
- セキュリティツールは時として非常に大量のデータを生成します。そうした膨大なデータは優秀な人材を抱えるハイテク企業でも扱いに苦労します。
- そこでセキュリティチームに役立つのが、ビッグデータを処理できる Spark などのツールです。
- 本稿では、類似イベントのクラスタリング手法を使った、大規模なデータセットに対する脅威ハンティングについて手順を追って解説します。この方法の特徴は、検索スペースを削減し、追加のコンテキストを取得できることです。
はじめに
Cisco Talos では、毎日 150 万の新しいマルウェアを分析しています。このような膨大なデータセットを実用的な情報に変換するには、ツールによりデータを自動処理したうえで、人間の直感により特異なデータを選ぶという工夫が必要です。
人間が処理できる情報の量には限りがあります。最も優秀な人材を抱える組織であっても、最新のセキュリティシステムから生成される膨大な量のデータには処理に苦労しています。こうした理由から、大量のデータを小規模な情報に変換できるデータ処理ツールが必要とされています。小規模な情報であれば、必要に応じて手動で処理できるからです。
そうしたツールの一例が、ビッグデータ処理ツール/ライブラリの Apache Spark![]() です。今回はこのツールを使用して、大量の不審イベントを小規模な(人間でも分析可能な)グループに分類し、新たな脅威を探す手法について手順を追って解説します。組織の規模を問わず、この手法を使えば大量のセキュリティイベントを効率的に処理できます。さらに、既存のツールの改善点を見つけ出すためにも役立つでしょう。
です。今回はこのツールを使用して、大量の不審イベントを小規模な(人間でも分析可能な)グループに分類し、新たな脅威を探す手法について手順を追って解説します。組織の規模を問わず、この手法を使えば大量のセキュリティイベントを効率的に処理できます。さらに、既存のツールの改善点を見つけ出すためにも役立つでしょう。
クラスタリングデータ
ここでは、Cisco Talos の独自ツールで生成した不審イベントログのデータセットを基に、クラスタを作成する手法について解説します。今回の手法では、類似しているが同一ではないイベント / イベントシーケンスごとにクラスタが作成されます。ここでは「類似」レベルで探せれば十分です。グループ化する条件を「完全に同一」にする必要はありません。つまり、ユーザ名、パス、大文字/小文字の区別など、わずかな点が違っても類似イベントとして分類されます。これにより、セキュリティイベントログの膨大なリストを、アナリストが処理できる小規模な類似イベントリストに変換できます。分類は必ずしも完璧ではありませんが、人間の処理には扱いやすくなります。さらに人間は、不完全なデータの処理に非常に優れています。
本稿では Talos の独自ツールで生成したデータを使用しますが、使う方法は一般的なものです。組織のサイズを問わず、Windows やセキュリティソリューション(SIEM、Cisco Secure Endpoint など)で記録されたログや、プロキシログの処理にお役立ていただけます。ご紹介する手法での要件は、利用可能な Spark クラスタと、Spark 対応メディアに保存されたデータ(クラウド上の CSV ファイルや JSON ファイル、大規模な物理ストレージシステムなど)のみです。
クラスタリング手法は他にも存在しますが、今回の手法は非常に膨大なデータに適した処理アルゴリズムを使用しています。また、さまざまなデータセットに簡単に適応できる汎用性があり、無料で便利な Spark ライブラリのみを使用しているという特徴もあります。
クラスタリング用データの準備
一連の流れの概念は、非常にシンプルです。各イベントを「トークン」セットに変換し、あるイベントから派生したセットと、他のセットとの類似性を比較します。これにより、微妙に異なっていても、類似性が最も高いイベントを見つけることができます。
各イベントの「トークン」は、例えるならば本の語句です。書籍を一連の語句に変換すれば、各語句の登場頻度に基づいて書籍をグループ化できます。この手法により、たとえば英語、スペイン語、ドイツ語といった基準で本を分類できます。より細かいクラスタリング条件を適用すれば、「マルウェア」、「コンピュータ」、「脆弱性」に言及する書籍のグループを、「ダンブルドア」、「ハグリッド」、「ボルデモート」に言及する別のグループと区別できます。
ただしクラスタリングを実行する前に、データを処理できるよう読み込んで準備する必要があります。
最初のステップは pyspark をロードし、いくつかの必要なライブラリをインポートすることです。

