
セキュリティ

【Cisco AMP for Endpoints】日本語コネクタ リリース
2017 年 2 月 17 日、Cisco AMP for Endpoints の Windows Connector の最新バージョン(5.1.1)がリリースされました。このバージョンから Connector 側の UI に日本語が利用できるようになりました(OS のロケールが日本語になっている場合)。また、インストール ディレクトリも C:¥Program Files¥Cisco に変更になっています。

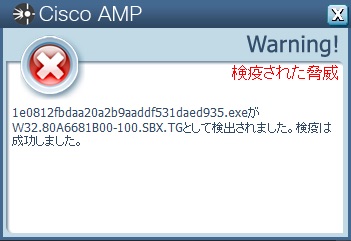
実は、MacOS 版のConnector(1.3.0)は Windows 版より早く日本語対応していました。
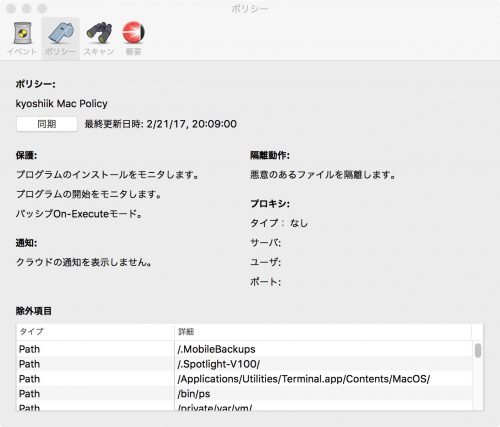
ぜひ、新しいクライアントを利用してみてください。
Tags:
コメントを書く