます。このアドレスにホストからアクセスできない場合は、VLAN が競合している可能性があります。次のようなタイプのコマンドをいろいろ試してみると、問題の解決に役立つ可能性があります。
ifconfig eth0 0.0.0.0 up
vconfig add eth0 1
ifconfig eth0.1 192.168.10.201/16 up
トラフィックの傍受
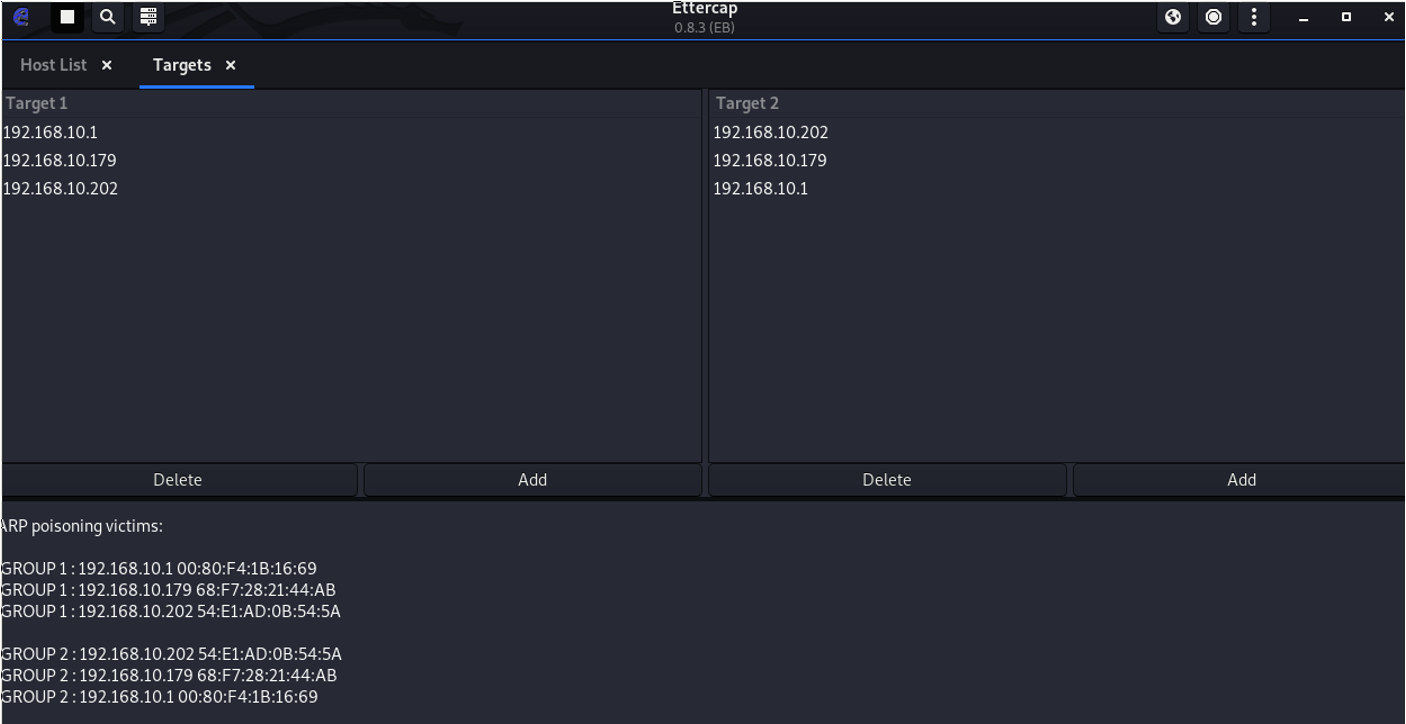
ネットワークに入ると、レイヤ 2 トラフィックと、自身が宛先または送信元となっている情報が表示されるようになります。SPAN ポート(解説済み)がないため、ARP ポイズニング攻撃を使用すると、トラフィックを傍受できます。
バックプレーンに接続した状態で、次の操作を行います。
- Ettercap を起動します。
- [Sniff] > [Unified Sniffing] に移動し、eth0.1(または設定済みのいずれかのインターフェイス)を選択します。
- [Hosts] > [Scan for hosts] に移動します。
- ポイズニングの対象になり得る標的のリストが作成されます。
- [Hosts] > [Host List] に移動します。
- 目的の標的を選択して、[Target1] と [Target2] の両方に追加します。
- [Mitm] > [Arp Poisoning] に移動します。
- Wireshark で監視します。
XBus
同じようにプラグを使用して、バックプレーンを介して XBus 通信を抽出する方法を確立できます。バスに入ると、そのバス上で送信されるすべてのトラフィックを表示できます。そのためには、ロジックアナライザを使用します。トラフィックを傍受したら、分析に進みます。
バス
XBus で基本的な通信を行うには、重要な回線を 4 つ使用する必要があります。次のように分類されています。
| アクティベーションピン | High になるとポートがアクティブと見なされ、メッセージを受信します(アクティブハイ)。 |
| 制御ピン | バスでの通信相手と、場合によっては次に届くメッセージの種類を伝える低速のメッセージ。 |
| RX クロック | バスクロック用のピン。どのモジュールも、特定の時刻にバス上でアクティブになっている通信相手に応じてクロックを駆動できます(アクティブハイ)。 |
| RX データ | バスデータ用のピン。どのモジュールも、特定の時間にバスを占有していた通信相手に応じてデータを駆動できます(アクティブロー)。 |
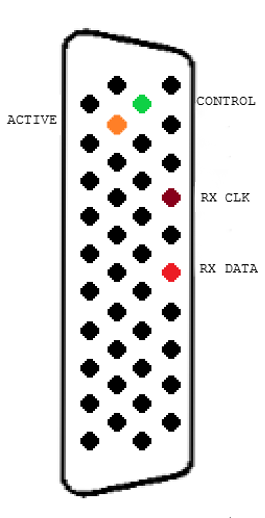
アクティベーションピン
ピン割り当てを特定したら、トラフィックのキャプチャを開始するのは極めて簡単です。アクティベーションピンを High にする必要があります。できれば低抵抗抵抗器を使用して信号が劣化しないようにするのが理想です。次の画像に示すように、分析では 470Ω プルアップを使用しています。

制御ピン
制御トラフィックは常に可視化され、これはポートがバックプレーンに対してアクティブでないと見なされた場合でも変わりません。そのため、簡単に所定のピン割り当てを理解できます。この信号は、バス速度よりも大幅に遅くなります。クロックはおそらく 500 kHz 程度ですが、制御メッセージの用途を判断するにはさらなる分析が必要です。
このとき難しいのは、制御メッセージは物理的なネットワークプロトコルに直接関連している可能性が高く、そのため XBus を実装する FPGA によって直接処理されるということです。そうなると、制御メッセージの目的について具体的な定義を追跡することが不可能ではないとしても難しくなります。
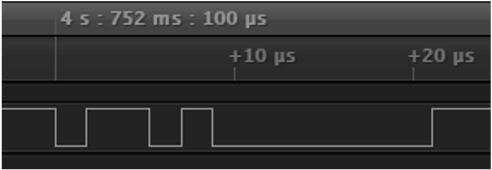
制御メッセージは、共有バスの占有/解放と、共有バスを占有/解放するデバイスアドレスに関連しているようです。ある形式のアドレスが制御メッセージで送信されるかを具体的にテストしましたが、フィールドサイズとあらゆる可能性を完全にテストするのは不可能です。
受信クロック
すべてのモジュールが共有 RX_DATA ピンで送信されているデータを追跡できるのは、RX_CLK を利用しているからです。これは現在アクティブなデバイスによって駆動されるクロックで、変化する可能性があります(これまで変化を確認したことはありません。テストでは常に 12 MHz で動作しています)。受信クロックは、バックプレーン上のすべてのアクティブポートと共有されます。

受信クロックの重要な機能の中には、ゆくゆくは設計上の問題を引き起こすものがありますが、そうした機能を利用して他にはないソリューションを構築することもできます。モジュールが通信していないときには(上の画像の最後の状態)、クロックは完全に非アクティブです。このように非アクティブになるのは、ハードウェアモジュールのクロックには適していません(クロックが非アクティブであると、ハードウェアモジュールが動作しないからです)。メリットは、新しいメッセージを送信する前に、モジュールがクロックを駆動して非アクティブにするため、メッセージが厳密に分離されて表示されることです。下の画像を見ればわかりますが、制御回線には新規メッセージが送信されておらず、一時的にクロックが明らかに非アクティブになっており、その後再びアクティブになってデータの送信を継続しています。
