
この記事は、Doug Sibley と Yuxi Pan![]() の協力を得て、Sean Baird
の協力を得て、Sean Baird![]() が執筆しました。
が執筆しました。
概要
ここ数か月間のニュース、ツイッターやソーシャル メディアの投稿などでは「偽ニュース」の問題が目立っています。偽ニュースの根底には情報戦争や詐欺といった根深い歴史があり、世界中の人々に影響を及ぼす別の「サイバー脅威」です。Talos の研究者は最先端の機械学習と AI 技術を駆使してこの問題に取り組み、各国から 80 以上のチームが競う「Fake News Challenge![]() 」で 1 位の獲得を目指しています。
」で 1 位の獲得を目指しています。

コンテキスト
背景
ここ数か月で偽ニュースについて大々的に報じられていますが、現代の偽ニュースの背景には情報操作と詐欺の根深い歴史があります。
この問題について Facebook が出した詳細な論文![]() では、情報操作を「国内外の政治的感情を歪めるための組織的な行動であり、多くは戦略的ないし地政学的な目的がある」と定義しており、偽ニュースを「情報操作ツールキットの有用なツール」として分類しています。同じ論文は偽ニュースについて、「事実であると主張しているが意図的な虚偽情報を含んでおり、感情に訴える、視聴者数を増やす、彼らを騙すなどの目的がある記事である」と指摘しています。
では、情報操作を「国内外の政治的感情を歪めるための組織的な行動であり、多くは戦略的ないし地政学的な目的がある」と定義しており、偽ニュースを「情報操作ツールキットの有用なツール」として分類しています。同じ論文は偽ニュースについて、「事実であると主張しているが意図的な虚偽情報を含んでおり、感情に訴える、視聴者数を増やす、彼らを騙すなどの目的がある記事である」と指摘しています。
偽ニュースに関する Wired の記事によると![]() 、偽ニュースとは平たく言えば「ソーシャル メディアの閲覧数を増やしたり、広告収入を上げたり、政治的なメッセージを伝えたりするためのでっち上げニュース」です。
