

概要
IDA の静的リバースエンジニアリングでは問題が発生するケースが少なくありません。一部の値は実行時になって計算されるため、特定の基本ブロックで何が行われているのかを正確に把握するのが難しいからです。また、マルウェアをデバッグして動的分析を実行しようとすると、マルウェアがデバッグの試みを検知して動作を変えてしまうことも珍しくありません。そこで Cisco Talos は本日、マルウェアのリバースエンジニアリングをサポートする IDA 用プラグイン、Dynamic Data Resolver(DDR)1.0 のベータ版をリリースしました。マルウェアサンプルの実行時に動的に変化した値を解決できるよう、DDR ではインストルメント化の手法を採り入れています。1.0 リリースでは、いくつかのバグが修正されたほか、最新版 IDA に対応し、複数の新機能が追加されています。依存関係をすべて自動的に解決する新しいインストーラスクリプトも導入されました。
機能の概要
新機能の一覧については、「1.0 リリースの新機能」セクションをご覧ください。
コードフロートレース
どの基本ブロックが何回実行されたかが約 20 色に分けて表示されます。

図 1
検索可能な API 呼び出しログ
特定の命令(call や jxx など)による API アドレスへのアクセスがすべてログに記録されます。

図 2
検索可能な文字列ログ

図 3
動的な値の解決と自動コメント追加

図 4
バッファのダンプ

図 5
サンプルへのパッチ適用

図 6
パッチを含むデバッガスクリプトの自動作成

図 7
インストーラスクリプト

図 8
技術的な詳細
アーキテクチャと使用方法
図 9 に示すように、DDR のアーキテクチャはクライアント/サーバ型です。DDR IDA プラグインと DDR サーバは Python スクリプトです。DynamoRIO クライアントは C 言語で記述された DLL であり、DynamoRIO ツール drrun.exe によって実行されます。DLL ではマルウェアサンプルの挙動を実行時に分析・監視できるように、インストルメント化されています。IDA プラグインはフロントエンドとして機能します。通常はこのプラグインを介してすべての分析プロセスが制御されます。DynamoRIO クライアントのバックエンドで分析が終了すると、分析結果がプラグインに返されます。データは JSON 形式で返されるため、トラブルシューティングが容易で、サードパーティの Python スクリプトを使用して解析することもできます。

図 9
プラグインとサーバは、理論的には同一マシン上でも実行できますが、マルウェアサンプルを実行する場合は別々の PC で実行することを強くお勧めします。
ほとんどのケースでは、IDA 内の DDR メニューから開始する分析によって動的な値を収集できます。図 10 と図 11 に一般的なワークフローを示します。ただし、外部から物理的に隔離されたシステムや Python がインストールされていないシステムでマルウェアを実行する場合は、手動で分析を行い、DynamoRIO クライアントのみを実行することもできます。詳細については、以下の「特殊ケース」セクションを参照してください。ただし、前述のとおり、このような作業は通常不要です。