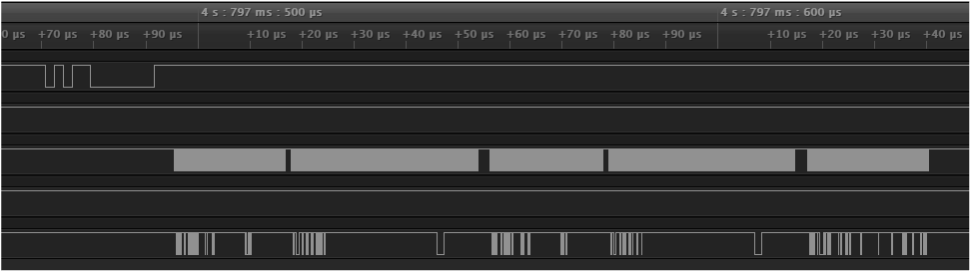
もう 1 つ、このクロックに特有の課題があります。ほぼ 12 MHz という高速で動作するため、専用のハードウェアが必要になり、UART などの低速の通信プロトコルの用途には向かないことです。

このように高速のクロックであるため、ハードウェアの実装にあたっては設計上の制約がいくつもありました。このことについては、後続のセクションで説明します。
受信データ
RX_DATA ピンは、すべてのモジュールで使用されています。アクティブなモジュールからデータを読み取ることが目的です。RX_CLK ピンと制御ピンがアクティブハイであるのに対し、このピンだけはアクティブロー信号です。データは、RX_CLK の立ち上がりエッジで読み取られます。このデータを受信して有効なメッセージが表示されるまでには、ほぼ 5 クロックサイクルかかるようです。そのため、メッセージの開始値は常に 0x04 または 0x05(5 個の 0 ビット)となっています。

プログラムによる XBus トラフィックのスニッフィング
ロジックアナライザで XBus を検査するというのは、機能するとしても、継続的に分析するためのソリューションとしては現実的ではありません。結局は、こうした検査を代わりに実行し、わかりやすい形式で情報を提示してくれるプログラムが必要になりました。
ハードウェアの制約
この時点で、ソリューションの導入にあたっては、次のようにかなりの制約があります。
- 可能な限り「リアルタイム」に近いものにする必要がある。
- つまり、UART などの「低速プロトコル」(ほとんどの市販のチップで 1 ~ 3 MHz)は選択肢にならない。
- 少なくとも 12 MHz の速度が必要(保守的な速度で正しくサンプリングする場合は、少なくとも 48 MHz の速度で動作する必要がある)。
- バックプレーンに配置する必要がある(理想的にはデバイスとバックプレーンの間には配置しない)。
- バックプレーンクロックは、定期的にオフになるため利用できない。
- Snort で検出できる形式にデータを変換する必要がある。
さまざまな選択肢を検討した結果、ハードウェアソリューションで問題にアプローチすることにし、開発作業に適したプラットフォームとして Artix-7 FPGA を選択しました。
ハードウェアアプローチ 1:失敗
最初に試したのは、UART 制限を無視し(当時は制限が不明)、バックプレーンから直接 UART でデータを一度に 1 バイトずつ転送するハードウェアソリューションを構築するというものでした。バックプレーンから無事データを抽出できたものの、UART が大きなボトルネックとなり、Snort でのリアルタイムのデータ検出という目的はまったく達成できませんでした。
ハードウェアアプローチ 2:採用したソリューション
概要
ハードウェア設計は以下のとおりです。
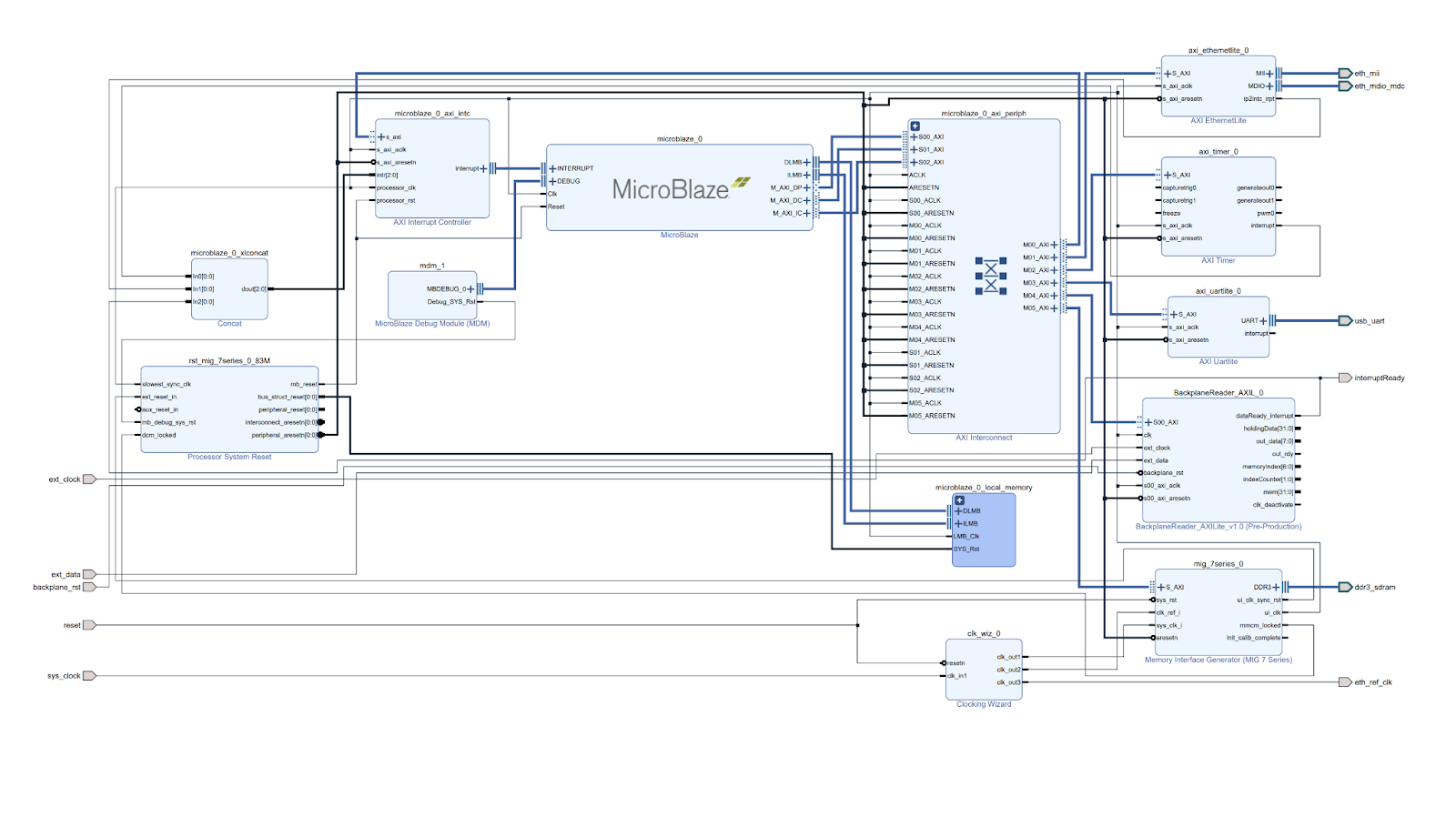
これは、Vivado に含まれている Microblaze プロセッサで、クロックは 83.333 MHz です(必要とした 48 MHz より高い値です)。物理的な入力は、画像の左側に示されています。sys_clock と reset は、ボード自体から提供されます。ext_clock、ext_data、backplane_rst はすべて入力です。ext_clock はバックプレーンから RX_CLK に接続され、ext_data は RX_DATA に接続され、backplane_rst は Arty-A7 上の DIP スイッチに接続され、動作中のバッファはすべて消去されます(これは通常、テストとトラブルシューティングを目的した設計です)。
この Microblaze プロセッサは、UART、イーサネット、さらに簡単なタイマー機器などを搭載しているので、10/100 イーサネットモジュールを通信出力として使用できます。
この設計の最も重要な部分は BackplaneReader_AXIL ブロックの dataReady_interrupt の接続です。割り込みコントローラに入る Concat ブロックに戻るように接続しています。この割り込みにより、Microblaze プロセッサはデータをさらに処理するためにどのタイミングでバックプレーンからデータを読み取ってネットワーク経由でリスニングプロセスに送出すればよいかを認識できるようになります。
一般的なデータフローは以下のとおりです。
- RX_CLK の立ち上がりエッジに記録されたビット。ビットはシングルバイトにシフトされます。
- バイトがキャプチャされると、バイトを転送する準備ができたことを通知するフラグが設定されます。
- このフラグが設定されると、バイトが 4 バイトのバッファにシフトされ、カウンタが 1 つ増えます。
- カウンタモジュロ 4 が 0 になるたびに、4 バイトのバッファが適切なインデックスの AXIL レジスタに書き込まれ、バッファが新しいバイトを受け入れます。
