
Cisco Data Center Network Assurance es uno de los pilares del modelo de operación proactivo en el centro de datos que introduje en mi primer blog.
En esta oportunidad, os traigo la segunda entrega de la serie de cuatro que estoy preparando para vosotros, en la que os contaré cuál es nuestra estrategia para ofrecer un modelo de operación proactivo en el centro de datos. Espero que la disfrutéis. La serie completa tendrá 4 capítulos:
1) Transformando el modelo de operación del centro de datos
2) Cisco Network Assurance
3) Cisco Network Insight
4) Nexus Dashboard
Calentando motores
¿Qué respondería el departamento de operaciones donde trabajas actualmente si le hicieras estas preguntas?
– ¿Garantizas que la infraestructura está funcionando correctamente después de los últimos cambios de configuración?
– ¿Puedes confirmar que las reglas de seguridad se están aplicando de acuerdo a la política corporativa?
– ¿Sabes si estos cambios de configuración impactarán en el funcionamiento de las aplicaciones?
Si te ha incomodado la respuesta que has pensado, sigue leyendo. Con Cisco Data Center Network Assurance ésta podría ser tu respuesta inmediata:
¿Garantizarlo?, ¿confirmarlo?, ¿ahora mismo? Pues… sí. Con Cisco Data Center Network Assurance (NAE) puedo garantizar que el comportamiento de la infraestructura es el correcto y esperado en base a la configuración aplicada, y, además, todo en tiempo real.
Cómo funciona Cisco Data Center Network Assurance (NAE)
Para explicaros los fundamentos de NAE usaré dos casos de uso comunes en el ciclo de vida de operación de un centro de datos.
Así es como el dashboard de NAE vigila por nosotros:
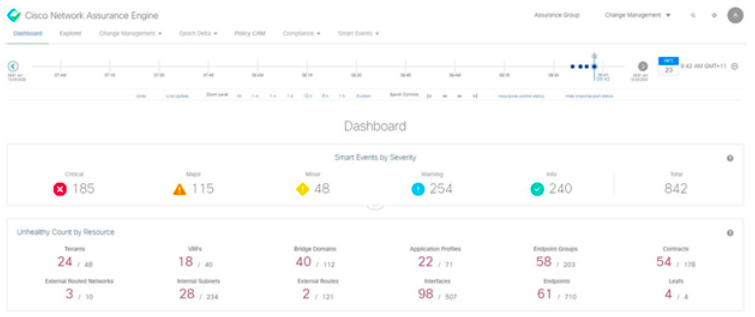
1º Caso de Uso: ¿Ha cambiado algo en mi red?
El dashboard de NAE muestra un nuevo evento de análisis del cambio de severidad major. Realizamos un análisis delta para ver qué nuevas anomalías han aparecido:
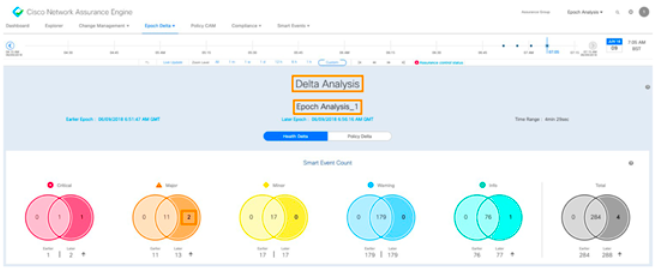
Dos nuevas alarmas de severidad major, resolvamos la primera.
Descripción del evento:

