
En mi anterior blog os contaba como Cisco Network Assurance ayudaba a los equipos de operaciones a ofrecer la mejor experiencia a las aplicaciones de forma ágil y proactiva.
En esta tercera entrega de la serie de cuatro que he preparado para vosotros os contaré como Cisco Network Insight completa nuestra estrategia para ofrecer un modelo de operación proactivo en el centro de datos. Espero que la disfrutéis. La serie completa tiene 4 capítulos:
1) Transformando el modelo de operación del centro de datos
2) El poder de predecir el comportamiento del Data Center con Network Assurance
3) Cisco Nexus Insight
4) Nexus Dashboard
¿Cómo se complementan NAE y NI?
Ya sabemos que NAE, de forma proactiva y en tiempo real, nos garantiza la coherencia de la configuración aplicada sobre el fabric y, además, nos confirma que el estado de la plataforma de switching es conforme a dicha configuración. Sin embargo, existen otros factores que pueden penalizar la experiencia de la aplicación y que seguro identificarás fácilmente si nos formulamos estas preguntas:
– Si el estado de la configuración es correcto, ¿por qué los tiempos de respuesta de la aplicación han cambiado?
– El servicio A sufre fallos de conexión intermitentes pero, ¿es muy difícil detectar la causa?
– ¿Están los usuarios reportando que la conexión al servicio a veces no funciona?
Describamos brevemente qué es Data Center Nexus Insight
Pensemos en NI como nuestro experto automático capaz de analizar y correlacionar toda la telemetría software (interfaces y protocolos) y hardware (flujos). NI creará un baseline del comportamiento normal del fabric y nos alertará de cualquier desviación que suponga un impacto en el tráfico de datos.
Después, NI analizará -en tiempo real- la información de cada flujo, 5-tupla, latencia, Tenant, vrf, end-point groups, packets drops y detectará cualquier anomalía en el plano de datos.
Para explicaros los fundamentos de NI usaré dos casos de uso comunes y que suelen ser complicados de detectar en el ciclo de vida de la operación de un centro de datos.
Así es como NI trabaja para nosotros en tiempo real:
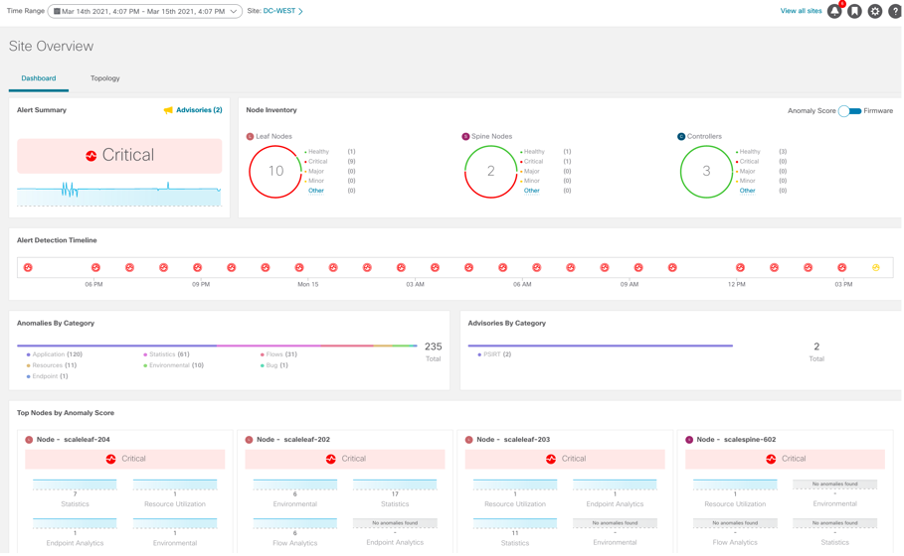
1º Caso de Uso: detección automática de microburst
Los microburst son ráfagas de tráfico que aparecen en un periodo de tiempo muy corto. Estas micro ráfagas pueden impactar el buffer de salida de un interfaz y descartar paquetes. Son muy difíciles de detectar, pero NI lo hará fácilmente por nosotros:
Anomalía Minor relacionada con microburst detectada por NI
NI nos da toda la información y la correlaciona para que sea útil al operador.
1º Impacto: El interfaz eth1/3 del nodo 205 tiene varios de sus buffers impactados.

