
Je n’oublierai jamais qu’au secondaire, un enseignant m’avait dit qu’une idée vraiment nouvelle était la chose la plus rare au monde. J’ai pensé à ce concept récemment, lorsque je suis tombé sur le dernier rapport sur les 25 chaînes d’approvisionnement principales de Gartner (Cisco occupe le 7e rang du classement et est le seul fournisseur de centres de données parmi les dix premières chaînes à l’échelle mondiale). En consultant ce rapport, j’ai pensé à quel point le secteur des TI avait évolué tout au long de ma carrière, mais que les concepts de base de la fabrication n’avaient pas beaucoup changé.
Dans le premier rapport sur les 25 chaînes d’approvisionnement principales publié en 2004, mon entreprise figurait au premier rang, en grande partie parce que nous utilisions des étiquettes d’identification par radiofréquence (RFID) dans notre division de fabrication. Nous ne savions pas que c’était le début de l’Internet des objets (IDO). En effet, nous pensions simplement que ces étiquettes étaient une façon pratique de faire le suivi des stocks, de nos installations de fabrication et de distribution aux étagères de nos détaillants, en passant par nos fournisseurs tiers de logistique e; tous les participants de nos filières de mise en marché pouvaient lire ces étiquettes grâce aux normes de l’industrie. Facile. Elles procuraient l’avantage supplémentaire de générer des données homogènes sur les ventes et les stocks, ce qui permettait aux entrepôts de données de l’époque de les manipuler.
Bonne nouvelle, mauvaise nouvelle
Comme son prédécesseur, le code-barres, les étiquettes RFID sont encore beaucoup utilisées par les fabricants. Toutefois, la raison pour laquelle elles demeurent si utilisées, de par leur nature universelle très bien structurée, est également leur point faible. Les données structurées ne représentent qu’environ 20 % des données disponibles. Les autres données, qui correspondent généralement au point central des initiatives IDO, sont non structurées, augmentent rapidement en volume et se retrouvent partout : dans les documents et courriels, les publications des clients sur les réseaux sociaux et dans le secteur de la fabrication, elles souvent créées par des détecteurs, des pompes et des moteurs disparates reliés à des équipements patrimoniaux. Pour compliquer davantage les choses, les données non structurées sont souvent générées loin des limites prévisibles d’un entrepôt ou des étagères d’un magasin, dans des endroits qui rendent l’observation humaine difficile.
La bonne nouvelle, c’est qu’il y a plus de données que nous ne l’aurions jamais imaginé.
La mauvaise nouvelle, c’est qu’il y a plus de données que nous ne l’aurions jamais imaginé.
Comment est-il possible de traiter efficacement toutes ces données et de les transformer en renseignements utiles sans utiliser chaque cycle d’un centre de données?
Hiérarchisation du stockage dynamique
 Une technique utilisée pour segmenter les quantités massives de données et faire en sorte que celles-ci soient plus exploitables en temps réel est la gestion de données « multitempérature », également appelée hiérarchisation du stockage dynamique. Ce concept reconnaît que toutes les données ne sont pas d’égales valeurs et qu’elles ne doivent pas être traitées selon la même importance. C’est particulièrement vrai dans l’ère de l’IDO, où des données peuvent être collectées sur presque tout. Mais si certaines des données ne sont pas essentielles, pourquoi exploiter les ressources pour les acheminer à votre processeur de données massives et augmenter le temps de latence de votre réseau et surcharger vos analyses de points de données superflues? Dans cette technique, les données sont généralement divisées en trois niveaux : chaud, tiède et froid.
Une technique utilisée pour segmenter les quantités massives de données et faire en sorte que celles-ci soient plus exploitables en temps réel est la gestion de données « multitempérature », également appelée hiérarchisation du stockage dynamique. Ce concept reconnaît que toutes les données ne sont pas d’égales valeurs et qu’elles ne doivent pas être traitées selon la même importance. C’est particulièrement vrai dans l’ère de l’IDO, où des données peuvent être collectées sur presque tout. Mais si certaines des données ne sont pas essentielles, pourquoi exploiter les ressources pour les acheminer à votre processeur de données massives et augmenter le temps de latence de votre réseau et surcharger vos analyses de points de données superflues? Dans cette technique, les données sont généralement divisées en trois niveaux : chaud, tiède et froid.
