
Simplifier les opérations réseau passe par la mise en place d’un système de management centralisé efficace qui pilote l’ensemble des équipements réseau. Si tout cela est loin d’être nouveau, l’avènement du SDN a donné encore plus de poids à ces systèmes qui assurent toujours plus de fonctions.
L’architecture Cisco DNA n’échappe pas à cette évolution. Certes, les services sont fournis de manière distribuée par les équipements réseau eux-mêmes et restent donc opérationnels même en cas de perte de Cisco DNA Center, mais qui est prêt à se passer des services d’automatisation, de visibilité sur l’expérience utilisateur, de sécurité et de segmentation ? Cisco DNA Center permet de faire coller le réseau aux besoins du business… Et forcément cela impose donc une disponibilité 24/7/365 : Cisco DNA Center est aussi critique que le réseau lui-même. De même manière, la criticité de Cisco vManage pour notre solution SD-WAN est aussi importante que le réseau lui-même. C’est pour cette raison que des mécanismes de haute disponibilité ont été conçus pour vManage et Cisco DNA Center. Ces mécanismes sont globalement très similaires aussi je me propose de les expliquer ici dans les grandes lignes. Je prendrais DNAC comme exemple mais vous extrapolerez pour le SD-WAN.
Deux mécanismes permettent globalement de déployer un DNAC résilient : HA (High-Availability) et DR (Disaster Recovery). Je constate parfois un manque de compréhension sur ces sujets aussi je vais essayer de clarifier tout cela dans les grandes lignes. Vous allez voir que c’est très simple ! Évidemment, vous prendrez soin de regarder les documentations complètes avant d’implémenter (voir références en fin d’article)
HA – High Availability
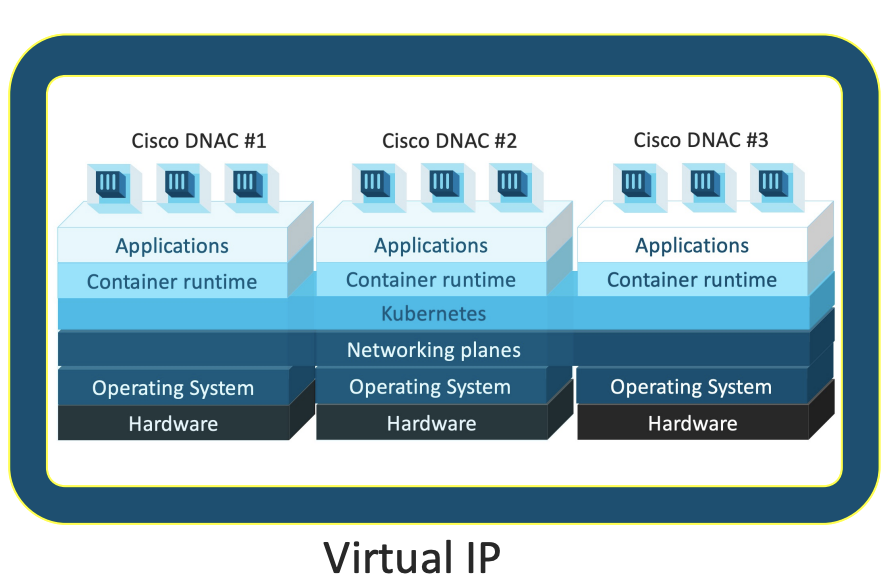
L’objectif d’un déploiement HA est de créer un cluster d’appliances DNAC qui va rester opérationnel même en cas de perte d’une appliance (panne du nœud ou panne du réseau qui isole un nœud). Le cluster est vu comme un seul et même système redondé, joignable à travers une seule et même IP (VIP – Virtual IP).
Un cluster DNAC en HA se compose de 3 appliances (3 membres). Ces dernières doivent être sur le même réseau car on va réellement avoir des communications constantes entre les services qui sont répartis sur chacune. Une des appliances va porter la VIP du cluster et redirigera les flux vers le membre qui porte tel ou tel service. En cas de perte de cette appliance “principale”, la VIP est reprise par un autre nœud du cluster. Il est donc indispensable que toutes les membres du cluster soient sur le même réseau (même subnet).