CountVectorizer![]() は機械学習パッケージ pyspark.ml の一部であり、多くの ML アルゴリズムで使用される形式にデータを変換します。MinhashLSH
は機械学習パッケージ pyspark.ml の一部であり、多くの ML アルゴリズムで使用される形式にデータを変換します。MinhashLSH![]() パッケージは、処理が必要なデータの量を削減し、類似イベントペアのセットを計算するために使用されます。graphframes
パッケージは、処理が必要なデータの量を削減し、類似イベントペアのセットを計算するために使用されます。graphframes![]() ライブラリは、Spark データフレームに基づく pyspark グラフライブラリです。
ライブラリは、Spark データフレームに基づく pyspark グラフライブラリです。
環境の準備ができたら、まずデータをロードし、その直後からデータの変換を開始します。最初のコマンドは次のとおりです。

最初の行では、Spark の read メソッドを使用してデータがパスから読み取られます。2 行目では short_description フィールドと argv フィールドを連結した関数セットが呼び出されます。次に各フィールドが英数字以外の文字で分割され、最後に「展開」されることで、1 単語につき 1 行が生成されます。最後の 3 行目では、システムにより単語がグループ化されます。その結果、コマンドラインで使用された単語の配列がエージェントごとに生成されます。
次の図は、システムとコマンドを単語に分解した結果です。

正しい形式でデータをエンコードした結果
機械学習ライブラリの大半のアルゴリズムでは、特定の形式に沿ったデータ入力が必要です。ここで使う Minhash アルゴリズムには、特徴の数値ベクトルが必要です。そのため CountVectorizer 関数を使用して、各イベントで記録された一意の単語をすべて列に変換します。イベントの各行の数字は、各単語の出現回数を表します。たとえば、次の表のように、各イベントに含まれる単語が 1 つだけであるとします。
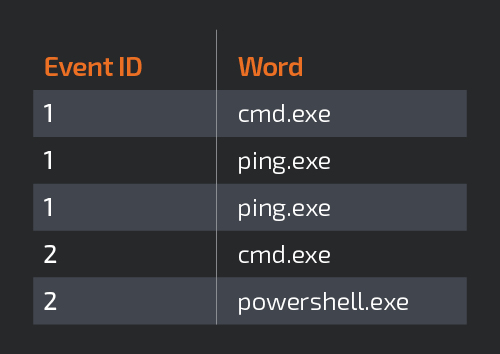
CountVectorizer エンコーダで生成したイベントテーブルは、次のようになります。

上記の tocluster データフレームに対して次のコードを使うことで、「features」という列をデータフレームに追加し、データを数値イベントのベクトルに変換します。

その結果、膨大な量のベクトルが生成されます。こうした大量の情報を処理するには、膨大なコンピューティング能力が必要になります。しかし幸いなことに、Locality Sensitive Hashing を使えばこの問題を解決または緩和できます。これについては次のセクションでご説明します。
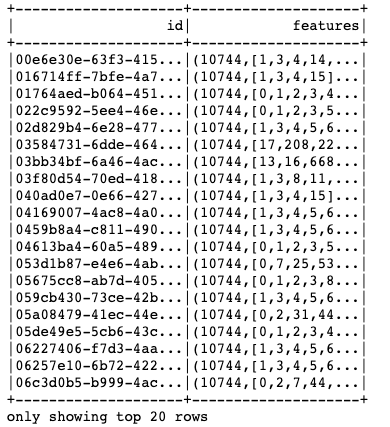
次の図は、ここで生成されたデータフレームです。「特徴」の列には、各単語の登場カウントを示す数値ベクトルが含まれています。
MinHash LSH
Locality Sensitive Hashing(LSH)はかなり複雑なトピックです。ただし Spark には優れた機械学習ライブラリがいくつか用意されているため、LSH に詳しくないユーザーでも LSH をフル活用できます。
他のハッシュアルゴリズムとは異なり、LSH はハッシュ衝突を最小化するのではなく、最大化しようとします。これによりイベントごとに LSH ハッシュのセットを計算できます。類似イベントをクラスタ化するために使用する、異なるイベント間の共通の単語/特徴の数は、共通ハッシュの数で表されます。これにより膨大な量の「特徴」リストに心配する必要なく、少数のハッシュのみを使用して類似度を計算できるのです。
Minhash LSH では、多数のシステムで分散処理を行う Spark の機能を活用して、非常に大規模なデータセットに対して類似性を計算できます。分散処理を行わずにシンプルな機械学習ライブラリを使用するだけでは、このような情報をクラスタ化することがほぼ不可能です。
次のコードは MinHash LSH を使用するセクションです。

この例では 10 個のハッシュを使用しました。レコードごとに計算されるハッシュの数、つまり処理時間と精度の間にはトレードオフの関係があります。ハッシュが多いほど正確な結果が返されますが、処理時間が長くなります。ハッシュが少ないほど精度は低下しますが、処理時間が短くなります。
複雑な計算に基づいて最適なバランスを選ぶこともできますが、手動での脅威ハンティングでは、少し試行錯誤を繰り返せば十分な数のハッシュが得られます。
次の図は、データフレームとその結果のハッシュを示しています。ご覧のように、巨大なベクトルではなく、分析する必要がある各行の長さが 10 に抑えられています。