図 10

図 11
[IDAロギング出力(IDA logging output)] ウィンドウで、JSON ファイルがプラグインによって正常に受信されていること(図 10 の⑤)を確認した後、[値を取得(Get value…)] または [メモリを取得(Get memory…)] メニューからいずれかのオプションを選んでオペランドの動的な値を解決できます。
ベストプラクティスと重要な詳細事項
DDR を使用する前に下記の説明を必ずお読みください。
[IDA逆アセンブルビュー(IDA Disassembler View)] のコンテキストメニューを右クリックすると DDR プラグインの全機能にアクセスできます。当然ながら、IDA の動的な値を解決するには、先にトレースを実行しておくか、JSON ファイルを手動でロードしておく必要があります。DDR IDA プラグインメニューには、トレースを実行するためのオプションが何種類か用意されています。これらのオプションには、図 12 に示す [トレース(Trace)] メニューからアクセスできます。
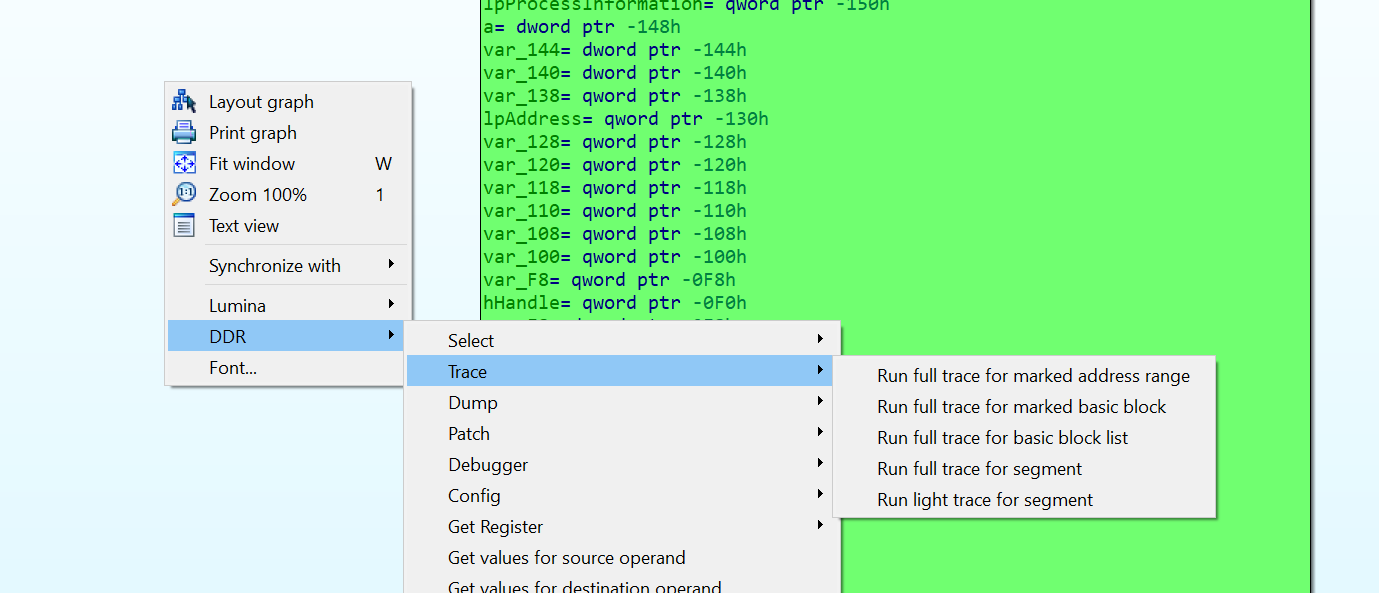
図 12
フルトレースオプションを選択すると、簡易トレースオプションよりもはるかに多くの実行時情報を収集できます。フルトレースは簡易トレースに比べて実行時間が大幅に長くなり、メモリ消費量も多くなります。簡易トレースで主に行われる処理はすばやいコードトレースです。ログには、実行時に実行された命令と、制御フローに関連する命令(call、jmp、ret など)の基本情報が記録されます。そのため、可能な限り多くの命令を実行してサンプルの動作を大まかに把握する必要がある場合は、簡易トレースを選択することをお勧めします。たとえば、実行回数に基づいてできるだけ多くの基本ブロックをハイライトしたり、サンプルによる API 呼び出しの概要を把握したりする必要がある場合は、簡易トレースを使用します。
ログに記録する命令の数は、[ログに記録する命令数の設定(Config/Set number of instructions to log)] メニューで設定できます。デフォルト値は 20,000 で、平均的な PC でも十分に処理できる値になっています。フルトレースは通常、特定の関数の詳細を調べる必要がある場合や、暗号ルーチンなどの特定の基本ブロックを分析する場合、あるいはすべての命令をオペランドまで詳しく確認する必要がある場合に実行します(例:[基本ブロックリストに対してフルトレースを実行(Run full trace for basic block list)])。通常の分析時間は 30 秒以下ですが、必要に応じて DDR 設定メニューの [APIのタイムアウト秒数を設定(Set number of seconds for API timeout)] で API のタイムアウト時間を延長できます。大規模なトレースでは、前述の手動分析を実行することもできます。ただし、ステップごとに情報を収集する必要がある場合は、タイムアウト時間を変更して大規模なトレースを長時間実行するのではなく、トレース対象のアドレス範囲または基本ブロックを絞り込むことを強くお勧めします。また収集データが大きくなりすぎないように、大規模なループセクションはスキップすることをお勧めします。
DDR の値解決機能では必ず、最後に実行した分析/トレースの JSON ファイルが使用されます。たとえば簡易トレースを実行した直後に [登録(Get Register)] メニューでレジスタ値の解決を試みても、簡易トレースではレジスタデータが収集されないため、レジスタ値は見つかりません。初めて DDR を使用する場合は、生成された JSON ファイルを確認し、トレースの種類(フルトレースか簡易トレースか)に応じてログに記録されるデータの違いを確認することをお勧めします。フルトレースを実行する場合は、確認が必要な基本ブロックのみ、または特定のコードエリアのみを指定することをお勧めします。
その他の機能
DDR でバイナリの実行時にパッチを適用する方法には次の 3 種類があります(図 6 を参照)。
- 命令を無効化する。
- EFLAGS を切り替えて jxx 命令などのコードフローの決定を変更する。