、偽ニュースとは平たく言えば「ソーシャル メディアの閲覧数を増やしたり、広告収入を上げたり、政治的なメッセージを伝えたりするためのでっち上げニュース」です。
これはサイバースペースで解決するのが難しい問題ですが、テクノロジーとソーシャル メディアによってニュースが瞬時に広まる現在では特に深刻化しています。こうしたことから、学界や業界の研究者が集まり「Fake News Challenge(FNC)![]() 」が誕生しました。FNC の目標は、「ニュース記事の誤った情報や意図的な偽情報を見抜くファクト チェッカーの開発を競うことで、偽ニュースの問題に対処すること」です。
」が誕生しました。FNC の目標は、「ニュース記事の誤った情報や意図的な偽情報を見抜くファクト チェッカーの開発を競うことで、偽ニュースの問題に対処すること」です。
2016 年 12 月 1 日から 2016 年 6月 2 日まで続いた Challenge 第一ラウンド(FNC-1)では、偽ニュース検出の重要な突破口となり得るスタンス検出のみに焦点を当てました。
FNC-1:スタンス検出
実際の真偽判定は政治的・技術的問題を抱えたかなり困難な課題ですが、スタンス検出はそれに向けた突破口となる可能性があります。Challenge 主催者の 1 人である Dean Pomerleau![]() 氏は Mediashift
氏は Mediashift![]() によるインタビューで、「(スタンス検出の)目標は、検索エンジンのように記事の引用数や閲覧数だけを見るのではなく、記事の内容も分析することだ」と述べています。
によるインタビューで、「(スタンス検出の)目標は、検索エンジンのように記事の引用数や閲覧数だけを見るのではなく、記事の内容も分析することだ」と述べています。
FNC における「スタンス検出」とは、言うなれば記事の見出し/主張と本文の関係を識別することです。具体的には、本文が見出し/主張と合致しているのか、合致していないのか、見出し/主張について議論しているのか、あるいは無関係なのかを分析します。つまり、スタンス検出による分析結果は「合致している」、「合致していない」、「議論している」および「無関係」のいずれかになります。下の図は、対象を広げた偽ニュース検出システムでスタンス検出を実装する一例です。