類似性の算出
イベント間の類似性を算出する手法は多数あります。今回はイベント間の Jaccard 距離を計算することで類似性を判断します。 この計算方法では、A と B に共通する単語の数を計算し、共通していない単語の数で割ります。
すべてのイベント間で類似性を計算するコードは次のとおりです。

クラスタ化する前に、2 件のイベントの類似性を判断する必要があります。今回はイベント間の最大 Jaccard 距離として 0.2 の値を使用します。ゼロは完全に同一のイベントを、1 は完全に異なるイベントを意味します。
イベント間の値を選択してデータを準備したら、クラスタの品質を定義する必要があります。ここでの値が小さすぎると、処理するクラスタが膨大になります。一方で値が大きすぎると、類似性の低いイベントがクラスタに含まれて品質が低下することになります。実際の値は、データセットの性質とクラスタリングの目的に基づいて決めます。繰り返しになりますが、役立つクラスタを作成するにはケースごとに試行錯誤が必要です。
次のテーブルは、類似ペアをグループ化した結果です。
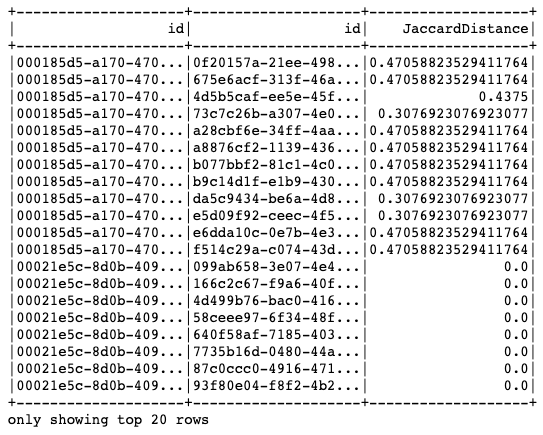
類似イベントをグループ化した結果
イベント間の類似度を計算すると、テーブルが相互に結合され、類似イベントがペアになった長いテーブルが生成されます。この中では、特定のイベントに類似したものを迅速に検索できます。しかし本当に必要なのは、類似コマンドのグループを絞り込むことです。
本稿で使う他の手法と同様に、絞り込む方法も複数ありますが、ここではグラフ内で接続されたポイントのコミュニティを特定します。
「Graphframes」という非常に強力な Spark ライブラリを使用します。このライブラリは、ノード(または頂点)と接点(またはエッジ)間の関係に対して既存のグラフアルゴリズムを実行することで、これらの関係から情報を抽出します。
今回は類似ノードのセットをグループ化するために、「Graphframes」の connectedComponents アルゴリズムを使用しました。次の図では、アルゴリズムの論理上の仕組みを解説しています。
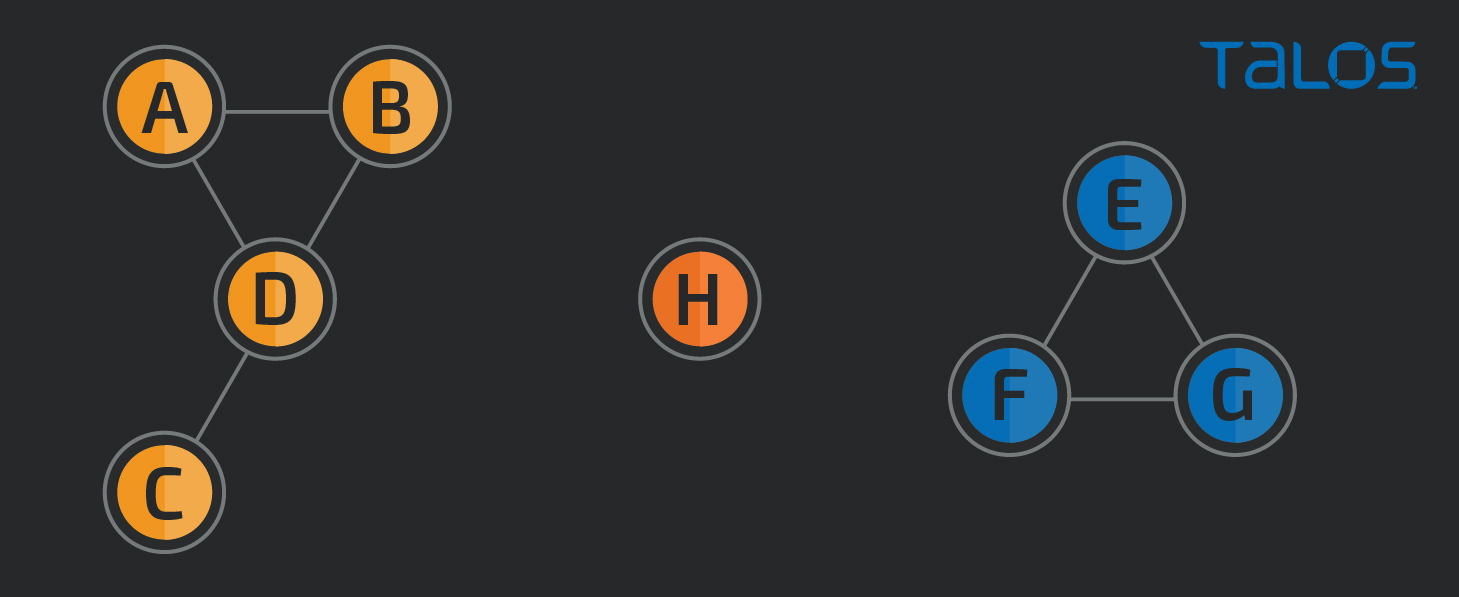
上の例では、2 つのコミュニティと 1 つのシングルトンがあります。すべてのノードが互いに類似しているため、青色のコミュニティは話がシンプルです。H ノードはそれ自体(H ノード)以外に類似がないため、1 つのコミュニティを形成します。そして最後に、黄色のコミュニティです。B と C に類似性はありませんが、コミュニティ内の他のメンバーとの間で類似性があるため、同じコミュニティに属していることになります。
次のコードは、前のステップで計算された類似イベントペアのコミュニティを計算します。