- これがループし、RX_CLK が 80 クロックサイクル(83.333 MHz クロックサイクル)を超えて非アクティブ(High)になるとループを抜けます。その際、CPU への割り込みをトリガーし、ネットワークにデータを送信します(パフォーマンスを確保するためにゼロコピーを使用)。
モジュールの説明
ここからは、Verilog の構成要素であるモジュールについて説明します。各モジュールは、通常のプログラミング言語でいえば関数のようなものと考えることができます。ここでは構成要素について、最も小さな(最も基本的な)ものから最も大きな(最も複雑な)ものへと順に説明します。また、前のモジュール上に構築するのかどうかについても触れます。
CLOCK_RESET
高速ハードウェアクロック(例では 83.333 MHz)で動作して、自身より低速のバックプレーンクロック(12 MHz)をサンプリングする極めて簡単なモジュールです。比較値のパラメータを取り、バックプレーンクロックが High になっている高速クロックサイクルがいくつあるかを確認するために使用します。このモジュールは、高速フォームと低速フォームの 2 つのフォームでインスタンス化されています。低速フォーム(80 カウント)は、メッセージが完了して、バックプレーンクロックが「長い」間非アクティブになるタイミングを判断します。高速フォーム(5 カウント)は、分断されたメッセージをグループ化するために使用します。これは単に、次の割り込みが発生しないうちに、プロセッサからすべてのメッセージを取得できるよう、必要なパフォーマンスを確保することが目的です。
このようなメッセージのグループ化(テストにはつきもので、特に複数の XBus メッセージに分断される UMAS メッセージの場合はそうです)が行われる前は、Microblaze プロセッサの動作が遅すぎて UDP 経由でメッセージを送信できず、別の割り込みが発生していました。これが原因で(ゼロコピーの実装前は)メモリリークの問題だけでなく、パケット損失の問題も発生していました。UDP メッセージはどれも非常に小さいので(ほぼ 48 バイトのデータ)、パケットを結合することにしました。そうすれば、パケットを NIC に移動してから送信するオーバーヘッドを削減できるからです。これはパフォーマンスのボトルネックになり得るもので、改善できる可能性があります。
SAMPLE_OUTPUT
このモジュールは、clock_reset モジュール上に構築します。このモジュールの役割は、ext_data 入力(バックプレーンからの RX_DATA)からビットをサンプリングすることです。このサンプリングは、反転したビット(この信号がアクティブローであるため)を 1 バイトのバッファにシフトし、カウンタを 1 つ増やすことで行います。カウンタが 8 に達する(1 バイトになる)と、バイトをサンプリングする準備ができたことを示すフラグが設定されます。このバッファリングが必要になるのは、この時点で、異なるクロックドメイン間(バックプレーンは 12 MHz、FPGA/CPU は 83.333 MHz)でデータを転送しているからです。
このモジュールにはこのほかに、高速および低速の clock_reset モジュールの出力を追跡する役割もあります。クロックの非アクティブ化を設定すると、まったく別の 2 つのことが起きます。高速 clock_reset を設定すると、バイトバッファカウンタがリセットされます。つまり、新しいバイトの受信が始まります。低速 clock_reset 前に複数のメッセージが存在し、実際のバイトには属さないビットがあると問題が発生しますが、これでその問題を解決できます。RX_CLK は、実データの最終ビットを受信し終えても約 5 クロックサイクル(可変)の間はアクティブな状態に保たれ、これが原因でガベージデータが収集されます。高速 clock_reset によりビットカウンタがクリアされ、ガベージデータが次のメッセージの有効なデータで上書きされます。低速 clock_reset は、バックプレーンモジュールの通信が終わったときに設定されます。これによりカウンタがリセットされ、すべてのロジックが非アクティブになります(そのため、ガベージデータが記録されません)。また、1 バイトのバッファが消去され、クロック立ち上がりエッジ検出器もリセットされます。低速 clock_reset 信号の設定を解除すると、立ち上がりエッジでビットを検出し、それを記録するという通常の操作が再開されます。
このモジュールと clock_reset の間で、バックプレーンデータを物理的なビット単位で処理します。ある意味簡単でわかりやすく、これより上位のすべてのモジュールがバッファ、クロックドメイン変更、プロセッサとのインターフェイスに使用され、使い勝手がよくなります。
BACKPLANEREADER_AXILITE_V1_0_S00_AXI
このモジュールは、プロセッサ バックプレーン サンプリングのメインインターフェイスで、AXI-Lite プロトコルのグルーロジックがすべて含まれています(Xilinx/Vivado が提供)。メモリマップレジスタ(プロセッサ内の読み取り専用メモリ空間)への書き込み機能を完全に無効にするように、グルーコードに変更を加えています。必ずしも最適化に必要なことではありませんでしたが、こうしたレジスタに書き込めるようにする理由がありません。
