
Hyperkonvergenz ist nach wie vor in aller Munde. Was genau ist das Besondere an Hyperkonvergenz? Welche Vorteile haben Unternehmen und was sind die Unterschiede zu traditionellen Systemen?
Von vielen Kunden höre ich immer wieder, wenn ich die Frage stelle: Wieso sie sich für eine hyperkonvergente Lösung entschieden haben, dass es das System der Zukunft ist in das man investieren sollte. Bevor wir uns mit der Architektur beschäftigen, möchte ich kurz vorstellen was Hyperkonvergenz ist.
Was bedeutet Hyperkonvergenz?
Eine hyperkonvergente Infrastruktur ist ein System, das Computing-, Netzwerk-, Storage- und Virtualisierungsressourcen in einer einzigen Appliance über ein zentrales Management vereint. Das Resultat ist eine einfache, verteilte Computing-Plattform, die vollständig integriert und mit dem gesamten Rechenzentrum vereint ist.
Die Architektur
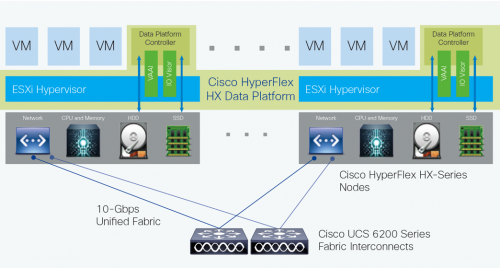
Abbildung 1
Die Cisco HyperFlex-Systeme umfassen als Datenplattform zwei oder mehr Cisco HyperFlex Knoten, um einen hochverfügbaren Cluster zu erstellen. Jeder Knoten enthält einen Cisco HyperFlex HX Data Plattform-Controller, der das verteilte Dateisystem mithilfe interner Flash-basierter SSD oder NVMe-Laufwerke und Festplatten mit hoher Kapazität zum Speichern von Daten implementiert. Die Controller kommunizieren über 10/25/40-Gigabit-Ethernet miteinander, um einen einzelnen Speicherpool bereitzustellen, der sich über die Knoten im Cluster erstreckt (Abbildung 1). Knoten greifen mithilfe von Datei-, Block-, Objekt- und API-Plug-Ins über einen Data Layer auf Daten zu. Wenn Knoten hinzugefügt werden, wird der Cluster linear skaliert, um Rechenleistung, Speicherkapazität und I/O-Leistung bereitzustellen.
HyperFlex DATA_Plattform
In der VMware vSphere-Umgebung belegt der Controller eine virtuelle Maschine mit einer bestimmten Anzahl von Prozessorkernen und Arbeitsspeicher, sodass eine konsistente Leistung erzielt wird und die Leistung der anderen virtuellen Maschinen im Cluster nicht beeinträchtigt wird. Der Controller kann über die VMware VM_DIRECT_PATH-Funktion auf den gesamten Speicher zugreifen, ohne dass der Hypervisor eingreift. Es verwendet den Speicher des Knotens und SSD-Laufwerke als Teil einer verteilten Caching-Layer und die Festplatten des Knotens als Speicher für verteilte Kapazität. Der Controller integriert die Datenplattform mithilfe von zwei vorinstallierten VMware ESXi vSphere-Installationspaketen (VIBs) in die VMware-Software:
- IO Visor: Diese VIB bietet einen NFS-Mount-Punkt (Network File System), mit dem der ESXi-Hypervisor auf die virtuellen Laufwerke zugreifen kann, die an einzelne virtuelle Maschinen angeschlossen sind. Aus Sicht des Hypervisors wird es einfach an ein Netzwerkdateisystem angehängt.
- VMware vStorage-API für Array-Integration (VAAI): Mit dieser Speicher-Offload-API kann vSphere erweiterte Dateisystemvorgänge wie Snapshots und Klonen anfordern. Der Controller bewirkt, dass diese Vorgänge durch Manipulation der Metadaten und nicht durch Kopieren der tatsächlichen Daten ausgeführt werden. Dadurch wird eine schnelle Reaktion und somit eine schnelle Bereitstellung neuer Anwendungsumgebungen ermöglicht.
Wie funktioniert es?
Der Cisco HyperFlex HX-Datenplattform-Controller verarbeitet alle Lese- und Schreibanforderungen für Volumes, auf die der Hypervisor zugreift, und vermittelt so alle I/O Vorgänge von den virtuellen Maschinen. (Der Hypervisor verfügt über eine dedizierten Bootdevice, die von der Datenplattform unabhängig ist.) Die Datenplattform implementiert ein Dateisystem mit Protokollstruktur, das einen Caching-Layer in SSD oder NVMe-Laufwerken verwendet, um Leseanforderungen und Schreibantworten zu beschleunigen, und eine Persistenzschicht, die mit HDDs Data Distribution implementiert wird. Eingehende Daten werden auf alle Knoten im Cluster verteilt, um die Leistung mithilfe des Caching-Layer zu optimieren. Eine effektive Datenverteilung wird durch die Zuordnung eingehender Daten zu Stripe-Einheiten erreicht, die gleichmäßig auf allen Knoten gespeichert sind, wobei die Anzahl der Datenreplikate durch die von Ihnen festgelegten Richtlinien bestimmt wird. Wenn eine Applikation Daten schreibt, werden die Daten basierend auf der Stripe-Einheit, die den relevanten Informationsblock enthält, an den entsprechenden Knoten gesendet. Dieser Datenverteilungsansatz in Kombination mit der Fähigkeit, mehrere Streams gleichzeitig schreiben zu können, vermeidet sowohl Netzwerk- als auch Speicher-Hotspots, bietet unabhängig vom Standort der virtuellen Maschine die gleiche I/O-Leistung und bietet Ihnen mehr Flexibilität bei der Workload-Platzierung.
In diesem Video sehen Sie genauer, wie die verschiedenen Bausteine zusammenarbeiten.
Authors