「v」変数には、すべてのノード ID が格納されます。また「e」変数には、前の手順で計算された同様のペアがすべて含まれます。これらの値を使用して GraphFrame オブジェクトを作成すると、Graph オブジェクトの connectedComponents メソッドを呼び出すだけでコミュニティを計算できます。
次のグラフは、これまでにご説明した方法で生成したコミュニティです。各ドットは 1 つのシステムを表します。予想どおり、コミュニティは相互に接続されていません。コミュニティには多様なサイズや色があります。いずれにせよ、最も重要な点はアナリストの調査対象を劇的に縮小できたことです。
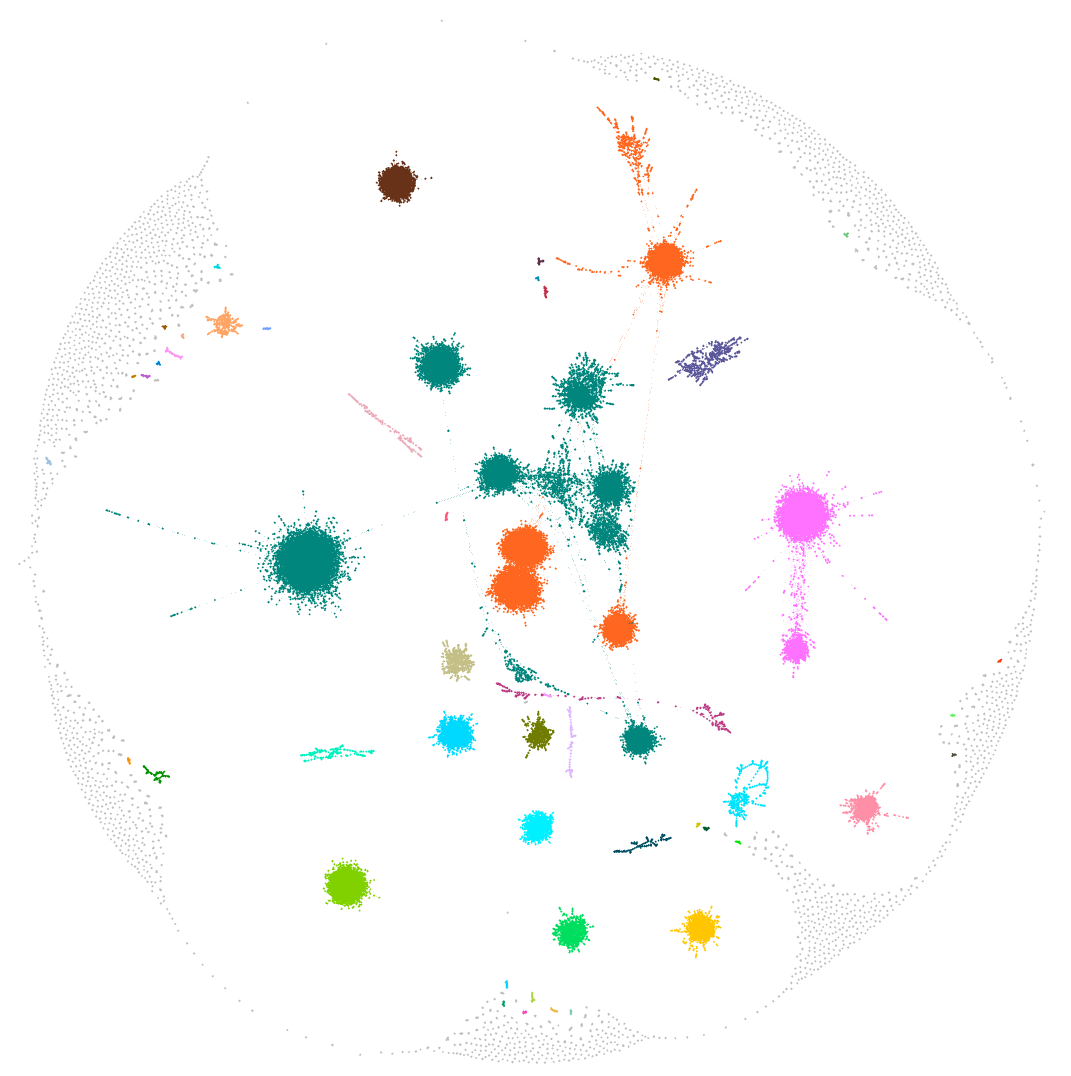
結果の分析
調査対象となる一連のクラスタを生成できたので、次は 3 つの代表的なクラスタサンプルを詳細に分析します。同時に、これまでご説明した手法の属性についても取りあげます。
各クラスタの特徴は次のとおりです。
- 1 番目のサンプルからは、1 つの奇妙な単語を共通して含む、類似しているが同一ではないイベントのコミュニティを発見した経緯がわかります。
- 2 番目のサンプルからは、クラスタリング用データを準備するために選んだ方法が、結果としてより良いクラスタの生成につながり、いくつかの攻撃パターンをシステムで分離できた仕組みについて理解できます。
- 3 番目のサンプルでは、最近発生したクラスタのみに限定することで、金銭目的の既知の攻撃者による振る舞いの変化を絞り込んでいます。
サンプル 1:Eris とは誰か?
次のクラスタは際立っていました。

