
J’ai souvent l’occasion de présenter SD-Access et de rappeler que notre solution s’articule sur le triptyque suivant:
- Automatisation avec zero-touch deployment
- Sécurité avec micro-segmentation
- Assurance/Analytics pour rapidement isoler les problèmes et y remédier
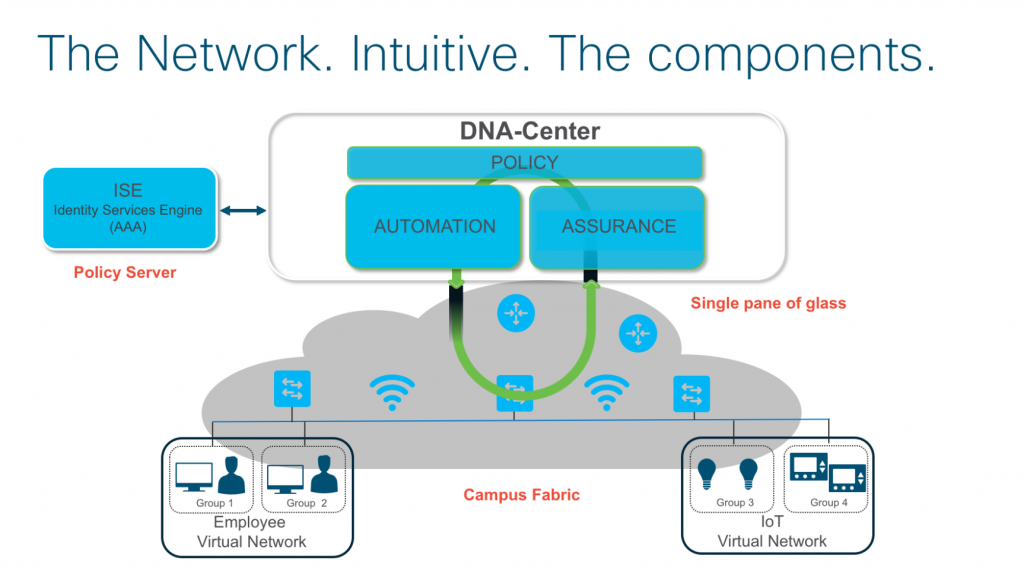
Le tout géré depuis un seul outil: le DNA Center. Parfois je complète avec un brin de malice… “d’ailleurs, par la même occasion on a éradiqué le spanning-tree!” Et c’est bien de cela que je vais vous parler dans cet article: SD-Access n’est pas un cache-misère sur un réseau traditionnel, mais bien la définition de nouveaux fondamentaux pour répondre aux besoins des prochaines décennies…
Oui, on est en 2018 et j’entends parfois que des réseaux s’écroulent en raison de boucles L2, de broadcast storms et autres horreurs dont on ne devrait plus entendre parler. Certes il existe depuis longtemps des mécanismes pour y remédier mais les VLAN sont tellement étirés que leur application est de plus en plus complexe.
Mais pourquoi le niveau 2 s’est-il autant étendu?
C’est là une bien mauvaise réponse à de vrais besoins: la nécessité de mieux segmenter les équipements connectés, et de permettre la mobilité au sein du réseau d’entreprise. Les règles de sécurité étant encore souvent définies selon les adresses IP, regrouper dans un même VLAN les équipements avec les mêmes droits peut à première vue sembler une bonne approche. Un seul préfixe IP par type d’équipement, et une règle suffit à appliquer les mêmes droits pour tout le monde. Mais quand les réseaux deviennent plus gros, on voit ces VLANs s’étendre entre plusieurs étages, plusieurs bâtiments et parfois plusieurs sites. C’est là une drôle de manière d’utiliser les VLANs qui sont sensés pourtant permettre de réduire les domaines de broadcast!
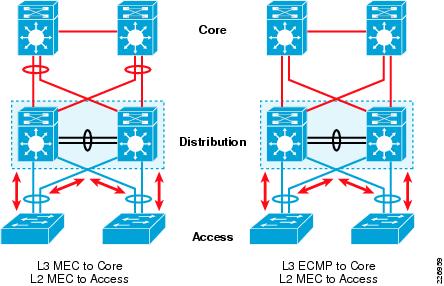
Ce niveau 2 s’est tellement étendu que nous voyons toujours plus de besoins de Stackwise-Virtual ou VSS en tout point du réseau, pas seulement en distribution mais également sur les coeurs. On s’écarte donc un peu des recommandations de notre CVD VSS enabled campus design dans lequel on peut voir un niveau 2 restreint à l’accès/distribution puis un coeur purement L3 avec des équipements indépendants.
Certains avancent que s’écarter de ces bonnes pratiques coûterait un 9 sur vos 99.9…% de disponibilité! Je vous laisserai juger selon votre propre expérience. Mais posez-vous néanmoins les bonnes questions:
- Est-ce que c’est le VLAN ou le subnet qu’il importait de prolonger?
- Pourquoi installer 2 équipements sur les zones les plus critiques (coeur/distribution) s’ils ne sont pas totalement indépendants?