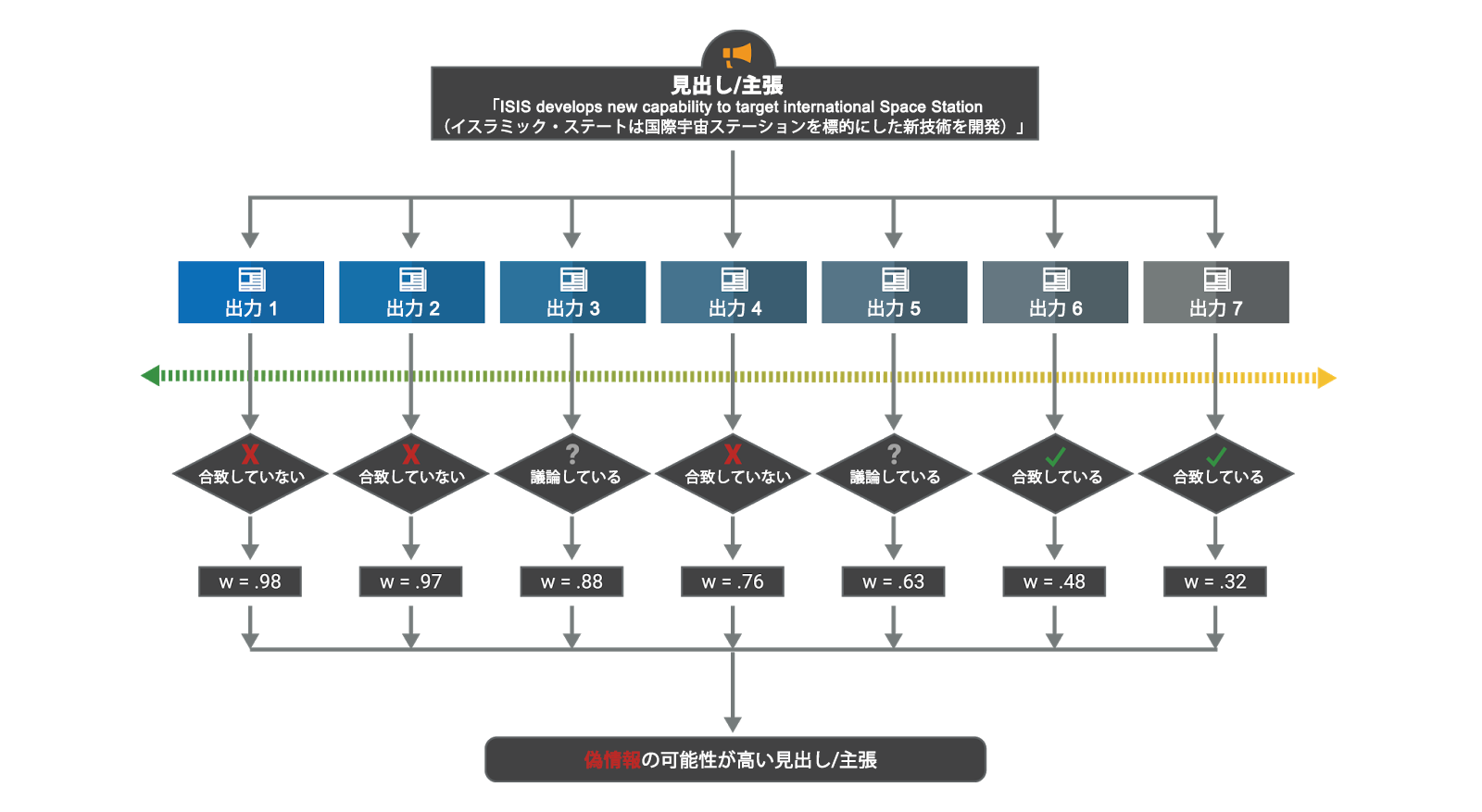
偽ニュース検出でスタンス検出が果たす役割
Talos の研究者たちは挑戦好きで FNC にも乗り気でしたが、チーム名は所属先を隠すためスペルを並び替えた「SOLAT IN THE SWEN」としました。参加を決めた直後から、彼らは空き時間を利用してさまざまなモデルやソリューションの開発に取り組んできました。

SOLAT IN THE SWEN:Talos の隠密チーム名
Talos のソリューション
Challenge における目標の 1 つは「AI 技術、特に機械学習と自然言語処理をいかに活用して偽ニュースと戦えるかを探る」ことです。このため SOLAT IN THE SWEN チームでは、さまざまな最先端の機械学習技術をテストすることに決めました。いくつかの異なるモデルを実装した結果、アンサンブルに複数モデルを組み合わせることで最良の結果が得られることが判明しています。チームが最終的に提出したアンサンブルは、勾配ブースティング意思決定ツリー(GBDT)と深層畳み込みニューラル ネットワーク(CNN)を 50/50 の加重平均で組み合わせたものです。コード全体は Talos GitHub![]() に置かれており、Apache 2.0 ライセンスでオープン ソースとして公開されています。
に置かれており、Apache 2.0 ライセンスでオープン ソースとして公開されています。
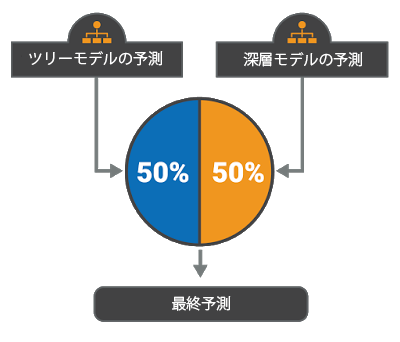
各モデルを 50/50 の加重平均で組み合わせた、Talos チームのアンサンブル
深層学習アプローチ
チームが最初に使用したモデルは、深層学習で使用される数種類のニューラル ネットワークを応用したものです。このモデルでは、Google ニュースの事前学習ベクトル![]() を使用して、1 次元の畳み込み