最初の特異なのは、すべてのイベントに共通の文字列「–IsErik」が含まれている点です。必然的に、Erik とは誰か、その目的は何かという疑問が生まれます。
これらのイベントに関連する脅威を特定するのは非常に簡単です。「isErik」という文字列を Google で検索するだけでも、多数の関連記事が見つかります。それらの記事によると、既知の永続的なアドウェアファミリのアーティファクトが「isErik」です。
このクラスタで興味深い点(かつ、サンプルとして選択された理由)は、wscript.exe が実行するファイルの名前とパス、およびそれに続く 16 進値がイベントごとに異なることです。その理由は、イベント間の小さな違いを(無視せず)処理するという本来の役割をクラスタリングシステムが果たしているからです。
サンプル 2:Exchange サーバーでマイナーを非表示にする
次に、クラスタリング前にデータを選択して準備することの重要性を示す、一連のクラスタ化されたイベントを見てみましょう。
以下のクラスタ化されたイベントでは、一見すると不思議なことに、完全に異なる一連のコマンドが集約されています。

ただし、これは意図的なものです。ホストで実行されるすべてのコマンドが、コマンドラインイベントではなく、クラスタリングを開始したからです。そこで次に、ホスト上で同じコマンドを実行する単語をグループ化します。その結果としてクラスタには、類似コマンドのグループだけでなく、コマンドの組み合わせが類似したグループも含まれます。
これには 1 つの大きな利点があります。それはコンテキストです。異なる攻撃は個別にグループ化されます。いくつかのイベントがグループ間で類似している場合(たとえば、複数の互いに無関係な攻撃が同じ脆弱性をエクスプロイトしている場合など)でも、個別にグループ化されます。
では、クラスタからどのような種類の攻撃を読み取れるでしょうか。影響を受けたシステムの 1 つをさらに分析したところ、次の一連のイベントが確認されました。
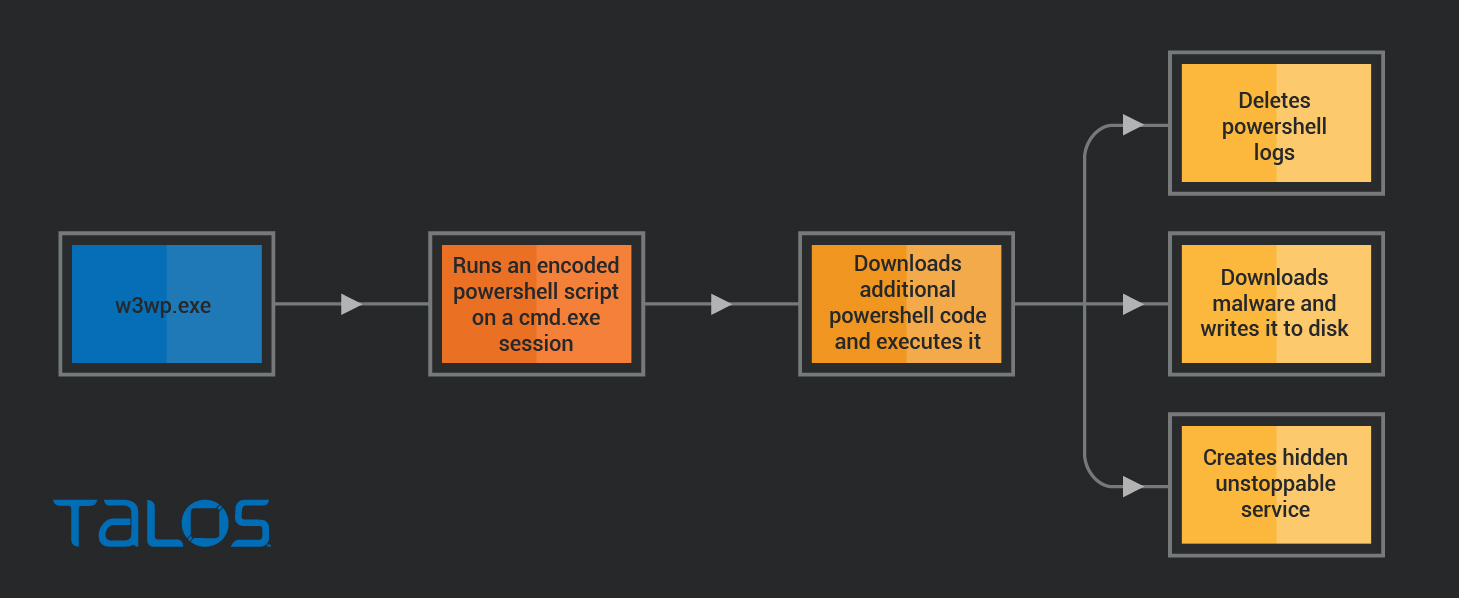
攻撃ベクトル
W3wp.exe による cmd.exe の実行は、最初に検出した、疑わしいアクティビティの兆候でした。W3wp は Exchange Server でも使用される IIS ワーカープロセスです。Exchange Server はインターネットに接続されているほか、最近になって多数の重大な脆弱性が公開され、エクスプロイトされています。これらの点を踏まえると、Exchange の脆弱性エクスプロイトが攻撃ベクトルであると考えられます。
インストールされたマルウェアの秘匿化と永続化
最初のコマンドは、base64 でエンコードされた PowerShell ペイロードを実行します。

このコマンドは最小限で難読化されています。https://122[.]10[.]82[.]109:8080/connect から何かをダウンロード、実行しようとしているほか、特定のユーザーエージェントを設定するための工夫が施されています。URL の自動分析を回避する狙いがあるのかもしれません。
追加の PowerShell コードは、残りのインストールと実行を担当します。
最終的なペイロードをダウンロードし、ファイルシステムに C:\ProgramData\Microsoft\conhost.exe として書き込みます。次の手順では、スクリプトが PowerShell のログを削除し、奇妙な権限設定で長いコマンドラインを実行することで、最終的なペイロードを Windows サービスとして登録します。

Google で検索するだけでも、これらのスクリプトが標準の Windows 管理ツールを利用してサービスを秘匿化または削除不可能![]() にしているという情報が見つかりました。
にしているという情報が見つかりました。
最終ペイロード
最後に、C:\ProgramData\Microsoft\conhost.exe ファイル(秘匿化されたサービスで使用されるものと同じファイル)が powershell.exe プロセスによって実行されます。このファイル(sha256:81A6DE094B78F7D2C21EB91CD0B04F2BED53C980D8999BF889B9A268E9EE364C)は、既知の暗号通貨マイナーである XMRig です。
ファイルが XMRig である点は、通信内容とプールログイン ID から確認できます。

