
“Più veloce della Luce”
Superman. Vol. 21 di Geoff Johns,Kurt Busiek, Pete Woods
_____________________
L’emergenza sanitaria che stiamo vivendo e lo stato di lockdown fanno riflettere.
Osservando la situazione attuale, si può alimentare un certo scetticismo sulla nostra capacità, come società globale, di governare gli eventi e i contesti in cui viviamo, malgrado la disponibilità di tecnologia e di dati senza precedenti nella nostra storia.
I dubbi si estendono quindi dall’adozione delle tecnologie alla condivisione dell’informazione, che è alla base della conoscenza e della capacità di prevenire, programmare, eseguire.
L’informazione è codificata in segnali luminosi, che imprigionati in guide d’onda viaggiano alla velocità della luce. Malgrado questo legame, non ci verrebbe mai di esclamare, un pò come Superman, “Via! Più veloce dell’informazione!”.
Nel contesto attuale la percezione è infatti quella di una informazione lenta a generare valore, soprattutto quando ci si confronta con situazioni anomale, dove pare invece che l’effetto sia estremamente rapido: pensate, per esempio,alla propagazione di un Virus (Biologico o Informatico).
Da un’analisi accurata, ci rendiamo conto che esiste un elemento che può rallentare l’informazione: la capacità di decodifica del sistema ricevente, cioè di “acquisire” i dati, “interpretare” il linguaggio (la struttura) ed “elaborare” il contenuto, la nozione, il significato che l’informazione rappresenta. In altre parole la capacità di ascolto.
L’efficacia dell’informazione segue in tutto e per tutto i principi della comunicazione e solo quando essi sono rispettati si può aspirare a realizzare la catena del valore informazione-conoscenza-saggezza.
[NdA: nel prosieguo dell’articolo si parlerà sempre e volutamente di informazione nella rappresentazione della realtà e mai si considererà il caso della disinformazione o delle alterazioni malevole della stessa].
La riflessione si sposta quindi sull’illusione che il digitale e Internet ci aiutino a governare lo spazio e il tempo “by definition”.
Dobbiamo forse riqualificare il legame tra le tecnologie del digitale e altre tematiche quali il linguaggio, la logica della comunicazione, i metodi di apprendimento e gli ambiti di adozione, affinchè si possa avere la giusta confidenza nel gestire e governare la velocità degli eventi?
È un esercizio di “connecting the dots” non solo tecnologici, ma anche scientifici, filosofici, regolatori e umanistici per ottenere un miglior controllo della potenza dell’Informazione?
Di seguito saranno riportati alcuni trend tecnologici che stanno fornendo strumenti utili alla decodifica e alla comprensione in tempo reale dell’informazione. Strumenti che potrebbero restituire al processo di condivisione la piena performance comunicativa con la conseguente sensazione ed emozione di fare un viaggio alla velocità della luce.
Artificial Intelligence and Intelligent Automation
Si definisce Intelligence: “Una capacità mentale molto generale che, tra le altre cose, implica la capacità di ragionare, pianificare, risolvere problemi, pensare in modo astratto, comprendere idee complesse, apprendere rapidamente e imparare dall’esperienza”.
[“Mainstream Science on Intelligence” (1994), Wall Street Journal].
Una delle ambizioni degli scienziati del XXI secolo sembra essere quella di estendere questa capacità dall’uomo alla macchina, cioè di emulare alcune funzioni dell’intelligenza umana per ottenere prestazioni “qualitativamente equivalenti e quantitativamente superiori a quelle umane”.
Si è rispolverato il tema dell’Artificial Intelligence (AI).
Uno degli obiettivi che ci si è posti è proprio quello inerente la comprensione e rielaborazione delle informazioni per replicare alcuni processi umani: apprendimento, analisi, comprensione…
I risultati raggiunti ci portano anche a parlare di Intelligent Automation o Hyperautomation cioè della visione secondo cui la combinazione di metodologie e di tecnologie (dalla Robotic Process Automation al Natural Language Processing passando per AI e ML) possa aiutare le organizzazioni a identificare e automatizzare rapidamente il maggior numero possibile di processi aziendali amplificando la capacità umana di governare i contesti, di gestire, di pianificare, di prendere decisioni e di eseguirle.