- 関数をスキップして独自の戻り値を返す。
上記のパッチ機能を使用すると、サンプルで使われている可能性がある分析回避機能を無力化できます。上記のパッチはいずれも、すべてのメニューオプションに適用されます。つまり [パッチ(Patch)] メニューで特定のパッチを設定すると、トレースを実行する際にもバッファのダンプを試みる際にもパッチが適用されます(以下を参照)。
ここで役立つのが DDR の第二の主要機能であるバッファの動的ダンプです。ダンプするバッファのサイズを確認するには、命令に含まれる特定のオペランドにマークを付けておきます。そうすると、サンプルの実行時に DDR がサイズ値を読み取ります。この方法は、バッファをダンプする際にバッファアドレスとプログラムカウンタアドレスを調べる必要がある場合にも使用できます。たとえば「mov [rsp+198h+var_108], rax」のような命令があり、バッファサイズが「rax」に格納されていることがわかっている場合は、「rax」にマークを付け、[ダンプ(Dump)] メニューから [マークしたオペランドを使用してバッファサイズを取得(Use marked operand to get buffer size)] エントリを選択します。その後、実行時にアドレスが格納されると予想されるオペランドについても同じ操作を繰り返します。最後に、ディスクにバッファをダンプする IDA の行(アドレス)にマークを付けます。3 つの値がすべて設定されている場合は、サンプルを実行すると DDR によってバッファがダンプされます。ディスクにダンプされたバッファは IDA マシンへ自動的にコピーされ、任意の場所に保存できます。VirtualAlloc によって割り当てられたバッファをダンプする別の例を図 13 に示します。
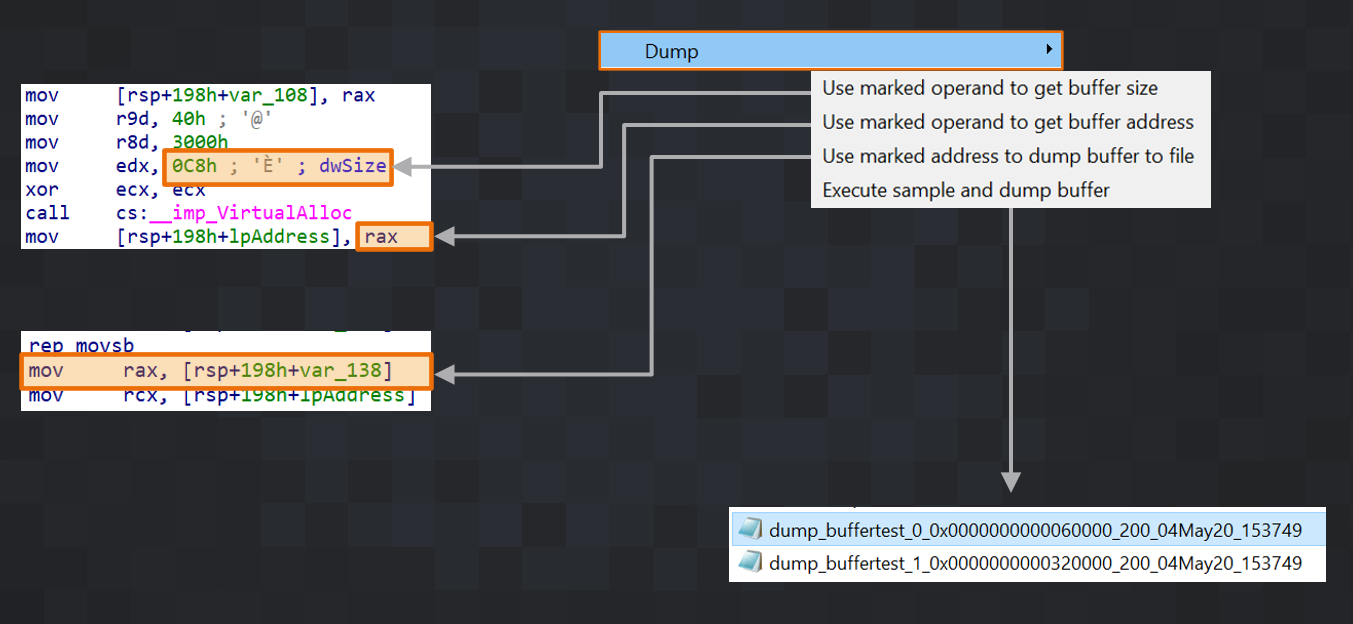
図 13
デバッガメニューには、外部ツールを使用してサンプルを操作する際に便利な機能が含まれています。設定済みのすべてのパッチを含む x64dbg スクリプトを生成することも、ハイライトしたプログラムカウンタアドレスに無限ループが追加されたサンプルファイルのパッチ適用済みバージョンを使用することもできます。後者の場合は、サンプルを実行するときに任意のデバッガを併用できます。[DDRサーバ出力(DDR server output)] ウィンドウには、無限ループで上書きされる前のバイト数が表示されます。これを使えばデバッガで簡単に再構築できます。
次のビデオでは、各種の DDR 機能と上で説明したワークフローの例を紹介しています。
最初は「ddr_installer\ddr_test_samples」ディレクトリにあるテストサンプルに対して DDR を実行することを強くお勧めします。実際のマルウェアに対して DDR を実行する前に、必ず DDR の動作の仕組みを必ず十分に理解してください。
上記のテストサンプルは、特定の特殊ケース(子プロセスや子スレッドが複数ある場合など)もトリガーします。詳細については「test_samples」ディレクトリにある README ファイルを参照してください。
特殊ケース:外部から物理的に隔離された環境での分析(オプション)
前述のとおり、DDR の DynamoRIO クライアント DLL は、コマンドラインから直接実行することもできます。最新リリースではいくつかの新機能が導入されているため、旧バージョンのようにコマンドライン引数を指定するのではなく、1 個の設定ファイルが使用されます。ddr_server.py のロギング出力を確認する前に、IDA 内から DDR コマンドを実行して構文を確認できます。以下に具体例を挙げて説明します。
<DYNAMORIO_INSTALL_PATH>\bin64\drrun.exe -c “<DDR_INSTALL_PATH>\ddr64.dll” -c “<DDR_INSTALL_PATH>\samples\<SAMPLE_NAME>.cfg” — “<DDR_INSTALL_PATH>\samples\buffertest.exe”