攻撃自体は特に巧妙なものではありませんが、いくつかの特筆すべき手法により実行ファイルをシステム内で秘匿化・永続化しています。
興味深いのは、上の図のイベントがあまり類似していないにもかかわらず、グループ化されている点です。また、Exchange Server を狙って同様のアクセスコマンドを最初に使う攻撃がグループ化されていない点も注目に値します。この手法を調べることで、Exchange Server を狙って今起きている攻撃を幅広く特定できる可能性があります。
攻撃者「TA551」の特徴
最後のサンプルでは、限られた時間の中でクラスタリングを完了させるため、特定期間に起きた攻撃のみを探しています。今回はクラスタリングを過去数日間に絞っています。こうして最近のクラスタを調べた結果、既知の攻撃者によるマルウェア攻撃が目に留まりました。この攻撃についてさらに調査を進めたところ、攻撃者の通常のアクティビティにいくつかの変化が見られました。
調査ではまず、次のクラスタイベントのリストを確認しました。

このクラスタには、拡張子が JPEG の DLL ファイルをサービスとして登録する、不審なコマンドの組み合わせが含まれています。なお、IcedID はこの方法で配布されていることが知られています。しかし分析の結果、今回の攻撃で実際に配布されたマルウェアは BazarBackdoor であることが判明しました。また、攻撃者は TA551 である可能性が高いことも TTP から判断できます。
影響を受けたシステムの 1 つをさらに分析したところ、次の一連の関連イベントが明らかになりました。