“Hyper-automation deals with the application of advanced technologies including artificial intelligence (AI) and machine learning (ML), to increasingly automate processes and augment humans…
This automation is achieved by mimicking the capabilities that knowledge workers use in performing their work activities: language, vision, execution, and thinking & learning.”
[intelligent-automation – book Pascal Bornet]
Un caso d’uso importante su questa direzione tecnologica è Open-Source Intelligence (OSINT).
OSINT è una metodologia “investigativa” che combinando tecnologie e algoritmi di vario tipo in modo qualitativo e quantitativo acquisisce, analizza e produce informazioni da fonti pubbliche (open source – target funzionali):
- Media: newspapers, magazine, radio, broadcaster …
- Internet: pubblicazioni online, blogs, forum, YouTube, e altri social media (i.e. – Facebook, Twitter, Instagram, etc.)…
- Dati Pubblici governativi: report, dati di budget, press conference, websites, webinars…
- Pubblicazioni Accademiche o Professionali: portal universitari, white paper, conferenze e simposi, tesi…
- Dati Commerciali: brevetti e benchmark, annual report, financial and industrial assessments, analisi di mercato…
Piattaforme informatiche sono state sviluppate per sostenere questa metodologia e sono in uso in numerosi ambiti dalla sicurezza nazionale al marketing strategico.
OSINT is defined by both the U.S. Director of National Intelligence and the U.S. Department of Defense (DoD), as intelligence “produced from publicly available information that is collected, exploited, and disseminated in a timely manner to an appropriate audience for the purpose of addressing a specific intelligence requirement”. [As defined in Sec. 931 of Public Law 109-163, entitled, “National Defense Authorization Act for Fiscal Year 2006.]
Gli obiettivi di utilizzo di questi sistemi sono dunque numerosi: Brand Reputation, Management reputation, Suppliers reputation, Travel Related Risks, Digital underground monitoring, Assets protection, attack prevention support…
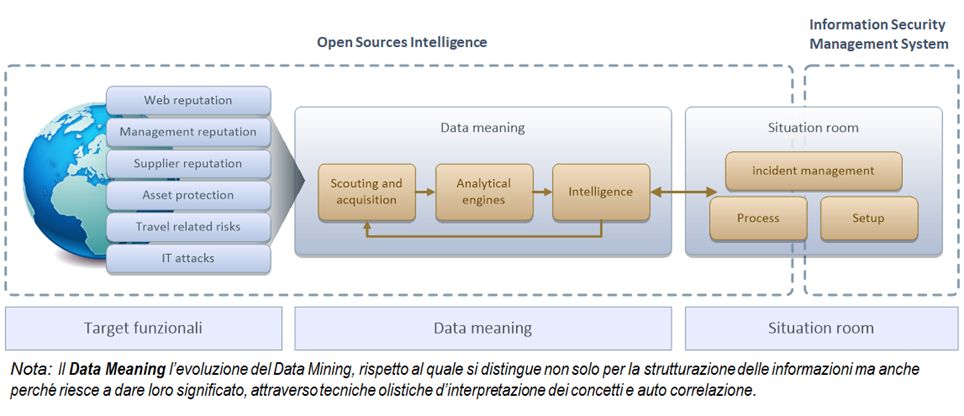
Ovviamente alla lista si può aggiungere il supporto alle attività di triage e, per esempio, il tracciamento della diffusione di una pandemia.
Trustworthy AI e Federated Learning
L’intelligenza artificiale deve essere allenata, addrestrata, testata per essere certi che mantenga un livello di performance accettabile per gli ambiti e i compiti in cui dovrebbe sostituire l’azione dell’intelligenza umana.