Pour comprendre comment marche la HA, il faut se rappeler que l’architecture DNAC repose sur de très nombreux containers Docker qui assurent les diverses fonctions installées. Ces containers sont répartis sur les différentes appliances et sont continuellement monitorés par le système sous-jacent de gestion appelé MagLev (comme Magnetic Levitation). Si un container manque de ressources, pas de problèmes on en démarre un second pour adresser les besoins de performance. MagLev va aussi supprimer les containers devenus inutiles faute d’utilisation. La gestion du réseau pour l’interconnexion de tous ces containers est assurée par Kubernetes. Dans un cluster, on a donc des containers sur toutes les appliances et une communication constante entre ces derniers, nécessitant une latence très faible (moins de 10ms) et une bande-passante suffisante (10Gbit/s).
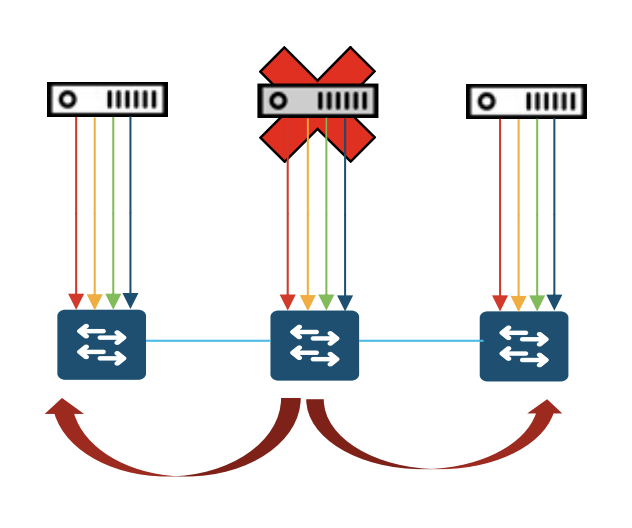
Mais c’est surtout le mode de gestion de la redondance qui va vous aider à comprendre les designs réseau appropriés pour un cluster DNAC. On va chercher à éviter un scénario catastrophique qu’on appelle le split-brain. C’est une situation dans laquelle plusieurs nœuds du cluster pensent qu’ils sont actifs au même moment, et reprennent donc chacun l’ensemble des services. C’est une situation à éviter à tout prix car elle va générer des instabilités, un peu comme si vous aviez plusieurs ingénieurs réseau configurant en même temps la même infrastructure sans aucun moyen de communication et de synchronisation : c’est l’échec assuré ! La gestion du split-brain sur Cisco DNA Center reprend les mêmes principes qui ont fonctionné sur le contrôleur APIC (dans la solution datacenter Cisco ACI) : en cas de panne dans le cluster c’est le groupe d’appliances qui est majoritaire qui prend le service, l’autre se met en veille. Sur un cluster de 3, il faut donc que 2 appliances se voient pour prendre le service. L’appliance qui se retrouve seule considère qu’elle n’est pas majoritaire et reste en attente. En parle de quorum, un quorum de 2 appliances doit être atteint pour être fonctionnel.
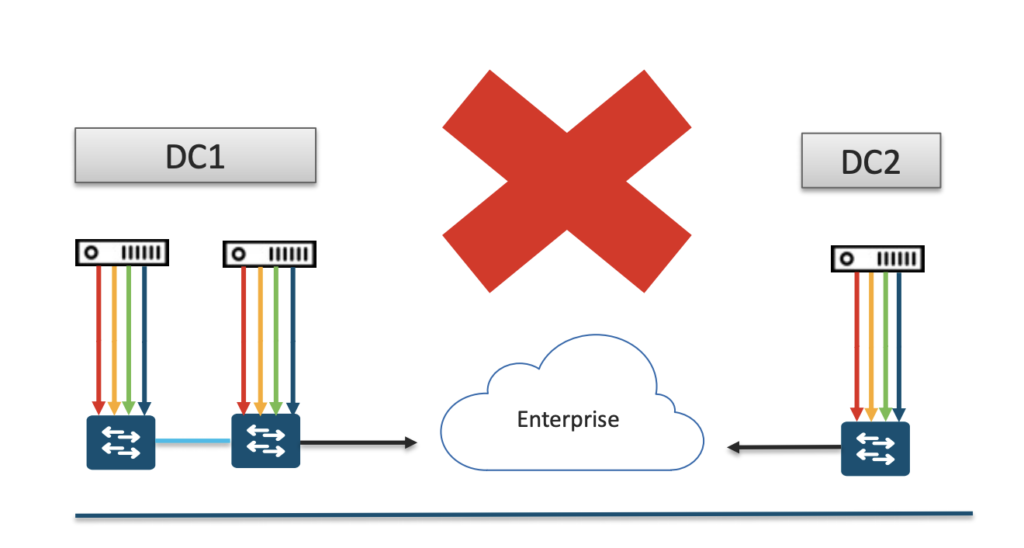