- Les données « chaudes » doivent être consultées plus souvent et, généralement, en temps réel. Par conséquent, elles doivent être traitées sur votre plateforme informatique de stockage la plus rapide, comme la solution All Flash FlexPod de Cisco UCS (avec NetApp) ou la solution All Flash FlashStack de Cisco UCS (avec Pure Storage). Les données chaudes correspondent habituellement à vos informations essentielles les plus récentes : les transactions de point de vente en magasin pendant les Fêtes en sont un bon exemple, tout comme les stocks manufacturiers d’un cycle de production en cours.
- Les données « tièdes » sont consultées moins fréquemment et peuvent être stockées sur des plateformes plus conventionnelles. Il peut s’agir, par exemple, de rapports trimestriels ou de données plus anciennes pouvant être pertinentes, mais qu’il n’est pas nécessaire de consulter en temps réel. Il peut même s’agir d’une copie de sauvegarde de votre environnement de production actuel enregistrée dans un emplacement de récupération des données « tièdes ».
- Les données « froides » sont les moins consultées; elles peuvent même être de l’information considérée comme étant un « bruit de fond » dans le système. Il est possible de les enregistrer hors ligne, voire de les supprimer, dans certains cas, pour économiser de l’argent. Pourtant, les données froides représentent souvent des renseignements que vous devez conserver pendant longtemps à des fins professionnelles ou de conformité réglementaire.
L’informatique en périphérie
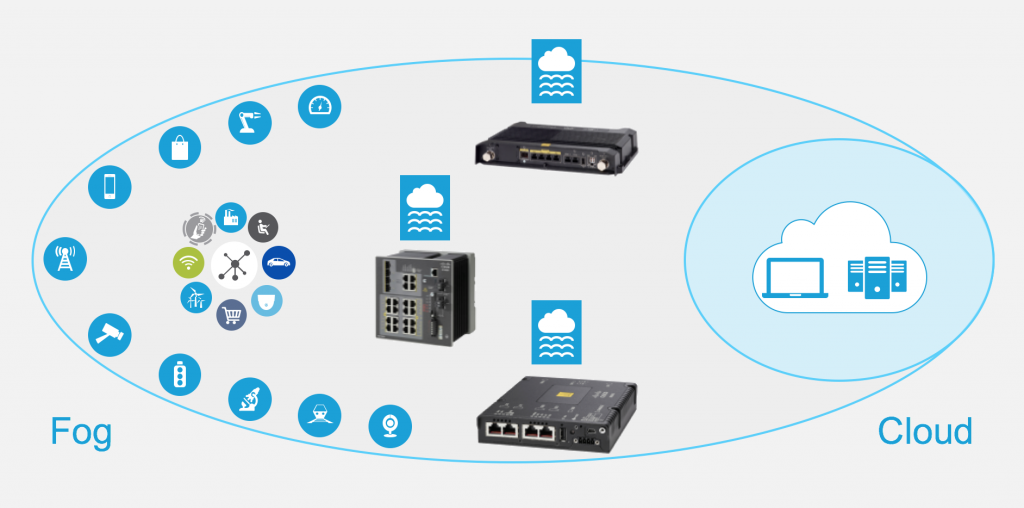 L’informatique en périphérie est une autre technique dont peuvent se servir les fabricants pour maximiser l’efficacité du traitement des données dans un environnement d’IDO. Il s’agit d’une architecture qui repère la capacité de traitement directement à la « périphérie du réseau » afin de générer plus rapidement des observations opérationnelles, généralement près des sites où les données sont collectées et utilisées. Cela peut être un appareil local, un dispositif comme une unité de commande d’automatisation programmable ou, comme dans l’exemple ci-dessous, une caméra intelligente dotée d’une fonction d’envoi de renseignements intégrée. Ainsi, la réactivité est améliorée et les coûts réduits, car il n’est pas nécessaire de renvoyer les données à un site de traitement central.