Il requisito fondamentale è dunque l’affidabilità (Trustworthy AI).
Gli algoritmi sono sottoposti a cicli di verifica e “fine tuning” durante i quali elaborano un insieme di dati (training set), studiati ad hoc per questa fase di addestramento.
Elemento ricorrente in tutte le linee guida è la seguente regola/assunzione: “un’ipotesi consistente con gli esempi è probabilmente e approssimativamente corretta (PAC) se l’insieme di training è sufficientemente grande”.
Ad essa si aggiungono altre assunzioni e good practice che indirizzano il metodo di selezione e definizione dei training set per essere confidenti della qualità del risultato finale. Il rischio che si potrebbe correre a valle di un’errata progettazione e addestramento degli algoritmi è la presenza di codice dannoso, backdoor e meccanismi che possano divulgare informazioni private degli utenti.
Vi invito a leggere l’articolo al seguente link che descrive alcune vulnerabilità dei sistemi di machine learning siano essi centralizzati che federati: https://arxiv.org/pdf/1702.07464.pdf.
Federated Learning è una procedura di machine learning in cui l’obiettivo è addestrare un modello di alta qualità con dati distribuiti su diversi provider indipendenti. Invece di raccogliere i dati su un singolo server centrale, i dati rimangono confinati nei silos originari mentre gli algoritmi e i modelli predittivi sono distribuiti.
Questa procedura indirizza dunque un tema critico: avere accesso a un volume minimo di dati essenziali ad un corretto addestramento dei modelli nel rispetto della privacy e confidenzialità degli stessi.
Il principio generale consiste nel produrre un “modello globale” che venga addestrato utilizzando i dati disponibili localmente e condividendo e poi scambiando i parametri caratteristici degli algoritmi (ad esempio i pesi di una rete neurale profonda) per generare un modello globale.
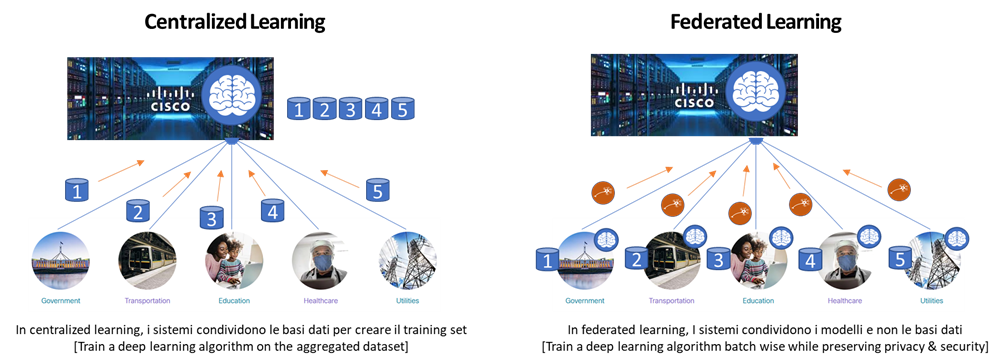
In ambito ospedaliero segnaliamo l’esperienza della Owkin, un’azienda statunitense che dal 2016 sta supportando una rete globale di ricercatori, data scientists, medici, nello sviluppo di modelli di knowledge management mediante un approccio federato che preservi la sicurezza e la privacy dei dati.
Il modello prevede che le organizzazioni possano usufruire della capacità informativa dei silos di dati interni per lavorare in modo più efficiente, senza violare le misure di sicurezza. Gli ospedali e le aziende farmaceutiche mettono a fattor comune la parametrizzazione dei modelli di machine learning per operare localmente con la medesima algoritmica sui dati privati come nome, sesso, razza, esami del sangue, immagini a raggi X e scansioni TC, per prevedere l’incidenza della malattia, tracciare l’evoluzione di malattie o prendere decisioni mediche, senza violare riservatezza del paziente o leggi, politiche e accordi con gli utenti correlati.