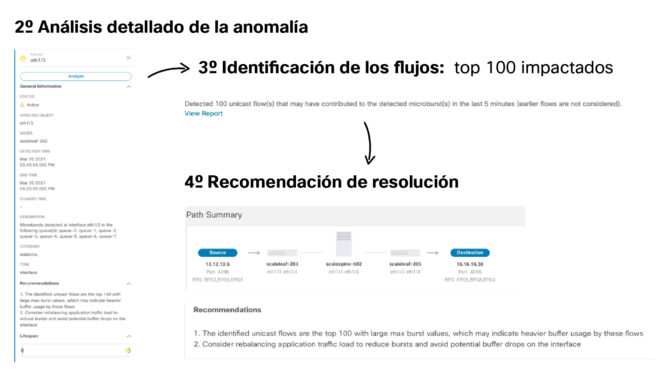
Tú, como operador, con la información de contexto de NI has llegado a la causa del problema y la recomendación de resolución con apenas cuatro clicks de ratón. Has solucionado el problema antes de que el impacto sea mayor.
2º Caso de Uso: se reporta que la aplicación X responde con lentitud
Como operador filtras la información relacionada solo con el flujo de la aplicación X (dirección IP y puerto)
Anomalía Major relacionada con packet drops es señalizada por NI para la App X
1º Impacto: El flujo sufre descartes de paquetes debido a buffers drops

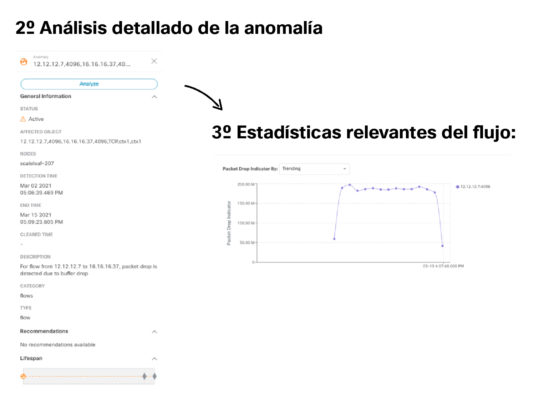
4º Recomendación de resolución: Revisar interfaz eth1/12 y su QoS del nodo 207

Como operador asignado al caso encuentras rápidamente el problema de descartes en los buffers de un interfaz y reconfigurando el esquema de calidad de servicio, lo resuelves.
Con estos ejemplos hemos visto cómo NI proporciona una gran visibilidad sobre el plano de datos, aunque es cierto que NI puede hacer mucho más por nosotros: puede darnos estadísticas de los interfaces, mostrarnos eventos como errores de CRC, FCS, informarnos sobre límites excedidos etc. Asimismo, puede ofrecernos estadísticas y anomalías sobre los protocolos de routing, errores en sesiones de BGP, OSPF, CDP, LACP, Multicast o puertos de acceso, port channels o virtual port channels. Gestión de los recursos hardware, lógicos y de entorno etc.
¿Imaginas poder predecir el comportamiento de tu centro de datos?
Hasta ahora, hemos visto cómo Cisco Network Assurance Engine y Nexus Insight complementan la propuesta de Cisco para ofrecer una operación proactiva en el Data Center Fabric. En el próximo capítulo os mostraré cómo Nexus Dashboard nos ofrece una experiencia única de consumo de las herramientas de día 2, más otras como Multi-Site Orchestator que nos conectará con otros Fabrics y otros dominios como las Cloud Públicas AWS y Azure.
Aprovecho la ocasión para dejaros dos enlaces útiles para que conozcáis más sobre Data Center analytics y Nexus Dashboard. Y, por supuesto, quedo a disposición para cualquier duda o pregunta que necesitéis hacerme. ¡Escribidme vuestro comentario abajo!
Leer más
Un modelo de operación inteligente en el centro de datos con Cisco Nexus Dashboard
El poder de predecir el comportamiento del Data Center con Network Assurance
Infraestructura, cloud, agilidad, automatización, insights… ¡Ponte al día con Cisco!
Cómo controlar y optimizar las cargas de trabajo en vuestro centro de datos