攻撃ベクトル
ステップ 1 と 2 からわかるように、攻撃はファイルが添付された電子メールから始まりました。「request.zip」という名前の ZIP ファイルには、「official paper,08.21.doc」という名前の .doc ファイルが含まれています。この ZIP ファイルは、電子メール保護システムによる検出を避けるために暗号化されています。
マルウェアのインストール
.doc ファイルを開くと、マクロが .hta ファイルをディスクに書き込み、mshta.exe を使用して .hta ファイルの中身を実行します。
.hta ファイルの実体はダウンローダです。185[.]53[.]46[.]33 のサーバーに接続し、ファイルをダウンロードして .jpg ファイルとしてディスクに書き込み、regsrv32.exe を使用してサービスとして登録する機能を備えています。この .jpg ファイルは実際には .dllファイルであり、システムにバックドアをインストールする目的があります。
BAZARBACKDOOR
DLL(devDivEx.jpg)は実行されると、ホスト 167[.]172[.]37[.]20 に接続します。
OSINT により、同じホストに接続する類似した名前のサンプル(devDivEx.jpg)がいくつか見つかりました。これらはメモリ分析ルールに則って判別したものであり、.bazar のトップレベルドメインで DGA を使用していることも踏まえて、「Bazarbackdoor」と呼んでいます。これらのサンプルの例を以下に示します。
C96ee44c63d568c3af611c4ee84916d2016096a6079e57f1da84d2fdd7e6a8a3
f7041ccec71a89061286d88cb6bde58c851d4ce73fe6529b6893589425cd85da
TRICKBOT のインストール
Bazar に感染してから約 1 時間後に、svchost.exe プロセスが疑わしい更なるアクティビティを実行し始めました。
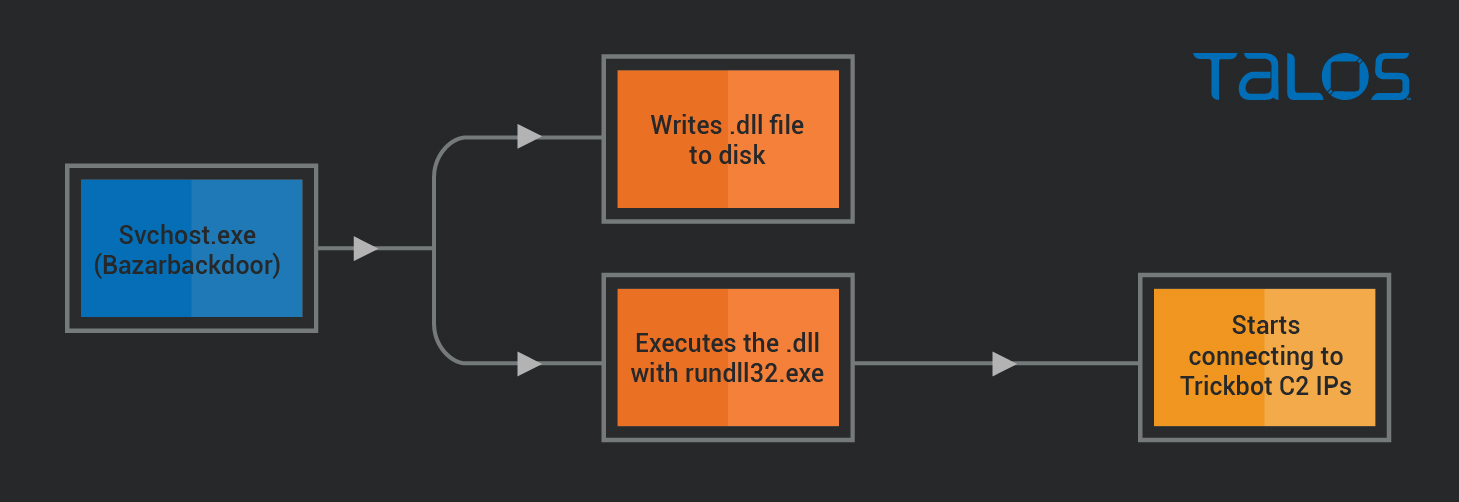
図に示すように、svchost.exe(Bazarbackdoor プロセスを実行していた)が DLL ファイルをディスクに書き込み、rundll32.exe を使用して起動します。数秒後、rundll32.exe のプロセスは IP アドレス 103[.]140[.]207[.]110、103[.]56[.]207[.]230、45[.]239[.]232[.]200 への接続を開始します。
これらの IP について OSINT を確認すれば、Trickbot C2 のものだと瞬時に把握できます。またパブリックサンドボックス実行レポートでは、各 IP に接続 している複数の Trickbot サンプルを確認できます。
攻撃者
攻撃者の TTP を調べたところ、「TA551」のそれと類似点がいくつか見つかりました。そのため、今回の攻撃者も「TA551」だと考えられます。以下にその例を示します。
- ファイル名「zip」が共通。
- 暗号化された ZIP ファイルが添付された電子メールを使用。
- Microsoft Word マクロを使用。
- ダウンローダとして HTA ファイルを使用。