< SAMPLE_NAME >.cfg ファイルは、すべての DDR クライアント設定が保存されたファイルです。また docs ディレクトリには、コメント付き設定ファイル sample_config.cfg があります。IDA 内からコマンドを実行すると、上の例のように、ddr_server.py スクリプトによって CFG ファイルが samples ディレクトリに保存されます(デフォルトの保存先は C:\tools\ddr\samples)。CFG ファイルの内容を表示すると、さまざまなユースケースを確認できます。
分析完了後は、[ファイル(File)] > [ファイルをロード(Load file)] > [DDRトレースファイルをロード(Load DDR trace file)] メニューを選択して、生成された JSON ファイルを IDA にロードする必要があります。詳細については「注意事項」セクションを参照してください。
インストール
まず、図 9 に示されている「マルウェア PC(Malware PC)」に Python 3 をインストールし、「分析用 PC(Analyst PC)」の IDA で Python 3 環境が使用されていることを確認します。DDR は Python 2 をサポートしていません。次に、こちら![]() から DDR リポジトリまたはインストーラの zip アーカイブをダウンロードします。以下の推奨環境も参照してください。
から DDR リポジトリまたはインストーラの zip アーカイブをダウンロードします。以下の推奨環境も参照してください。
以前のバージョンの IDA に含まれていたバグのため、バージョン 7.5 より古い IDA で最新リリースの DDR プラグインを実行するには、IDA マシンに Python 3.7 をインストールする必要があります。DDR のサーバ側は Python バージョン 3.8 または 3.7 のままでも問題ありません。
図 9 に示されている「マルウェア PC(Malware PC)」でアーカイブを展開します。最後にアーカイブのルートディレクトリから DDR_INSTALLER.py スクリプトを実行します(図 8)。DDR_INSTALLER.py スクリプトは既存の Python 環境を使用しません。DDR 専用の仮想 Python 環境が作成されます。非標準の Python モジュールの依存関係もありません。必要な依存関係はすべて、スクリプトの実行時に自動的にダウンロードされます。DynamoRIO Framework も DDR インストールディレクトリにインストールされます。スクリプトの指示に従うだけで DDR サーバと DDR IDA プラグインの両方のインストールプロセスを完了できます。スクリプトの出力にはインストールに関する重要なヒントが数多く含まれているので、必ず詳目を通してください。DDR GitHub の「ddr_installer\docs」ディレクトリに、インストールプロセスに関する詳しいビデオがあります。
注意事項
Microsoft Windows コマンドプロンプトの問題
Microsoft Windows コマンド プロンプト ウィンドウで特定のテキストをマークすると、Python アプリケーションがフリーズします。今回リリースされる DDR ベータ版では、ログファイルに加え、ロギングメッセージの大部分がコマンド プロンプト ウィンドウの標準出力に書き込まれます。したがって、コマンド プロンプト ウィンドウ内で DDR の出力をマークすると、DDR サーバが一時停止します。ESC キーを押すか、マークしたテキストをコピーすると、後続のコマンドが処理されるようになります。プラグインの使用中にタイムアウトエラーが発生する場合は、特定のテキストがマークされたままになっている可能性があります。テキストがマークされたままになっている場合は、DDR サーバウィンドウに移動して 2 ~ 3 回 ESC キーを押すか、サーバを再起動すると処理が再開されます。インストール完了後、通信をテストするには、IDA マシンのブラウザからインストール時に設定したポート経由でサーバのルートディレクトリにアクセスします(例:https://<DDR_SERVER_IP>:<DDR_SERVER_PORT>![]() )。
)。
マルチタスクと子プロセス