このモジュールは sample_output 上に構築されており、バックプレーンからシングルバイトが収集される際に、そのバイトを収集して 4 バイトのバッファにシフトし、カウンタを 1 つ増やします。そのカウンタで、モジュロ 4 がゼロになると、4 バイトのバッファ内のデータが現在のオフセットカウンタに関連付けられているレジスタに保存され、オフセットカウンタが 1 つ増えます。これは、バックプレーンからメモリマップレジスタにデータをリアルタイムに保存する目的で使用されます。各メッセージの最後に到達するたびにオフセットカウンタがリセットされ、同じバッファにすべての XBus メッセージが書き込まれます(オフセット 0 を起点とします)。各レジスタには、バックプレーンからの 4 バイトのデータが含まれています。ただし、最後のレジスタ(レジスタ 64)には、現在データが保存されているレジスタの数が含まれています(つまり、この数を 4 倍すればデータの長さが得られます)。このモジュールの役割は、プロセッサ自体にすべてのメモリマップ情報を保存することです。こうしておくことで、後でソフトウェアからこの周辺機器を使用できます。
そのほか、プロセッサが XBus メッセージの処理を開始できるように、dataReady_interrupt 信号のフリッカーを発生させる役割もあります。このフリッカーの長さと、特定のメッセージに対してフリッカー(1 クロックサイクルのみ)がすでに発生していることを追跡する必要があります。これは、プロセッサの構成(立ち上がりエッジではなく、レベルでの割り込み)に対するソリューションです。プロセッサの構成を変更すれば同じように問題が修正されることもありますが、エラーを減らすには、これが最も安全な方法です。この修正を施さないと常に割り込みが起きるため、プロセッサで割り込みループが発生して、データがまったく送信されなくなります。
BACKPLANEREADER_AXILITE_V1_0
このモジュールは、すべての内部モジュールに対して単にラッパーとして機能し、BackplaneReader_AXILite_v1_0_S00_AXI を直接ラップします。信号を直接渡すだけで、それ以外の用途は果たしません。
Microblaze システム
IP の開発を終えたので(Vivado では IP がパッケージ化されています)、Microblaze プロセッサシステムへの IP の統合を始めることができます。この統合は、AXILite プロトコルで行います。これにより、プロセッサのメモリ空間にメモリが直接マップされている周辺機器が得られ、メモリを直接読み取ることで、この周辺機器にアクセスできます。このインターフェイスにより、任意のプロセッサに搭載された RAM モジュールやイーサネットモジュール、あるいは普段作業している SOC に期待するのと同じような使いやすさを実現できます。
Microblaze の構成
Microblaze プロセッサは通常の構成にしました。ここでは、最も基本的なウォークスルーを示します。つまり、166 MHz、200 MHz(どちらもメモリコントローラ用)、25 MHz(イーサネット基準クロック)を生成するクロックウィザードが必要です。また、Arty-A7 のオンボード RAM とのインターフェイスとなるメモリコントローラも必要です。次に、Microblaze プロセッサを追加します。これで自動的に、割り込みコントローラ、プロセッサシステムリセット、デバッグモジュール(必要な場合)、プロセッサのローカルメモリ、AXI コントローラ(すべての周辺機器に対応)が含まれます。さらに、イーサネットモジュール、UART モジュール、AXI タイマー、バックプレーンリーダーといった周辺機器を追加する必要があります。
こうした周辺機器をすべて追加したら、非常に重要なステップが 2 つあります。BackplaneReader_AXIL 周辺機器を接続し、さらに dataReady_interrupt をプロセッサ割り込みコントローラに接続する必要があります。これには Concat ブロックを使用します。このブロックを使用すると、プロセッサに必要な割り込みをまとめて追加できます。また、先ほど追加したプロセッサのメモリマップのほか、構成されたデータキャッシュと命令キャッシュのアドレスを確認することも非常に重要です。これらの値を確認しなかった場合、問題が延々と続くことになります。プロセッサを起動しようとしても何も動作せず、エラーも返されないからです。カスタムの周辺機器を追加すると、DCache と ICache の両方の領域に追加されたように見えますが、どの命令もフェッチできません。いずれにせよ、この領域のキャッシュはお勧めしません。というのは、データを常時無効にする必要があるからです(この処理には時間がかかります)。
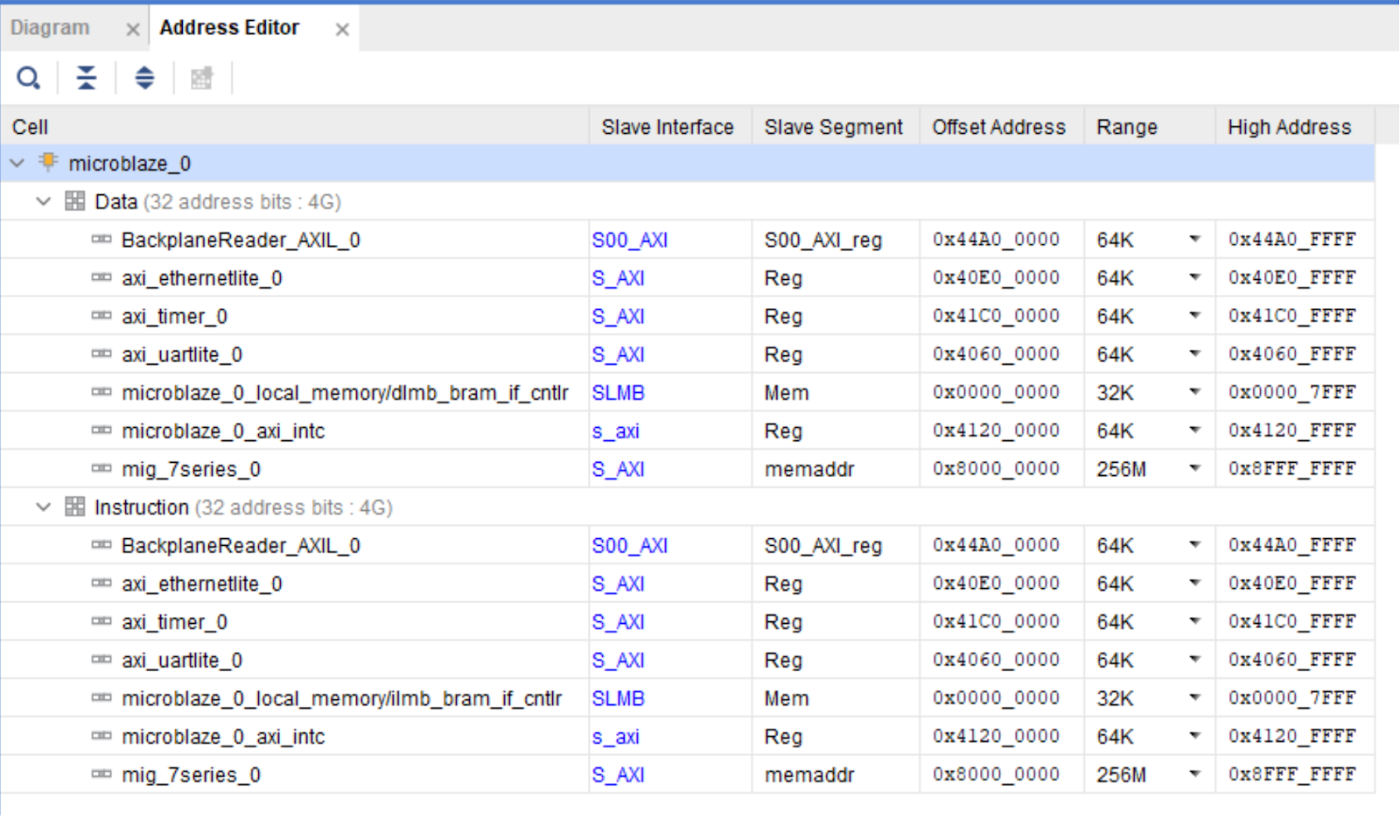
使用しているデータキャッシュ設定は次のとおりです。
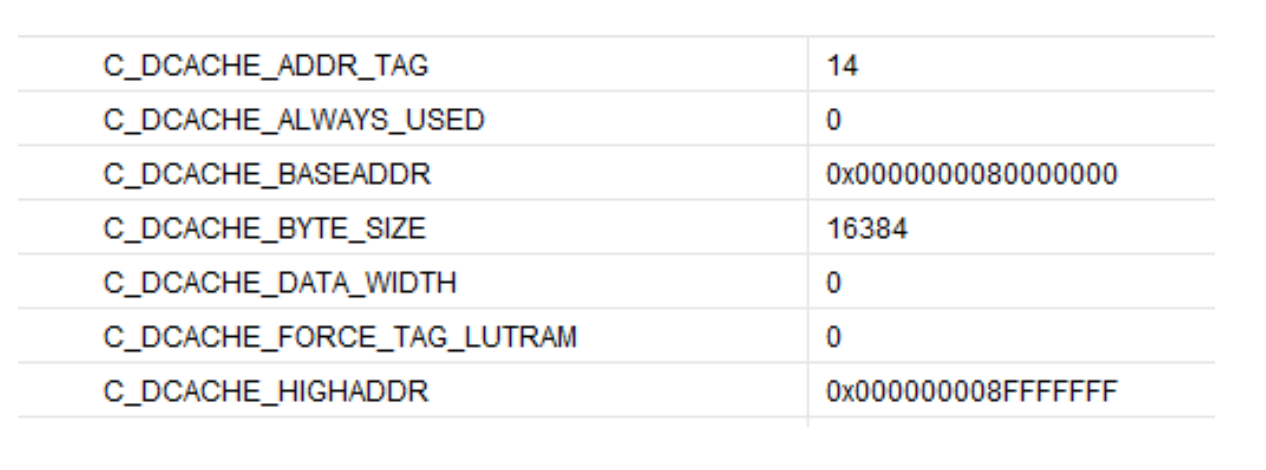
使用している命令キャッシュ設定は次のとおりです。
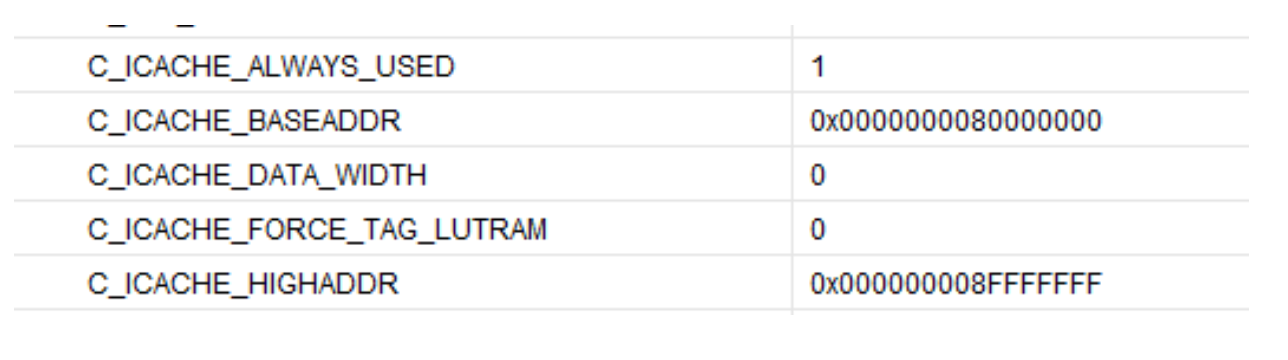