- C:\users\public ディレクトリに、拡張子が .jpg の DLL ファイルを保存。
- JPEG ファイルをサービスとして登録。
- これらのアクティビティの実行に使用されるコマンド形式。
確認した TTP と IOC に一致するものがないか調べたところ、TA551 が最近 BazarBackdoor と Trickbot を配布し始めたことに関する、他の研究者のツイート![]() やブログ
やブログ![]() も見つかりました。
も見つかりました。
TA551 は、他の複数のマルウェアファミリ(Ursnif、Valak、IcedID など)を配布してきた経歴があり、金銭目的の攻撃者として知られています。TA551 が最近になって BazarBackdoor を配布し始めたことは、セキュリティ研究者にとって注目に値する変化です。この例は、最近発生したクラスタのみを選択することで、最近の脅威を特定できる方法を示しています。
まとめ
攻撃の頻度と影響力が増すなか、それに対抗できる最も強力な武器の一つはデータです。優れたセキュリティ体制とは、単一のソフトウェアやハードウェアソリューションを購入するだけで構築できるわけではありません。大切なのは保護レイヤを幾十にも重ねることですが、それでも攻撃を完全には防ぎきれません。データがなければ、既存の保護レイヤをすり抜けた可能性のある執拗な攻撃や過去の攻撃について、セキュリティチームが把握できません。
セキュリティツールは時に大量のデータを生成します。しかし幸いなことに、多少柔軟に大量のデータを処理できる優れたツールがいくつか存在しています。Spark は Talos が使うツールの一つです。非常に大規模なデータセットを処理できる柔軟性と対応力を備えているからです。このようなデータ処理ツールは、セキュリティチームの強力な味方となるでしょう。今回の記事では、特に役立つ使い方の一例をご紹介しました。本稿を参考にデータ処理の新しいアイデアを考え、データ処理ツールを使い始めていただければ幸いです。
本稿の IOC
例:
XMRig マイナー:
81A6DE094B78F7D2C21EB91CD0B04F2BED53C980D8999BF889B9A268E9EE364C
BazarBackdoor:
C96ee44c63d568c3af611c4ee84916d2016096a6079e57f1da84d2fdd7e6a8a3
f7041ccec71a89061286d88cb6bde58c851d4ce73fe6529b6893589425cd85da
ネットワーク IOC:
マイナーダウンローダの IP と URL:
122[.]10[.]82[.]109
https://122[.]10[.]82[.]109:8080/connect
Bazar バックドアのダウンロード元:
185[.]53[.]46[.]33
BazarBackdor C2:
167[.]172[.]37[.]20
Trickbot C2:
103[.]140[.]207[.]110, 103[.]56[.]207[.]230, 45[.]239[.]232[.]200
本稿は 2021 年 10 月 04 日に Talos Group
のブログに投稿された「Threat hunting in large datasets by clustering security events
Authors