DDR は複数のスレッドや子プロセスを開始するプロセスをサポートしています。この機能は今回のベータ版の中でも比較的新しい機能であるため、従来と同様に DDR クライアント DLL から警告メッセージが出力されます。DDR のインストール ZIP アーカイブには、マルチスレッドやマルチプロセスをテストするためのサンプルも含まれています。
DDR が実行されるたびに「ddr_processtrace .txt」ファイルが作成されます(IDA マシンの sample ディレクトリを参照)。このファイルの内容は次のようになります。
testsample2_64.exe [2596]
write.exe [3600]
wordpad.exe [3864]
EvIlMaLwArE.exe [1368]
notepad.exe [2296]
最初の文字列は開始されたプロセス名で、カッコ内の数値は PID です。子プロセスがある場合は、「ddr_threads_EvIlMaLwArE.exe_1368.txt」のような個別のスレッドファイルが DDR によって生成されます。スレッドファイルには、そのプロセスで開始されたすべてのスレッドが記録されます。スレッドファイルの内容は次のようになります。
EvIlMaLwArE.exe [1368] [3852]
EvIlMaLwArE.exe [1368] [2552]
EvIlMaLwArE.exe [1368] [940]
EvIlMaLwArE.exe [1368] [3816]
上の例では、プロセス 1368 によって 1 つのメインスレッドと 3 つの追加スレッドが開始されたことが示されています。
ユーザが(図 12 に示されているメニューを使用して)命令をトレースすると、DDR により IDA JSON トレースファイルも別途作成されます。その内容は次のようになります。
trace_tmp_B4AB561A5A8A53E262C3D09738FFBFA3_EvIlMaLwArE.exe_1368.json
trace_tmp_B4AB561A5A8A53E262C3D09738FFBFA3_EvIlMaLwArE.exe_1368_apicalls.json
このファイルは、testsample2.exe のように、複数のインスタンスを開始するサンプルを分析する場合に便利です。JSON ファイルを IDA にロードするには、[DDRトレースファイルをロード(Load DDR trace file)] ボタンと [DDRトレースAPIファイルをロード(Load DDR trace API file)] ボタンを使用するか、[ファイル(File)] > [ファイルをロード(Load file)] > [DDRをロード(Load DDR)…] メニューを選択します。「…_apicalls.json」ファイルをロードする必要があるのは、API コールも解決する必要がある場合のみです。
ここでの唯一の注意点は、32 ビットのプロセスによって 64 ビットの子プロセスが開始されるシナリオが DynamoRIO でまだ実装されていないため、そのような 64 ビットの子プロセスが DDR で正しく処理されないという点です。こうした子プロセスは DDR で認識されないため、上述のファイルは作成されず、分析完了後もこのケースに該当するプロセスは強制終了されません。サンプルの実行時に開始されたプロセスが自動的にすべて強制終了される通常のケースとは異なるため、注意が必要です。分析完了時に DDR がサンプルの全プロセスをクリーンアップして強制終了しようと試みたとしても、常に正しく強制終了されるとは限らないのでご注意ください。実行中のマルウェアプロセスがマルウェアマシン上に残っていないかを手動で確認することを強くお勧めします。巧妙に隠しプロセスを開始する新たな方法がマルウェアに導入され、DDR が隠しプロセスを検出できないケースは常に起こり得るからです。
DDR クライアントのクラッシュに関する通知
適用するパッチに問題があると、状態が不安定になる場合があります。たとえばコードの後半で使用されるレジスタの初期化を無効化するとクライアントがクラッシュし、DDR クライアントがクラッシュしたという通知メッセージボックスが DDR サーバに表示されます。図 14 に例を示します。