La question qui revient encore et encore est la suivante : “J’ai deux datacenters interconnectés par de la fibre noire, offrant une excellente performance et une très faible latence, puis-je déployer mon cluster DNAC réparti sur ces 2 datacenters ?” Si vous avez compris le mode de fonctionnement du cluster vous devriez avoir la réponse à cette question… Vous avez 3 appliances et 2 datacenters, vous allez donc naturellement mettre 2 appliances sur le DC principal, et une sur le DC secondaire, en espérant pouvoir pallier ainsi une panne de DC. Mais que se passe-t-il si le DC principal tombe ? L’appliance du DC secondaire se retrouve seule dans le cluster et le quorum de 2 membres n’est jamais atteint. Elle ne reprend donc jamais les services : étant seule dans le cluster, elle reste muette puisqu’elle pense naturellement être isolée des 2 autres qui continueraient de fonctionner ! Le mécanisme de split-brain basé sur le quorum fonctionne quand il n’y a aucun point commun entre les appliances qui pourrait, en cas de panne, entraîner la perte de 2 d’entre elles.
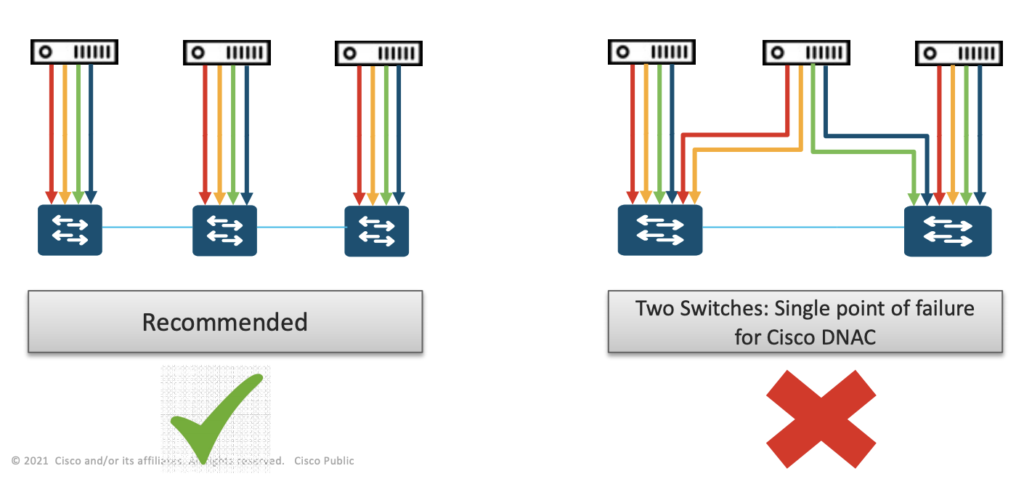
De la même manière, vous éviterez de brancher 2 membres du cluster sur un même commutateur etc. Vous avez compris le principe.
Pour pallier une panne de DC ce n’est pas le mode HA qui va être utilisé, mais la fonctionnalité Disaster Recovery (DR).
DR – Disaster Recovery
Le mode DR (Disaster Recovery) consiste à remonter tous les services d’une appliance, ou d’un cluster d’appliances sur un autre site. La configuration du DNAC principale est régulièrement répliquée sur le DNAC secondaire, en cas de problème on va pouvoir basculer d’un site à l’autre.
La fonctionnalité DR vient donc automatiser un process que certains clients faisaient initialement manuellement : restaurer une configuration fonctionnelle sur un nouveau site, basculer les paramètres réseau et redémarrer les services. Au cœur de cette automatisation, il y a une composante clé : le “witness”. Son rôle est de détecter la perte du cluster principal et de déclencher la bascule. Concrètement il s’agit d’une ova, que vous téléchargerez sur software.cisco.com et que vous allez installer sur un site indépendant de vos datacenters. En effet le witness doit être capable d’opérer en cas de perte d’un datacenter donc il convient de ne pas partager de SPOF avec eux !