プロセッサにはごく当たり前で、メモリマップを参照する場合には申し分のない設定です。ただし、命令キャッシュが間違った場所にあるために命令をフェッチできない場合には、メモリマップが問題の発生源になる可能性があります。Vivado からはそのことがはっきりとわかる警告が通知されません。
ハードウェアのまとめ
この時点で、特定のハードウェアを合成し、高度な抽象化(C 言語でのプログラミング)に進むことができます。今後の実装や取り組みに向けて、ここで留意しておくべきことがいくつかあります。Microblaze プロセッサを使用することにした場合、大きな負担が伴います。Microblaze プロセッサには、ただ「増やす」だけでは済まないタイミング要件がいくつかあり、パフォーマンスに多大なオーバーヘッドがかかります。一方、バックプレーンリーダーとイーサネットモジュールの間にハードウェアのみの(プロセッサなし)インターフェイスを実装するにしても、Verilog でこれを(正しく)行うには大変な労力が必要で、さまざまな問題が発生しました。Microblaze システムは、プロセッサの抽象化を図ることで、ハンドシェイク、パケットバッファ、受信、送信、その他あらゆるものの要件すべてに対処しますが、パフォーマンスが犠牲になります。ただし今後、実際に製品化へと進み、プロセッサを不要にすることでコストを大幅に削減できれば、この問題は排除できる可能性があります。単一の FPGA チップか ASIC を製造すれば、XBus メッセージを簡単に UDP に送信できます。あるいは、より高速に動作するプロセッサを追加することにより、コンセプト実証のために外部から行った処理を(スレッドがもっとあれば)オンボードプロセッサに移して、フットプリント全体を削減できます。ここで設計に関して選択した決定のほとんどはコンセプト実証をうまく進めるためのものであり、製品化に向けて理想的な決定を行ったわけではありません。
ソフトウェアソリューション
新しいプロセッサのプログラミング
C 言語の領域に入る際に留意すべきことがあります。それは、ベアメタルプロセッサ(基本的にマイクロコントローラで動作)をプログラミングすることになるということです。
メインのシンプルさ
LWIP(IP スタック)を使用することでネットワーク作業に伴う複雑な処理に対応できるのですが、他にこれといったものはなく、人手がかかります。このように、かなり汎用的なセットアップ作業を行う必要があります。
ip_addr_t ipaddr, netmask, gw;
/* the mac address of the board. this should be unique per board */
unsigned char mac_ethernet_address[] =
{ 0xde, 0xad, 0xbe, 0xef, 0x13, 0x37 };
send_netif = &server_netif;
init_platform();
/* initialize IP addresses to be used */
IP4_ADDR(&ipaddr, 192, 168, 1, 10);
IP4_ADDR(&netmask, 255, 255, 255, 0);
IP4_ADDR(&gw, 192, 168, 1, 1);
lwip_init();
/* Add network interface to the netif_list, and set it as default */
if (!xemac_add(send_netif, &ipaddr, &netmask,
&gw, mac_ethernet_address,
PLATFORM_EMAC_BASEADDR)) {
xil_printf(“Error adding N/W interface\n\r”);
return -1; }
netif_set_default(send_netif);
/* specify that the network if is up */
netif_set_up(send_netif);
/* Set up our global PCB for UDP */
upcb = udp_new();
err_t err;
ip_addr_t remote_addr;
err = inet_aton(“192.168.1.255”, &remote_addr);
…
err = udp_bind(upcb, &ipaddr, 0);
…
err = udp_connect(upcb, &remote_addr, 13370);
…
エラー処理は説明を簡略にするために省いていますが、初期作業では単に、LWIP スタックのセットアップ、MAC アドレスと IP アドレスの定義、送信用のインターフェイスの設定を行っています。ほかに、送信先も設定します。ここでは、192.168.1.X ネットワーク経由でブロードキャストします。これを選んだのは、テスト時の設定がシンプルで、後でユニキャストアドレスに変更できるからです。
初期作業を終えたら、メインのインポート部分に進みます。
// EXPERIMENTAL: This size could possibly not be enough?