- Avait-on des problématiques de mobilité, d’IOT, de sécurité des réseaux en 1985 quand Spanning-Tree a été créé?
Repartir d’une feuille blanche avec la campus fabric
La campus fabric est fondamentale dans un réseau SD-Access: c’est l’infrastructure sur laquelle on va s’appuyer pour permettre d’implémenter tout type de service indépendamment de la topologie réseau. On va dissocier:
- Un plan de transport (l’underlay) qui va permettre le transport des données de manière simple en garantissant une très haute disponibilité. Dans une fabric SD-Access, l’underlay est un réseau entièrement routé (aucun risque donc de voir une boucle L2 se former sur votre infrastructure)
- Un plan de service (overlay) qui va permettre d’implémenter tout type de policy (sécurité, règles d’accès…) sans se préoccuper de la topologie du réseau. Il vous est ainsi possible de placer 2 utilisateurs dans le même subnet même s’ils sont aux antipodes l’un de l’autre! Nul besoin de prolonger un VLAN, c’est votre fabric qui va assurer l’extension du subnet pour permettre leur connexion.

La campus fabric s’appuie sur les protocoles suivants:
- VXLAN (RFC7348) pour le dataplane (standard de fait permettant le transport d’une trame Ethernet sur un réseau IP). L’ASIC programmable présent sur les commutateurs catalyst 3k/9k a permis d’intégrer le support de VXLAN là où un changement intégral de matériel eut été nécessaire sur un ASIC classique.
- LISP (RFC6830 – RFC6831 – RFC6832 – RFC6833 – RFC6834 – RFC6835 – RFC6836 – RFC7052 – RFC 7215 – RFC7834 – RFC7835 – RFC7954 – RFC7955 – RFC8060 – RFC8061 – RFC8011 – RFC8013 – Bonne lecture!) pour le control-plane qui permet depuis de nombreuses années d’associer des terminaux à une localisation sur le réseau. C’est LISP qui va permettre de faire l’association entre un utilisateur connecté et son switch de raccordement. Ce choix de LISP est détaillé dans ce whitepaper et s’explique notamment par le besoin de scalabilité: LISP ne va chercher une demande de localisation que si vous en avez la nécessité. Inutile de remplir les TCAM de vos équipements avec des infos qui ne servent à rien… A la clé, l’objectif est de faire de plus grosses fabrics et permettre de connecter plus d’équipements. Côté BGP notez quand même que VXLAN/EVPN est supporté depuis la 16.9.x.
Alors on éradique réellement Spanning-Tree ?
Si je vous le dis! Les liaisons entre vos commutateurs sont purement IP (no switchport) ça rend le risque de boucles nul! C’est le protocole LISP qui va permettre d’associer une destination (IP ou MAC) à une localisation sur le réseau (IP du switch de raccordement). Fini les broadcast L2 (ARP, etc.) le premier équipement réseau s’occupe de tout! Concrètement cela signifie que sur une fabric vous n’avez pas à vous poser des questions sur votre topologie réseau quand vous rajoutez des services, les deux sont intégralement dissociés et vous gagnez en confort dans vos opérations du quotidien.
Et mon coeur de réseau gagne en fiabilité ?
Dans une fabric, vous allez pouvoir vous passer des “clusters” (VSS, Stackwise Virtual…) dans vos coeurs et distributions. A priori vous les aviez déployés pour permettre une utilisation optimale de vos liens L2 (convergence Etherchannel, utilisation de tous les liens simultanément…) Avec un réseau 100% routé vous avez les mêmes propriétés grâce à votre protocole de routage; la gestion de l’ECMP – Equal Cost MultiPath – garantissant une répartition des flux sur tous les chemins disponibles.
L’avantage à nouveau est de garder une indépendance complète entre vos équipements de coeur. Adieu donc à ce bon vieux “fate-sharing” qui nous a parfois fait réfléchir avant de réaliser quelques maintenances ardues. Besoin de réaliser une opération majeure sur un de vos équipements de coeur? Vous pourrez utiliser la fonctionnalité GIR – Graceful Insertion and Removal. La simple commande “system mode maintenance” reroutera le trafic sur tous les autres chemins réseau disponibles, vous laissant le champ libre pour ensuite mettre à jour par exemple un IOS. Une fois la maintenance terminée et toutes les vérifications d’usage effectuées, vous pourrez réintégrer aussi simplement votre équipement dans votre topologie logique. Aucune perte de paquets donc et une sérénité maximale pour vos prochaines opérations sur votre coeur de réseau!
Et je configure tout cela à la main ?
Si vous voulez! Mais l’avantage d’une fabric est que l’underlay est homogène (vous n’avez que des liens routés), et que l’overlay l’est tout autant (tout type de service disponible sur chaque équipement!). Automatiser le réseau est plus simple du fait de cet homogénéïté! Nous avons donc bâti la solution d’orchestration qui vous permet de construire cette fabric intégralement depuis une GUI conviviale: le DNA Center. Et pour vous aider dans votre premier déploiement nous avons même rédigé un petit guide de déploiement!
Mais ça vous le saviez déjà 🙂