図 14
その結果、バッファダンプなどの処理を開始した DDR プラグインの処理も失敗します。失敗した場合は、アプリケーションがクラッシュした原因を分析するか、もう一度処理を実行してみてください。場合によっては、別のランダム値がレジスタに書き込まれて、クラッシュしなくなることもあります。後者は確実な方法ではありませんが、うまく行くケースも少なくありません。引き続きクラッシュが発生し、パッチが原因でないことを確認できた場合は、DDR クライアント自体に原因があると考えられます。その場合はバグ報告をお願いいたします。
推奨環境
内部テストはすべて、以下の環境で行われています。
分析用 PC:
VMware Workstation VM
Windows 10 Enterprise 64 ビット
バージョン 1909
RAM:2 GB RAM
Python 3.8
IDA Pro 7.5
マルウェア PC:
VMware Workstation VM
Windows 7 Professional 64 ビット SP1
バージョン:7601
RAM:2 GB
Python 3.8
デフォルト インストール ディレクトリ:C:\tools\ddr
1.0 リリースの新機能
- IDA から DDR サーバ側にサンプルファイルを自動的にコピー
- Python 3 に対応
- IDA 7.4 以降に対応
- 仮想環境に対応したインストーラ
- 実行時のバッファをダンプ
- サンプルにパッチを適用:
- 実行時に命令を無効化
- 実行時に EFLAGS を切り替え
- 関数をスキップしてカスタムの戻り値を返す
- バッファのダンプやトレースの実行など、その他の機能にもすべてのパッチを適用
- 外部デバッガでサンプルを実行するためのデバッガスクリプトを自動作成(選択したパッチを含む)
- 外部デバッガをアタッチするための無限ループが追加されたサンプルを作成
- 複数のビルディングブロックを選択してフルトレースを実行
- すべての設定を JSON ファイルに移行
- ユーザ提供データの入力チェックを強化
- DDR サーバを新しい JSON API に移行
- 命令と API トレースファイルをインポート
- 複数のプロセスとスレッドに対応
- Flask から FastAPI に移行
- コードのクリーンアップとコード構造を改善
(ただし、まだ改良の余地がある暫定なコードであるため、コーディングの見本としては使用しないでください)
本稿は 2020 年 5 月 28 日に Talos Group
のブログに投稿された「Dynamic Data Resolver (DDR) — IDA Plugin 1.0 beta
Authors