を使用して、1 次元の畳み込み![]() ニューラル ネットワーク(CNN
ニューラル ネットワーク(CNN![]() )を見出しと本文に単語レベルで適用します。CNN の特徴は、処理中の効率的・効果的な並列計算速度です。CNN からの出力は多層パーセプトロン(MLP
)を見出しと本文に単語レベルで適用します。CNN の特徴は、処理中の効率的・効果的な並列計算速度です。CNN からの出力は多層パーセプトロン(MLP![]() )に入力されます。エンドツーエンドでトレーニングした MLP の出力は「合致している」、「合致していない」、「議論している」および「無関係」の 4 クラスに分類されます。使用したモデルは、すべての畳み込み層でドロップアウト(p = .5)により正則化されています。モデルのハイパーパラメータはすべて実用的なデフォルト レベルに設定されていますが、最適化するための追加評価は行われていません。
)に入力されます。エンドツーエンドでトレーニングした MLP の出力は「合致している」、「合致していない」、「議論している」および「無関係」の 4 クラスに分類されます。使用したモデルは、すべての畳み込み層でドロップアウト(p = .5)により正則化されています。モデルのハイパーパラメータはすべて実用的なデフォルト レベルに設定されていますが、最適化するための追加評価は行われていません。
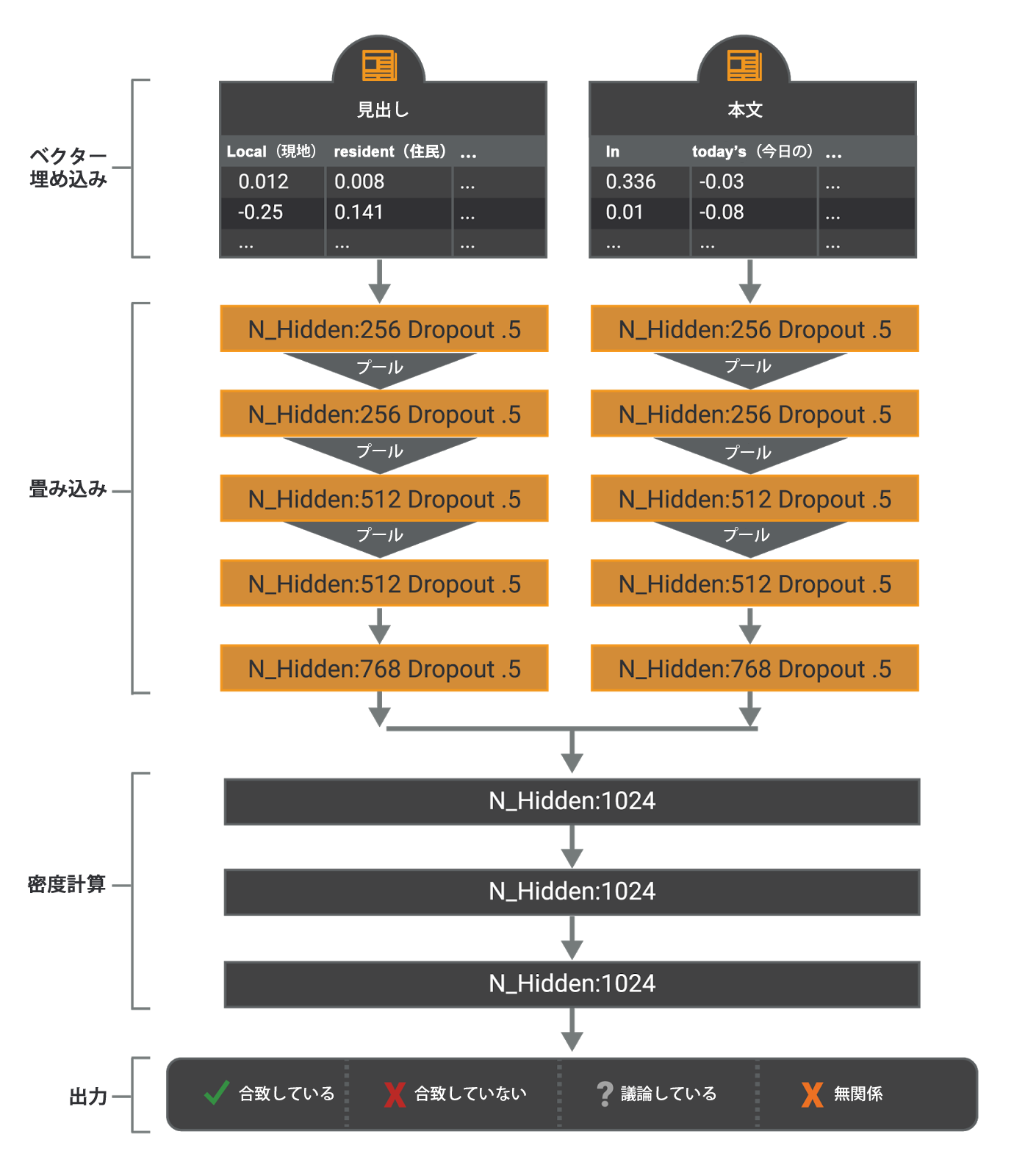
深層学習モデルの概要図
このモデルのアーキテクチャが選ばれた理由は、実装の容易さと計算速度の速さ、そして再帰ではなく畳み込みを利用できることにあります。今回のモデルの相対的な強さから判断すると、畳み込みは多種多様なトピックを取り込めるように思われます。ただしモデルではテキストを 1 回しか観察できないため、限界もあります。モデルを拡張するには、畳み込み後の再帰を伴う、ある種のアテンション メカニズムを含める方法が考えられます。この方法では、全般的な要約を CNN が出力した後に見出しや本文の一定側面をモデルから照合できる可能性があります。