L’informatique en périphérie est une autre technique dont peuvent se servir les fabricants pour maximiser l’efficacité du traitement des données dans un environnement d’IDO. Il s’agit d’une architecture qui repère la capacité de traitement directement à la « périphérie du réseau » afin de générer plus rapidement des observations opérationnelles, généralement près des sites où les données sont collectées et utilisées. Cela peut être un appareil local, un dispositif comme une unité de commande d’automatisation programmable ou, comme dans l’exemple ci-dessous, une caméra intelligente dotée d’une fonction d’envoi de renseignements intégrée. Ainsi, la réactivité est améliorée et les coûts réduits, car il n’est pas nécessaire de renvoyer les données à un site de traitement central.
Le terme « informatique en périphérie » est parfois utilisé de façon interchangeable avec « informatique en brouillard ». Sans vouloir être pointilleux, le sens de ces termes est légèrement différent. L’informatique en brouillard, que Cisco a d’ailleurs été la première à utiliser, repère les renseignements sur le réseau local et traite les données dans une passerelle d’IDO ou un « nœud en brouillard ». Ceux qui prônent la méthode de traitement en brouillard prétendent qu’elle est plus évolutive et offre une meilleure visibilité sur votre réseau. En revanche, les adeptes de l’informatique en périphérie soutiennent que cette architecture est plus simple parce qu’elle a moins de couches, et présente donc moins de points de défaillance potentiels. Les deux options procurent toutefois l’avantage d’acheminer les renseignements du centre de données centralisés traditionnellement là où l’action se passe.
Le train intelligent
Même moi, je dois reconnaître qu’après un certain temps, toutes ces notions commencent à ressembler à du jargon de fournisseurs. Jetons donc un coup d’œil à un exemple réel de l’un de nos clients, une société ferroviaire nationale en Europe. Nous avons travaillé avec celui-ci sur une solution IDO qui intègre l’informatique en périphérie à son réseau afin d’améliorer l’expérience des passagers et d’accroître la sécurité tout en réduisant simultanément les coûts.
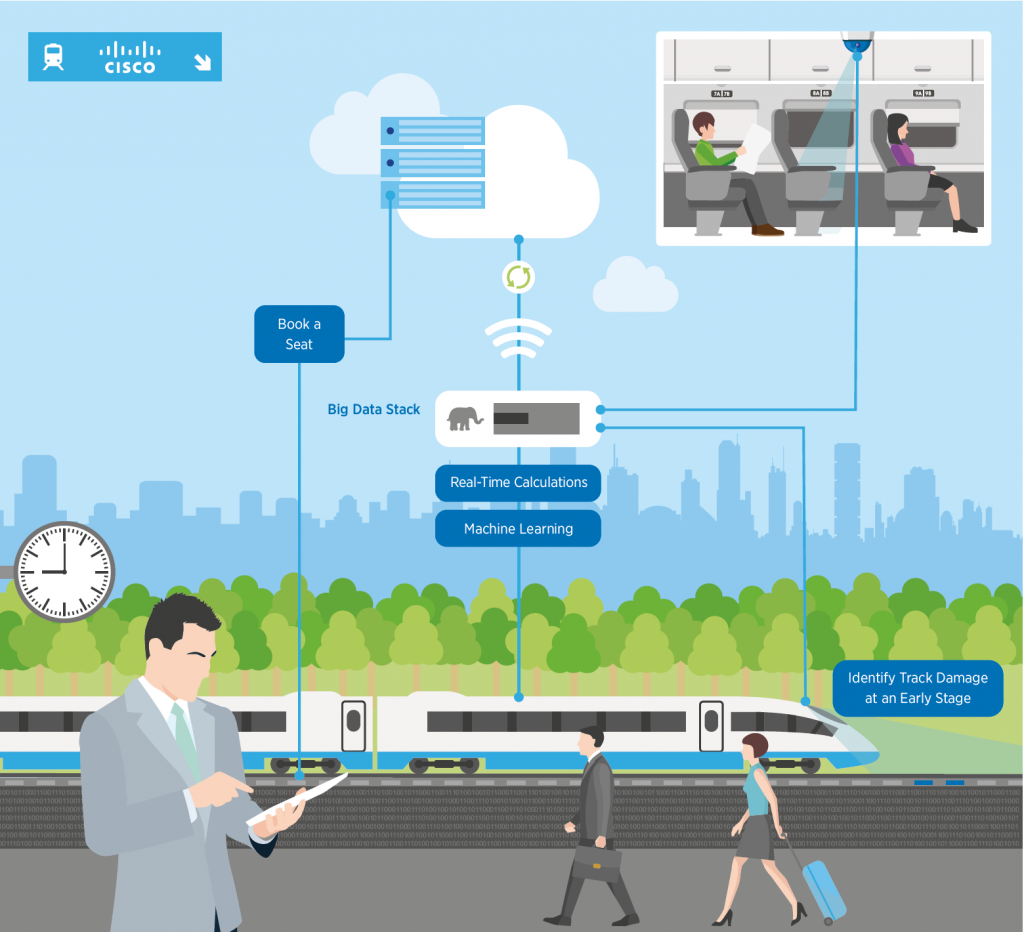 Tout d’abord, l’entreprise a mis en place des caméras intelligentes Cisco Meraki dans les wagons des passagers pour identifier les sièges vides et transmettre cette information aux terminaux de la prochaine station, ce qui a permis aux gens qui attendaient de réserver leur siège sur des kiosques de la plateforme. Les renseignements permettant de distinguer un siège vide d’un siège occupé sont