In generale un sistema di AI/ML deve essere RI-validato ogni volta venga adottato fuori dal contesto e dall’ambito per cui è nato ed è stato formato. Malgrado ci possa essere una capacità intrinseca di adattamento, l’impiego fuori dal perimetro di utilizzo originario non produce chiare indicazioni sulla perdita di affidabilità. Dunque l’effetto su un processo decisionale potrebbe essere negativo seppure apparentemente il sistema sembrerebbe operare correttamente.
Artificial Intuition and Complexity Management
“Dove non arriva il pensiero deterministico, scientifico deve arrivare l’intuizione. Spesso l’intuizione è sufficiente per intraprendere un percorso esperienziale che restituisca una visione coerente della realtà e una guida pragmatica alla gestione degli imprevisti.” J. Marczyk
Sembra ci sia una incompatibilità tra accuratezza dei sistemi di AI/ML e la complessità che dovrebbero governare: in presenza di elevata complessità spesso la precisione algoritmica risulta non rilevante ai fini decisionali. Estremizzando il punto: la previsioni che nel 2050 il livello del Mediterraneo salirà di 20 cm è meno rilevante di quella meteo per la giornata di domani.
Nella complessità i modelli che prevedono un meccanismo di apprendimento automatico possono mostrare dei limiti strutturali: richiedono un training set ricco di dati per un addestramento efficace. Un sistema complesso spesso non offre basi dati sufficientemente popolate di esempi di “anomalie” da poter innescare il processo di “learning”.
Pensate ad un sistema che automatizzi il test di qualità ed efficienza di chip in ambienti operativi critici per umidità, temperature, pressione atmosferica ecc. In questo caso creare un training set significherebbe riprodurre in laboratorio le condizioni ambientali con l’incertezza di replicare le situazioni operative reali e di conseguenza pattern di dati significativi. Non ci sarebbero abbastanza anomalie da cui imparare.
Quindi nell’ambito dell’Intelligenza Artificiale si può avere anche un approccio denominato Artificial Intuition. Esso è uno metodo che restituisce una indicazione non accurata, ma sicuramente rilevante, significativa e rapida.
In questo caso l’intenzione è quella di replicare la capacità umana di “Intuire”, dal latino “Intueri”, “vedere dentro”, cioè di rendersi conto di un fatto (per sé non manifesto) senza l’aiuto della riflessione o di un processo logico induttivo o deduttivo.
Chiunque può sentire che qualcosa non va ascoltando un motore acceso che produce un suono strano senza essere un meccanico addestrato. L’intuizione è una forma di conoscenza che appare nella coscienza senza un’ovvia deliberazione. L’intuizione artificiale è un nuovo paradigma.
https://ontonixqcm.blog/2020/11/15/qcm-is-artificial-intuition/
La Quantitative Complexity Theory (QCT) è stata concepita intorno a una metrica di complessità scoperta all’inizio degli anni 2000 da J. Marczyk e dal suo team. Sulla base della teoria, è stata costruita una tecnologia: Quantitative Complexity Management (QCM). La caratteristica fondamentale della tecnologia QCM è che è in grado di riconoscere l’esistenza di anomalie la prima e unica volta che ci si confronta con esse. È anche in grado di individuare le loro fonti grazie a una tecnica nota come Complexity Profiling.
QCM è l’esempio più concreto, presente sul mercato di intuizione artificiale.
QCM può essere impiegato per produrre una misura della gravità dello stato di salute di un paziente partendo da dati grezzi (ad esempio quelli presi dagli strumenti di una sala di rianimazione) e superando le valutazioni soggettive che si rifanno a classificazioni basate su scale funzionali (es. Paziente con GRAVE disfunzione cardiaca se “Sintomi si manifestano a riposo; qualsiasi attività fisica aumenta il disagio.” scala NYHA). Un profilo di complessità di un paziente potrebbe essere un’informazione preziosa che riflette la sua situazione clinica e suggerisce (o lascia intuire) dove concentrare le terapie.