勾配ブースティング意思決定ツリー(GBDT)アプローチ
アンサンブルで使用される他のモデルは、勾配ブースティング意思決定ツリー(GBDT![]() )モデルです。このモデルでは、記事の見出しや本文から取得したテキスト ベースの特徴をいくつか入力し、続いてそれらを勾配ブースティング意思決定ツリーに入力することで、見出しと本文の関係を予測します。
)モデルです。このモデルでは、記事の見出しや本文から取得したテキスト ベースの特徴をいくつか入力し、続いてそれらを勾配ブースティング意思決定ツリーに入力することで、見出しと本文の関係を予測します。
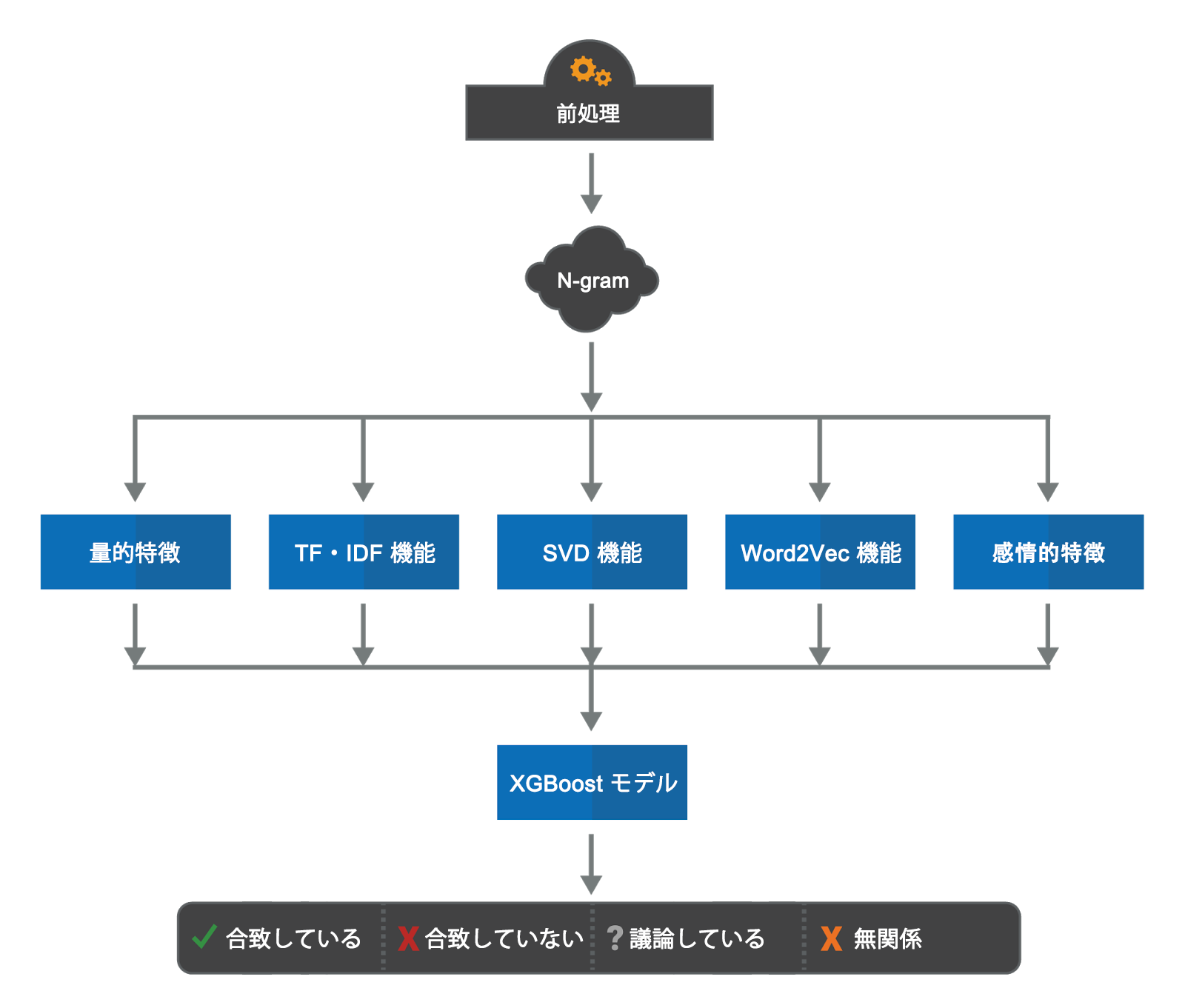
意思決定ツリー モデルの概要図
データセットを調査した後、見出しと本文の関係を明らかにする可能性のある特徴がいくつか明らかになりました。例えば、
- 見出しと本文の間で重複する単語の数
- 単語数、2-gram および 3-gram の間で測定された類似点
- これらの数を用語の出現頻度-逆文書頻度(TF-IDF
 )重み付けと特異値分解(SVD)で変換した後の類似度
)重み付けと特異値分解(SVD)で変換した後の類似度
スタンス検出時にこれらの特徴を利用すれば、複雑なマッピングを学習するために強力なモデルを使用する必要はありません。
こうした理由から、特徴量ベクトルの各スケールにおける確実性の高さが際立つ GBDT が選択されました。GBDT では正規化が不要で、オーバーフィットを避けるためにいくつかの方法で正則化できます。さらに、XGBoost![]() はオープンソースで実装効率が非常に高いため、自作した特徴にも簡単に適用できます。
はオープンソースで実装効率が非常に高いため、自作した特徴にも簡単に適用できます。
実例
一部の読者は、実際のデータに基づくシステムの出力に興味があるかもしれません。そこで試しに今回のブログ記事の草稿を、さまざまな見出し(つまり実際の見出しと、今回のために考えた偽の見出し)を付けてシステムで評価してみました。今回使用した見出しは次のとおりです。