traités dans le dispositif même; il est inutile (et trop long) de les envoyer à un centre de données central. L’information sur les sièges libres de classe Affaires correspond à des données chaudes et permet de vendre ceux-ci sur place moyennant paiement. Une fois que ce siège est occupé, l’information sur sa disponibilité n’a plus de valeur, alors ces données froides sont supprimées. C’est un excellent exemple de migration de données dont l’état passe de « chaud » à « froid » en littéralement quelques secondes.
Tout d’abord, l’entreprise a mis en place des caméras intelligentes Cisco Meraki dans les wagons des passagers pour identifier les sièges vides et transmettre cette information aux terminaux de la prochaine station, ce qui a permis aux gens qui attendaient de réserver leur siège sur des kiosques de la plateforme. Les renseignements permettant de distinguer un siège vide d’un siège occupé sont traités dans le dispositif même; il est inutile (et trop long) de les envoyer à un centre de données central. L’information sur les sièges libres de classe Affaires correspond à des données chaudes et permet de vendre ceux-ci sur place moyennant paiement. Une fois que ce siège est occupé, l’information sur sa disponibilité n’a plus de valeur, alors ces données froides sont supprimées. C’est un excellent exemple de migration de données dont l’état passe de « chaud » à « froid » en littéralement quelques secondes.
Pour renforcer la sécurité, des caméras similaires ont été installées sous les wagons des passagers dans le but de vérifier si les traverses de chemin de fer sont endommagées ou pourries. Bien que ces trains roulent à des vitesses pouvant atteindre 150 mi/h, les caméras Cisco Meraki examinent chaque traverse et évaluent les dommages de celle-ci en temps réel. Les emplacements des traverses abîmées sont identifiés par système GPS et envoyés à l’équipe responsable des réparations. Auparavant, il aurait pu prendre un an pour vérifier chaque traverse de chemin de fer dans le système, sans compter le temps pour les remplacer. Elles sont désormais examinées chaque fois qu’un train passe. Ce processus ne rend pas seulement le système de transport plus sécuritaire; il permet également à l’entreprise d’économiser, selon ce qu’elle a révélé à Cisco, un million $ par année, uniquement sur le carburant que consommaient les anciennes draisines de surveillance.
Cliquez ici pour en savoir plus sur la façon dont les solutions d’analyse de données massives de Cisco peuvent vous aider à économiser ainsi qu’à accroître l’efficacité et la rapidité de votre centre de données de fabrication.
Authors