packet = pbuf_alloc(PBUF_TRANSPORT, 0x400, PBUF_RAM);
/* now enable interrupts */
platform_enable_interrupts();
/* receive and process packets */
while (1) {
}
このコードの処理内容は、割り込みを処理し続けることによってプロセッサが停止し、(少なくとも LWIP を使用する前は)UDP パケットのゼロコピー送信が可能になり、バックプレーンの速度に追いつくパフォーマンスが実現するというものです。設定したサイズのパケットバッファを 1 つ割り当てて、毎回パケットを取得するたびに、そのバッファを再利用します。割り込み時にこのバッファにデータが保存され、同時に送信されます。割り込みを有効にすると、プロセッサが待機状態になり、各割り込みに対処するとともに永久にループします。
割り込み
この XBus 処理の本当のすごさは、XBus メッセージを送信する準備ができたら、割り込みを使用して Microblaze プロセッサが実行中の処理を中断し、メッセージが送信されるようにすることにあります。これ以外に、プロセッサがメッセージの送信に取りかかるまでにメッセージが上書きされないようにし、また同じメッセージが重複して送信されないようにする方法はありません。こうして、データをバッファに書き込むとともにメッセージを送信します。
platform_init() では、platform_setup_interrupts() を呼び出して、動作中のプロセッサに対する割り込みを設定します。この関数は、Microblaze プロセッサに対する割り込みコントローラの初期化と起動を行います。この初期化に platform_setup_backplane(intcp) を挿入します。
platform_setup_backplane(intcp) 内で必要な操作は、BackplaneReader_AXIL 周辺機器に関連付けられている割り込みに対応したカスタムの割り込みハンドラを登録することだけです。このハンドラ自体は次のように極めて簡単なものです。
void BackplaneInterruptHandler(void *CallbackRef) {
// We need to get the size of the buffer so that we can set the pbuf size accurately, this reduces work
// on the recv end.
u32 size = BACKPLANEREADER_AXILITE_mReadReg(0x44a00000, 63*4) + 1;
if (size == 0) {
return;
}
// We don’t want to copy anything, just grab the memory directly where it is, this significantly reduces
// time to send the packets.
packet->payload = (void *) 0x44a00000;
packet->tot_len = size * sizeof(int);
packet->len = size * sizeof(int);
err_t err = udp_send(upcb, packet);
if (err != ERR_OK) {
xil_printf(“send error”, err);
return; }
}
このハンドラは、できる限り高速に動作するように設計する必要があります。というのは、割り込み時に Microblaze プロセッサが自身を一時停止するからです。その結果、メモリリークやデータ損失などの問題が発生することがあります。元々、この設計には pbuf の割り当てと解放が含まれていましたが、処理速度が遅すぎて次の割り込みが発生する前に完了できませんでした。そのためにメモリリークが発生して、新たに届いた XBus メッセージにプロセッサが対応できなくなっていました。
この設計では、memcpy や割り当ては必要ありません。メインで割り当てられているグローバル pbuf を再利用し、ペイロードポインタ、tot_len フィールド、len フィールドを変更するだけです。これらの値を取得するために、周辺機器のメモリマップ領域内にある最後のレジスタを読み取ります。特定のメッセージが保存されているメモリマップレジスタの数を保持する特別なレジスタがあるからです。これにより、レジスタの初期化について気にする必要がなくなるほか、データの正確な長さを把握できるので余分なデータを無視できるようになります。
データの長さを把握したら、UDP pbuf 内の適切なフィールドに値を入力し、パケットを送信するだけです。他のことはすべて、LWIP が処理します。これにより、データのコピーを回避できるほか、処理速度も非常に速くなるので、(少なくとも目に付くような量の)コードを一時停止しなくても済むようになります。
ソフトウェアのまとめ
現時点で、このアプローチにはバグがいくつかあります。最大のバグは、バックプレーンからのデータの切り捨てです。これが起きるのは、メッセージモジュロ 4 がゼロでない場合だけです。メッセージの大部分は 4 バイト境界に配置されているため、これはコンセプト実証の範囲外として扱いました。また、どの XBus メッセージにも 8 バイトのフッターがあり、何らかのチェックサムであると想定されるので、現在処理に必要とされる「重要な」データは切り捨てないようにします。そのためには、メッセージの末尾に 1 ~ 3 バイトがある場合、レジスタ内の関連性のないデータを初期化した後で、メモリマップレジスタの適切なオフセットにデータを移動する機能をハードウェア実装に追加する必要があります。
XBus バックプレーントラフィック分析
データバスの調査
データを抽出するための最初のソリューションは、完璧にはほど遠いものでした。Saleae を使用して、重要なデータピンのそれぞれでデータをキャプチャし、それを CSV にエクスポートしました。この CSV には各行の遷移と遷移した時間が含まれています。この情報を使用すると、遷移のたびにビット数を抽出して、ASCII データ(1 と 0)に変換し、さらにそれをバイナリデータに変換できます。これにより、早い段階でデータの概要にアクセスできます。ビットパターンを簡単に検索し、データのキャプチャに関する問題をトラブルシューティングできます。それと同時に、現実的なソリューションを模索します。これはうまく機能しますが、リアルタイムのモニタリングやアラートに対する合理的なアプローチではありません。とは言え、複雑なソリューションへの取り組みをチェックする場合には便利です。
より持続可能な方法でのスニッフィング
XBus メッセージをバックプレーンから取り出し、FPGA デバイスからネットワーク経由で送信できるようになったので、今度はそのトラフィックを取得して Snort に取り込む方法を見つける必要があります。この PoC では(時間的な制約もあり)、XBus 内に含まれている UMAS メッセージを抽出しています。ただし、抽出はすべて FPGA での処理後に行われるので、今後の XBus の分析は可能です。UMAS メッセージを抽出したら、Snort の検査インターフェイスでトラフィックが含まれている TCP 接続をスプーフィングして、Snort 3 が備える検出とアラートの機能をすべて利用できるようにします。
FPGA からのトラフィックの受信
FPGA がバックプレーンから XBus メッセージを読み取り、UDP を介してそのトラフィックをブロードキャスト送信します。メッセージに対して何らかの処理を行う場合は、事前にそのメッセージを解析する必要があります。
高速処理
FPGA は、1 秒あたり約 1,143 UDP データグラムでトラフィックを送信しています。残念ながら、これではあまりにも速すぎて、Python が通常の recv ループでビットを処理できません。この問題を解決するため、マルチプロセッシング プラグインを使用して、複数の recv ループをスピンアップし、その結果を共有キューに保存するようにしました。プロセスの数が 10 程度であればこれでうまくいくようですが、それ以上増えると、顕著な効率向上は見られません。