La bascule peut soit être déclenchée automatiquement par le witness en cas de panne, ou bien être demandée par l’administrateur sur détection d’un problème quelconque. Le process va prendre un certain temps, mais qu’on se rassure il n’y a pas d’impact sur les services réseau. Un point d’attention sur le design du DR est la portabilité de la VIP entre vos 2 datacenters. Une option élégante entièrement automatisée par le gestionnaire DR est d’annoncer la VIP depuis Cisco DNA Center vers votre réseau via le protocole de routage BGP (EBGP ou IBGP). En cas d’incident sur le premier DC, on déclenche l’annonce de la VIP sur le second et cette dernière est propagée sur votre réseau. Évidemment vous pourrez préférer un autre mécanisme qui nécessitera peut-être des opérations manuelles ou automatisées par vos propres outils…
Il faut donc retenir que le process Disaster Recovery permet d’offrir une redondance complète de DNAC entre deux sites sans contraintes sur l’architecture.
Ou les deux !
HA et DR ne sont pas mutuellement exclusifs ! Il est tout à fait possible de déployer un cluster HA sur un datacenter, redondé par un autre cluster sur un autre datacenter. Il est important de noter que dans ce cas les deux clusters doivent être identiques : impossible de redonder un cluster par une appliance seule, ou même de choisir des appliances de tailles différentes.
Voici donc à quoi peut ressembler un déploiement avec à la fois HA et DR dans la GUI de Cisco DNA Center.
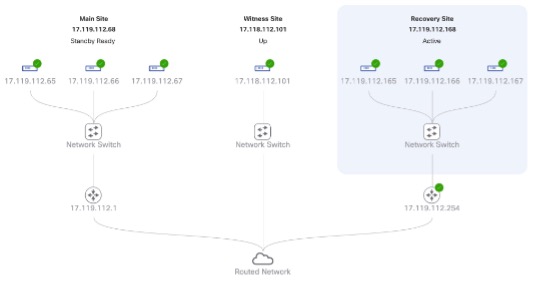
On parle de déploiement 3 + 3 + 1 : 3 appliances dans chaque DC et un witness, par opposition à des déploiements 1 + 1 + 1 (1 appliance dans chaque DC et un witness)
Et les backups alors ?
Si vous qui lisez ce blog depuis longtemps, vous connaissez mon pragmatisme lié probablement à mon passé côté client, au plus près des opérations. Aussi, quand on parle de résilience, il faut aussi penser aux backups. Tous les mécanismes les plus avancés du monde ne doivent jamais vous faire oublier la base : sauvegardez vos configurations ! À tout moment, il vous sera possible de remonter un Cisco DNA Center complet à partir d’un point de sauvegarde donné, aussi ne soyez pas timides : planifiez des upgrades très régulièrement (tous les jours s’il le faut !) l’outil de backup est très simple et permet d’automatiser ces archivages : il vous suffit de monter un disque NFS de taille suffisante depuis la GUI de DNAC et de planifier le rythme de sauvegarde désiré. Allez donc faire un tour sur DNAC aujourd’hui et vérifiez que vos backups sont bien faits correctement.
Je vous encourage à regarder la vidéo suivante sur l’excellente chaîne Youtube dédiée à Cisco DNA Center.
Alors, vous avez choisi ? HA ? DR ? Les deux ? Dites-le en commentaires !
Et pour le SD-WAN ?
Comme indiqué en introduction les principes sont très similaires et pour cause : elles sont conçues par les mêmes équipes qui gèrent les réseaux d’entreprise dans leur globalité. On notera juste qu’il est possible de créer un cluster de plus de 3 vManage pour augmenter encore la scalabilité sur les grands réseaux SD-WAN (on peut compter jusqu’à neuf vManage sur nos plus gros réseaux ! Là aussi, il faut bien avoir le même nombre de vManage sur le site DR). On notera également que vManage peut être virtualisé et ainsi bénéficier de mécanismes de résilience disponibles sur la couche d’hypervision/cloud.
Alors vous avez fait votre choix ? Dites-le en commentaires !
Références
- Vidéo Youtube HA & DR sur Cisco DNA Center
- Implement Disaster Recovery (guide d’administration de Cisco DNA Center)
- Backup and Restore (guide d’administration de Cisco DNA Center)
- DNA Denter High Availability guide
- 1, 2 ou 3 appliances pour Cisco DNA Center (Partenaires Cisco uniquement)