Solicitando más información de contexto podemos ver que el problema puede ser grave, la salida de backup de routing está fallando (L3OUT-BACKUP).
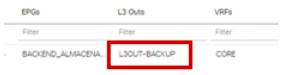
El informe completo que arrojaría NAE contendría:
– Impacto de la anomalía
– Dónde está impactando: Tenant, vlan, VRF
– Descripción del fallo: Router L3Out no exporta las rutas
– Y una sugerencia de resolución
Tú, como operador con la sugerencia de NAE, puedes confirmar que un fallo de configuración afecta al routing de backup y, aplicando la sugerencia de NAE, resolver el problema.
¡Enhorabuena! De forma proactiva NAE ha detectado y resuelto un fallo oculto que hubiese impactado al negocio de forma severa en caso de caída de la línea principal de routing. La alarma se borra y NAE nos ayuda a documentar el reporte del ciclo de resolución.
2º Caso de uso: ¿Mi infraestructura cumple las políticas corporativas?
Este ejemplo sencillo nos ayudará a entender cómo NAE vigila para que se cumplan las políticas de networking y seguridad corporativas.
El funcionamiento de la base de datos A es un servicio crítico y su seguridad es crucial, es decir que cualquier acceso a la BD desde el web-tier, que no se produzca sobre el puerto SQL, es una violación de seguridad. Como administrador, puedes definir en NAE una regla de compliance que chequea continuamente que esta política corporativa se cumpla:
“Web no debe comunicarse con DB excepto en puerto SQL”

Ahora bien. Supongamos que una nueva anomalía de compliance aparece en el dashboard de NAE:
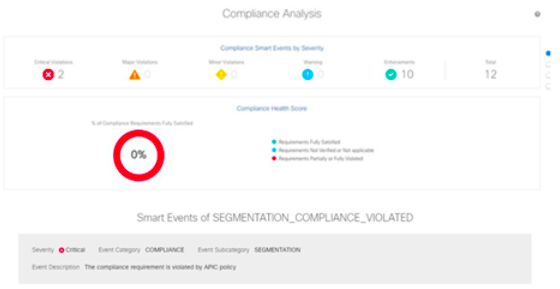
NAE nos da un informe completo del evento: impacto, dónde sucede, descripción de la anomalía y sugerencia de resolución del problema.

Como operador, con toda la información de contexto, determinas que un fallo de configuración permite la comunicación web-tier/DB en el puerto ssh y, aplicando la sugerencia de NAE, resuelves el problema de seguridad.
Así, observamos cómo NAE no se basa en eventos independientes, alarmas, syslog etc. Eventos, que por separado no son útiles, pero correlacionados de forma inteligente nos conducen directamente a la raíz del problema y a su resolución.
Los dos casos de uso solo muestran una pequeña parte del potencial de NAE, pero hay mucho más: ¿Imaginas poder predecir el impacto de una nueva configuración antes de aplicarla?
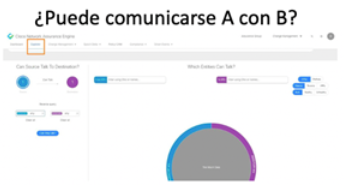 Sería, por ejemplo, poder obtener respuestas inmediatas a estas preguntas:
Sería, por ejemplo, poder obtener respuestas inmediatas a estas preguntas:
– ¿Pueden comunicarse estos dos segmentos? –¿Qué reglas de seguridad les impactan?-
– ¿Hay alguna anomalía de comunicación o seguridad entre estas dos direcciones IP?
– ¿Qué anomalías afectan al switch 1?
¿Imaginas poder predecir el comportamiento de tu centro de datos?
En el siguiente capítulo te mostraré como Network Insight, utilizando telemetría obtenida de los switches Nexus 9000, te proporciona visibilidad completa de todos los flujos que pasan por el fabric, alertando de cualquier anomalía sobre ellos en tiempo real.
Os dejo también dos enlaces útiles para que conozcáis más sobre Data Center analytics y Nexus Dashboard. Y, por supuesto, quedo a disposición para cualquier duda o pregunta que necesitéis hacerme. ¡Escribidme vuestro comentario abajo!
Leer más
Un modelo de operación inteligente en el centro de datos con Cisco Nexus Dashboard
Infraestructura, cloud, agilidad, automatización, insights… ¡Ponte al día con Cisco!
Cómo controlar y optimizar las cargas de trabajo en vuestro centro de datos