残念ながら、通信速度が速いと完全には問題を修正できませんが、PoC にはこれで十分です。まだ問題が残っていますが、より完全なハードウェアソリューションか、コンパイル済みメッセージプロセッサがあれば、解決できる可能性があります。
FPGA メッセージの解析
FPGA から送信されたトラフィックは、次の 2 つのいずれかの状態で届きます。
- 1 つの XBus メッセージ
- 関連するひとまとまりの XBus メッセージ
UDP メッセージが届いたときの状態に関係なく、そのメッセージのエンディアンを入れ替える必要があります。Microblaze による制限のため、メッセージは 4 バイトのリトルエンディアンブロックで送信されます。メッセージを正しく解釈するには、ブロック内のデータを以下のように反転させる必要があります。
Raw UDP Message
——————————————————
0000 26 84 75 05 f9 05 27 04 00 15 08 36 06 59 0c 0a
0010 00 00 00 1b 00 01 64 08 d9 d9 7f 00 03 00 5a 06
0020 00 a2 11 03
“`
“`
Endianness-Fixed UDP Message
——————————————————
0000 05 75 84 26 04 27 05 f9 36 08 15 00 0a 0c 59 06
0010 1b 00 00 00 08 64 01 00 00 7f d9 d9 06 5a 00 03
0020 03 11 a2 00
この先、UDP メッセージを参照しているところでは、エンディアンを修正した後のメッセージを参照しています。RAW 形式では、パターンを見つけるのは簡単ではありません。
FPGA から届いた UDP トラフィックに XBus メッセージが 1 つだけ含まれている場合は、それ以上トラフィックを処理する必要がなく、UMAS 抽出に進むことができます。ひとまとまりの XBus メッセージが含まれている場合は、そのメッセージを分割してから、UMAS メッセージを抽出する必要があります。
ここでは、実際の XBus トラフィックを使用して UMAS メッセージを抽出する方法を説明します。任意の XBus メッセージを分割する方法を本格的に分析したわけではありません。代わりに、UMAS データが含まれているメッセージを分割する方法に焦点を当てています。
分析の結果、どの UMAS メッセージでも最初の(唯一の)XBus メッセージにフラグ b’\x08\x64\x01\x00\x00\x7f が含まれていることが判明しました。幸い、このフラグは UMAS に関連しない XBus メッセージには含まれていないようです。これを利用すると、このフラグが含まれているメッセージだけを継続的に処理し、他のメッセージは破棄できます。なお、関連性のある XBus メッセージは常に単一の UDP メッセージとして送られてくるため、UMAS メッセージの後半部分が失われることはありません。
FPGA から届いたメッセージに XBus メッセージが 1 つ含まれ、そこにさらに 1 つの UMAS メッセージが保持されている場合、ペイロードは以下のようになります。
Endianness-Fixed UDP Payload
——————————————————
0000 05 75 84 26 04 27 05 f9 36 08 15 00 0a 0c 59 06
0010 1b 00 00 00 08 64 01 00 00 7f d9 d9 06 5a 00 03
0020 03 11 a2 00
このメッセージタイプを解析することで、UMAS メッセージを抽出できます。
| フィールド | サイズ(バイト単位) | 値 | 説明 |
| メッセージタイプ | 0x01 | 05 | メッセージのタイプを示すバイトのようです。このバイトについてあまり詳しいことはわかりませんが、常に 0x04 か 0x05 になっています。 |
| 不明 | 0x09 | 75 84 26 04 27 05 F9 36 08 | 不明なバイト |
| XBus ペイロード長 | 0x01 | 15 | XBus ペイロードのバイト数からこのフィールドの値を引いた値を示す 1 バイトフィールド。
UMAS メッセージの最初の XBus 部分では、この値に UMAS 以外のデータが含まれます。一方、その同じメッセージの後続の XBus 部分では、ペイロードは完全に UMAS データとなります。 |
| 不明 | 0x01 | 00 | 不明なバイト |
| 送信元 | 0x01 | 0A | 送信元モジュールを示すバイト。後でこのバイトを使用して IP と MAC を作成します。 |
| 宛先 | 0x01 | 0C | 宛先モジュールを示すバイト。後でこのバイトを使用して IP と MAC を作成します。 |
| 不明 | 0x06 | 59 06 1B 00 00 00 | 不明なバイト。 |
| UMAS フラグ | 0x06 | 08 64 01 00 00 7F | UMAS メッセージの最初の XBus の部分に常に出現し、それ以外には出現しない 6 バイト。 |
| 不明 | 0x03 | D9 D9 06 | 不明なバイト。 |
| UMAS メッセージ | 可変 | 5A 00 03 | UMAS メッセージ、または複数の XBus メッセージに分割した後の UMAS メッセージの先頭部分。
このサイズは、「XBus ペイロード長」フィールドによって決まります。
この例の場合、「XBus ペイロード長」フィールドは 0x15 です。この値は、このフィールドのサイズに、「XBus ペイロード長」フィールドまでのすべてのフィールドを加えた値で構成されています(「XBus ペイロード長」フィールドの値は含まれません)。
UMAS メッセージが複数の XBus メッセージに分割されている場合、それらのメッセージの XBus ペイロード全体に残りのデータがあります。 |
| 不明 | 可変 | 03 11 A2 00 | 不明なバイト(おそらくフッター)。チェックサムや類似の機能の可能性があります。このサイズは、FPGA 側の前提を考えると結局は可変となり、信頼できません。 |
FPGA から届いたメッセージに複数の XBus メッセージが含まれ、そこにさらに UMAS メッセージが全体として 1 つ保持されている場合、ペイロードは以下のようになります。
Endianness-Fixed UDP Payload
——————————————————
0000 04 05 00 27 04 26 05 ea 98 08 43 00 0c 0a 70 06
0010 1b 00 00 40 08 64 01 00 00 7f d9 d9 06 5a 00 fe
0020 02 0d 00 00 a2 9b 02 00 00 02 04 7c 00 05 ef de
0030 04 05 08 27 04 26 04 f8 94 08 0d 00 00 a2 9b 02
0040 00 00 02 0e 00 0d 0a 03 e4 07 02 0e 08 0c 0a 03
0050 e4 07 02 00 00 00 08 50 72 6f c8 a4 00 17 bf 78
0060 04 55 90 27 04 26 05 bc 86 08 6a 65 63 74 00 43
これは、以下の XBus メッセージに分割されます。
Endianness-Fixed UDP Payload Split on XBus Messages
——————————————————
XBus Message 1
——————————————————-
0000 04 05 00 27 04 26 05 ea 98 08 43 00 0c 0a 70 06
0010 1b 00 00 40 08 64 01 00 00 7f d9 d9 06 5a 00 fe
0020 02 0d 00 00 a2 9b 02 00 00 02 04 7c 00 05 ef de
XBus Message 2