- Talos Targets Disinformation with Fake News Challenge Victory(Talos チームは「Fake News Challenge」で 1 位を狙う(実際の見出し))
- Team Loses Fake News Challenge(チームは Fake News Challenge で 1 位獲得に失敗)
- Research Shows Fake News is Unsolvable(偽ニュースは解決不可能との調査結果)
- Giraffe Livestream Continues to Fourth Week with No Action(Giraffe Livestream は何もせず 4 週目に突入)
スタンス検出におけるモデルの精度を試したわけですが、結果は下図のようになりました。

今回のブログ記事と、さまざまな見出しの組み合わせを自作モデルで評価した結果
上記のように、深層学習アプローチも GBDT アプローチも単独では精度が劣りますが、これら 2 つのアプローチを 50/50 の重み付けにより組み合わせることでスタンスが正確に検出できています。
まとめ
結論から言えば、こうした革新的なモデルを開発できる Talos チームは世界トップ クラス![]() としての自負があります。今後も研究を重ねる必要はありますが、受賞歴のある Talos のスタンス検出研究は 21 世紀の偽ニュースや偽情報の問題に対する重要な突破口となるでしょう。
としての自負があります。今後も研究を重ねる必要はありますが、受賞歴のある Talos のスタンス検出研究は 21 世紀の偽ニュースや偽情報の問題に対する重要な突破口となるでしょう。
Fake News Challenge が進展し、自然言語処理コミュニティが最先端の研究を進める中で、Talos も最先端技術により偽の情報を排除するための努力を続けます。
本稿は 2017年6月20日に Talos Group