
Los retos de operación de un data center son cada vez mayores. Las aplicaciones, que son la base del negocio, crecen y se distribuyen en diferentes nubes públicas y privadas. Para mantener el nivel de servicio que el negocio requiere se necesita un nuevo modelo de operación, ¿pero cuál?
Para asesoraros, me he propuesto escribir esta serie de cuatro blogs en el que os contaré cuál es nuestra estrategia en Cisco para ofrecer un modelo de operación proactivo en el centro de datos. Espero que la disfrutéis. En ella, incluiré:
1) Transformando el modelo de operación del data center
2) Cisco Network Assurance
3) Cisco Network Insight
4) Nexus Dashboard
En este primer blog me gustaría comenzar revisando el día a día de muchos equipos de operación. Seguramente, también sea el vuestro.
¿A qué desafíos se enfrenta un operador de IT?
Para responder a esta pregunta quiero plantearos dos casos de uso habituales en la operación de un data center. A ver si os sentís identificados:
Departamento de operaciones de red del data center, lunes 8 am
Panel de monitorización, logs, alarmas. Todo parece normal. La red funciona correctamente, pero de repente ITSM presenta dos tickets reportando fallos:

- 1º Servidor web. Fallo de conectividad, el departamento de aplicaciones confirma que ellos no presentan fallos.
- 2º Base de datos. Fallo intermitente de conectividad. El departamento de aplicaciones confirma que en la aplicación no ha habido cambios y funciona correctamente.
El departamento de operaciones de red se pone entonces inmediatamente a trabajar para solucionar los problemas. ¿Cómo proceden?
Primero, revisan el servidor web. Es un micro-servicio que, basado en contenedores, puede estar desplegado en tres sites diferentes. También intentan localizar la base de datos, que es una máquina virtual pero, ¿en qué site se aloja?, ¿en qué servidor físico?, ¿en qué switch?, ¿podría ser un tema de buffers?, ¿latencia? Ponen una sonda. ¿Algún cambio de configuración?
Espera, espera… pero… ¿no estamos en la era de la transformación digital? ¿El paradigma del despliegue ágil de aplicaciones basadas en micro-servicios distribuidos en múltiples clouds? El equipo de IT se da cuenta entonces que su modelo de operación sigue siendo reactivo y que siguen usando herramientas aisladas donde la correlación de información útil es inmanejable.
El problema de operar con un modelo reactivo
Con un modelo de operación reactivo los departamentos de IT dedican el 43% del tiempo (prácticamente la mitad) solamente a resolver problemas. Esto trae consecuencias directas:
- Los operadores de red dedican más tiempo a recoger datos que a analizarlos.
- Resolver un problema es casi imposible sino se puede replicar.
- El tiempo de caída es dinero: Fortune 1000, $1.25-2.5B anualmente.
Las herramientas de análisis software de Cisco transforman la operación de red de un modelo reactivo a uno proactivo. Con este nuevo modelo de operación quiero que rebobinemos al lunes por la mañana en nuestro centro de datos imaginario. Mirad cómo funciona:
Departamento de operaciones de red del centro de datos, lunes 8 am
Llegas con tu café, tranquilo porque Network Assurance Engine y Network Insight ya están monitorizando los tres fabrics de ACI desplegados en los entornos IaaS on prem y en los hyperscalers AWS y Azure.
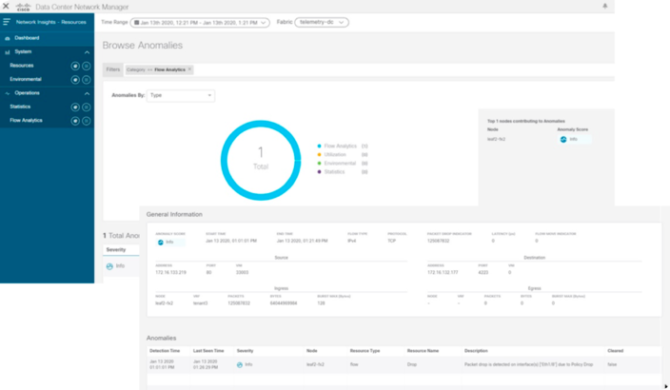
Cuando se produce el primer fallo de conectividad del servidor web el análisis de Network Assurance señaliza automáticamente una nueva anomalía y se abre un ticket del problema:

Con un solo click, Network Assurance te informa en un lenguaje natural, que la conectividad externa del servidor web está impactada y te guía hasta la resolución del problema:
- La conectividad del segmento web server tiene un fallo.
- Se trata de un fallo de configuración, uno de los interfaces requiere de un parámetro.
- La recomendación es clara y el cambio se puede revisar o automatizar.
- El sistema reporta también información del entorno: cuándo se cambió la configuración y qué sistema o persona realizó ese cambio.
Ya cuentas con todos los datos para solucionar el problema, pero el negocio depende de la disponibilidad de este entorno.
¿Afectará la ejecución de los cambios recomendados al servicio? Para saberlo, no tienes más que pedirle a Network Assurance que simule el cambio antes de ejecutarlo en producción y que chequee la conectividad del web server. Network Assurance te responderá inmediatamente a la simulación solicitada:
[Simulación correcta, conectividad chequeada, ejecuta el cambio y triunfarás]
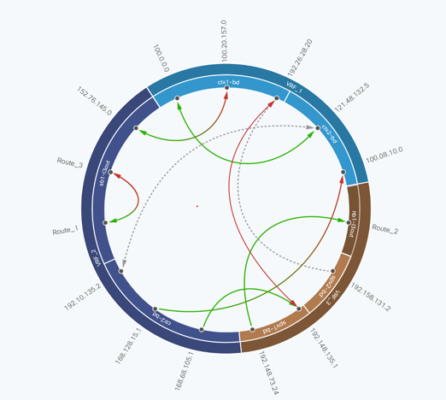
Veamos ahora el comportamiento frente al segundo fallo: el fallo intermitente de conectividad de la base de datos. Network insight muestra una anomalía en el flujo de comunicación entre el servidor web y la base de datos. El análisis detallado muestra que se trata de una anomalía de packet drops.
Detectado el problema, el operador puede interrogar a Network Insight por la localización de los descartes:

El resultado del análisis que arroja la herramienta es el siguiente:
- detección de anomalía packet drops
- localización en el switch 3 interface eth1/49
Un análisis detallado de las colas de calidad de servicio soluciona el problema.
Para facilitar la operación del día 2, Cisco complementa su portfolio de redes basadas en DCNM o ACI con una suite de software que analiza cada pieza del fabric, asegurando: primero, que la configuración aplicada es correcta y, segundo, garantizando los niveles de servicio de cada flujo de datos.
En los próximos artículos profundizaré en las capacidades de Network Assurance y Network Insight y os contaré cómo, con Nexus Dashboard, tendréis un panel completo de operación y provisión de los entornos de ACI Multi-Site y Cloud ACI.
¡Hasta la próxima!
Leer más
Infraestructura, cloud, agilidad, automatización, insights… ¡Ponte al día con Cisco!
Exablaze ahora es Nexus
Cómo controlar y optimizar las cargas de trabajo en vuestro centro de datos
Authors
2 Comentarios
Genial !!!
Me encanta el lenguaje, la cercanía y la claridad. Quiero más como este José ;-) !!!