La conclusione è che il Complexity Profiling è una tecnica utile quando si tratta di determinare i fattori dominanti, o gli attori chiave, in uno scenario multidimensionale complesso in cui ogni circostanza è unica e diversa dalle altre. Questo è probabilmente vero più in medicina che in qualsiasi altra disciplina.
Security & Privacy: i motori dell’innovazione nella trasformazione digitale
La digitalizzazione è un fenomeno globale e l’emergenza sanitaria che stiamo vivendo ha ribadito prepotentemente e in molti casi anche accelerato, il ruolo fondamentale delle tecnologie digitali nella nostra vita quotidiana.
Le tecnologie e i casi d’uso descritti, rappresentano la potenzialità del digitale e allo stesso tempo l’esigenza di coniugare un forte legame tra Security e Privacy.
Nasce cosi una nuova disciplina all’interno del dominio del software o del sistema informativo, denominata “Privacy engineering”. Essa mira a fornire metodologie, strumenti e tecniche tali da permettere una progettazione di sistemi intrinsecamente sicuri.
Privacy engineering combina aspetti di vario tipo (process management, securezza, ontologie e software engineering) al fine di indirizzare esigenze di conformità giuridiche sulla privacy in contesti progettuali sicuri dal punto di vista cibernetico.
Riflessioni aggiuntive
Dobbiamo essere consapevoli che l’adozione delle tecnologia comporta sempre “rischiose opportunità”. Le tematiche sin qui discusse possono ricondurre a una serie di rischi potenziali, quali meccanismi decisionali opachi, discriminazioni basate sul bias, violazioni della privacy o utilizzi per scopi criminali.
Nascono diversi filoni di approfondimenti: sicurezza e privacy, norme, tutele e utilizzo etico.
La Commissione Europea ha pubblicato un primo documento che identifica gli ambiti in cui si deve lavorare per sviluppare un quadro normativo che tuteli le comunità e i singoli individui, dall’impiego destrutturato dell’intelligenza artificiale. Gli argomenti trattati sono adeguati a tutte le tecnologie che aspirano ad estendere e potenziare le capacità umane.
La prima sfida potrebbe essere mettere a fattor comune le tecnologie, le metodologie, le competenze e le esperienze nel rispetto di requisiti stringenti su sicurezza informatica e privacy, per cimentarci nella progettazione di un sistema di monitoraggio e controllo della trasmissione e comprensione dell’informazione, che permetta di rallentare lo sviluppo di eventi catastrofici e accelerare la condivisione della conoscenza con cui limitare gli effetti dannosi.
Conclusioni
L’informazione deve essere veloce quanto lo è il suo vettore primario (la Luce). Abbiamo visto come le tecnologie possono essere utili a ridurre quegli elementi che si comportano da freno alla comprensione e alla conoscenza.
Nell’aspirazione iniziale di poter essere “più veloci dell’Informazione” c’è tutta la filosofia moderna del pieno controllo dei contesti per giocare di anticipo rispetto a “Tutto” con l’obiettivo di“prevenire – e aggiungerei – e non curare”.
Tecnologie e metodologie di impiego potrebbero fare evolvere il Sistema Mondo rendendolo capace di gestire l’informazione in modo analitico, intuitivo, predittivo, sicuro ed etico. Un’informazione più veloce potrebbe essere “un vaccino” e, in generale, una sorta di “Anti-Virus” del mondo analogico.
___________________________________________
Potresti essere interessato anche a:
Security & Trust: i motori dell’innovazione nella trasformazione digitale
(Fabrizio Gergely, responsabile tecnico Cisco Italia)
Report Cisco sull’impatto degli aspetti di Privacy:
Forged by the Pandemic: The Age of Privacy
Protecting Data Privacy During the Pandemic and Beyond
From Privacy to Profit: Achieving Positive Returns on Privacy Investments
Authors