——————————————————-
0000 04 05 08 27 04 26 04 f8 94 08 0d 00 00 a2 9b 02
0010 00 00 02 0e 00 0d 0a 03 e4 07 02 0e 08 0c 0a 03
0020 e4 07 02 00 00 00 08 50 72 6f c8 a4 00 17 bf 78
XBus Message 3
——————————————————-
0000 04 55 90 27 04 26 05 bc 86 08 6a 65 63 74 00 43
この例の場合、XBus メッセージ 1 は単一メッセージと同じように解析されます。XBus メッセージ 2 には、XBus ペイロードセクション全体に UMAS メッセージデータが含まれています。XBus メッセージ 3 のヘッダーは前の 2 つと同じですが、このメッセージに含まれる残りのバイト数は「XBus ペイロード長」フィールドの値に基づいて制限されています。その後には、信頼できない長さのフッターがあります。
この状態になったら、メッセージを渡して UMAS を抽出できるようになります。
XBus からの UMAS の抽出
複数の XBus メッセージがひとまとまりになっていて、そこに UMAS メッセージが 1 つ含まれている場合、そのひとまとまりを分離すると UMAS メッセージ全体を抽出できます。XBus メッセージが 1 つのみ存在する場合は、UMAS メッセージは前述のように UMAS メッセージフィールドから抽出できます。これは、複数の XBus メッセージに対処するときにはさらに複雑になります。
上記のひとまとまりの例を使用して、以下の XBus メッセージを分析してみます。
Endianness-Fixed UDP Payload Split on XBus Messages
——————————————————
XBus Message 1
——————————————————-
0000 04 05 00 27 04 26 05 ea 98 08 43 00 0c 0a 70 06
0010 1b 00 00 40 08 64 01 00 00 7f d9 d9 06 5a 00 fe
0020 02 0d 00 00 a2 9b 02 00 00 02 04 7c 00 05 ef de
XBus Message 2
——————————————————-
0000 04 05 08 27 04 26 04 f8 94 08 0d 00 00 a2 9b 02
0010 00 00 02 0e 00 0d 0a 03 e4 07 02 0e 08 0c 0a 03
0020 e4 07 02 00 00 00 08 50 72 6f c8 a4 00 17 bf 78
XBus Message 3
——————————————————-
0000 04 55 90 27 04 26 05 bc 86 08 6a 65 63 74 00 43
いずれのメッセージも、既知のフィールドに分割できます。すでに説明したフィールドのいくつかが、最初のメッセージ以外にはないことに留意してください。
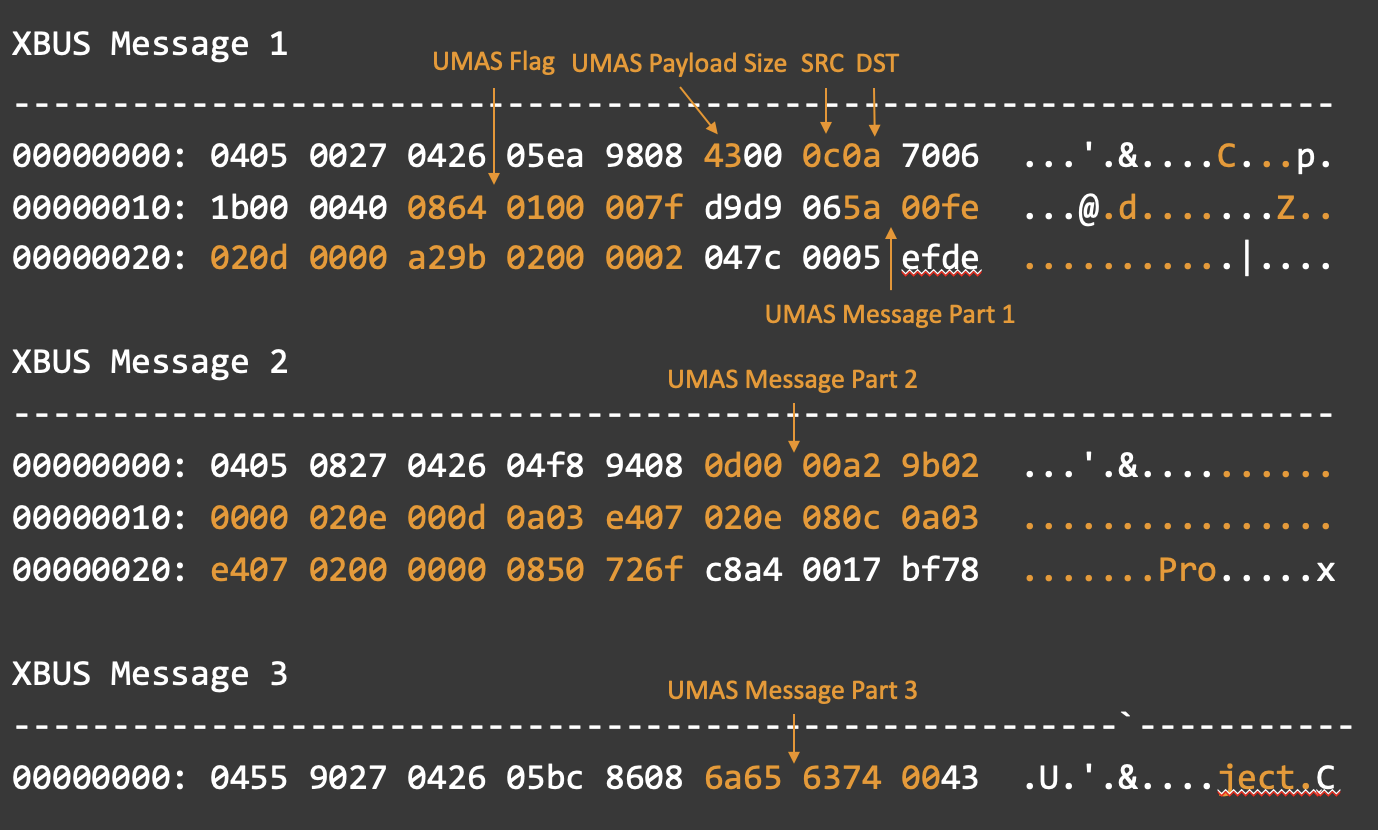
レイアウトを可視化すると、目的の情報が UMAS メッセージのどこにあるのか、以前よりも簡単に特定できるようになりました。以下の前提に従っています。
- 最初の XBus メッセージには常に UMAS フラグが含まれている。
- 長さフィールドは、常に最初の XBus メッセージのオフセット 0x0A にある。
- 長さフィールドの値には、常に UMAS メッセージの合計サイズと、最初のパケットにある UMAS 以外の XBus ペイロード情報の 0x12 バイトが含まれている。
- UMAS 関連の XBus パケットの最大サイズは 0x30 バイトで、そのうちの 0x20 は XBus ペイロードのために予約されている。
- 最後の XBus メッセージにあるフッターフィールドは信頼できない。
抽出が正しく行われた場合、以下のような UMAS メッセージが残ります。
00000000: 5a00 fe02 0d00 00a2 9b02 0000 020d 0000 Z……………
00000010: a29b 0200 0002 0e00 0d0a 03e4 0702 0e08 …………….
00000020: 0c0a 03e4 0702 0000 0008 5072 6f6a 6563 ……….Project.
00000030: 7400
接続のスプーフィング
正しくフォーマットされた UMAS メッセージを入手したら、そのトラフィックを Snort に取り込む方法が必要です。これを手っ取り早く実現する方法は、このトラフィックが含まれている TCP ストリームを作成して、Snort がリスニングしているインターフェイスを通るようにすることです。メッセージが送信されたように Snort に認識させるだけでよく、実際にメッセージを送信する必要はないので、Scapy を使用して全体の通信データを作成できます。
残念ながら、送信元や宛先の実際のアドレスはなく、あるのはシングルバイトの識別子だけです。この情報を保持したいので、その値をデバイスの MAC アドレス(DE:AD:BE:EF:00:XX)の最後のバイトおよび IP アドレス(192.168.0.XXX)の最後のオクテットとして使用します。
ループバックを介してこのトラフィックを送信するとともに、Snort が同じインターフェイスをリスニングするようにすると、Snort でトラフィックを処理できるようになります。
なお、もっと良い方法で Snort 3 にこのデータを取り込むことができます。現実の実装では、そうした方法を使用することをお勧めしますが、その機能の開発はこのプロジェクトの範囲外でした。
Snort 3 でのトラフィック検出
この接続では標準のイーサネットトラフィックが伝送されるため、Snort3 に情報を取り込むために特別なことをする必要はありません。単に、Snort センサーを適切なインターフェイスに接続するだけです(詳細は Snort3 ドキュメントを参照)。 ![]()
注意事項
Snort に XBus トラフィックを取り込むためにここで採用しているアプローチは、プロジェクトに時間の制約があるために選択したものです。これよりもはるかに効率的な方法で、Snort にこのタイプのトラフィックを取り込み、正しく復号することができます。ただし、その開発にかかる時間はプロジェクトの範囲外と判断しました。
コンセプト実証
影響
セキュリティチームがバックプレーンを流れるすべてのトラフィックを正しくモニタリングできないことが、今日の OT ネットワークが抱える問題です。独自仕様のプロトコルは、以前は詳細が不明でしたが、今では最新のツールによって情報が開示され、復号されるようになりました。こうしたプロトコルの中には通信先のデバイスに重大な変更を加えられるものがあるので、攻撃者も正規オペレータもますます注目するようになっています。バックプレーンネットワークを流れるあらゆるものを可視化できないと、Snort3 といったモニタリングツールでも潜在する攻撃を見逃すことになります。
セキュリティベンダーだけでは、この問題を解決できません。シスコなどのグループはこのタイプのモニタリングを実行するハードウェアを構築できますが、サードパーティのモジュールに接続することによるお客様保証への影響は無視できません。このタイプのモニタリングの場合、本当の意味で選択肢となるためには、お客様の需要をきっかけに対話が進む必要があります。PLC ベンダーには、Badgerboard が目指していることを実現する製品を作るだけの能力も製品専門知識もあります。後は、お客様の後押しが必要なだけです。
技術情報
- Badgerboard S4x24 トーク
- 近日提供予定
- Badgerboard ソースコード
- Weaselboard
- Snort 3 の使い方
本稿は 2024 年 03 月 05 日に Talos Group
のブログに投稿された「Badgerboard: A PLC backplane network visibility module