
Slow drain in Fibre Channel: Better solutions in sight

Wow! It is indeed exciting to write my first cisco.com blog. The extended work from home situation put some extra time on my plate. With many people trying new hobbies, I thought of giving blogging a try and voila!…here I am. While scouting for a suitable topic for my maiden attempt, what could be more interesting than writing about one of the biggest challenges facing Fibre Channel (FC) fabrics today. This is an item that will certainly comeup if you talk to any customer running an FC fabric. Incidentally this is also one of the projects that I have been associated with on the Cisco MDS FC switches recently. In this blog I will attempt to provide a short introduction to FC Slow drain (Congestion) and what is being done to solve it.
FC is a credited and no-drop fabric in the Data Center that interconnects servers to its storage. The no-drop behavior is achieved by a receiving FC port acknowledging back (via R_RDY primitive) to sender FC port for every frame it received and processed. The sender FC port uses this feedback loop to keep track of the number of frame buffers (i.e credits) available at the receiver end and stops sending if there are no credits available. This happens bi-directionally all the time on FC links.
While on the positive side the no-drop characteristic helps deliver a highly reliable, predictable and storage friendly fabric, on the downside one slow draining device connected to the fabric can hold up switch buffer resources, causing a back pressure/congestion and can be detrimental to the performance of the entire fabric. A Mild/Moderate form of slow drain causes high latency and throughput drop while a severe form of it can cause I/O timeouts with application slowness/hang on servers.
There are two variations of slow drain:
- Classical Slowdrain: This happens when an end-device gets busy resulting in slow frame reception and credit return. The connected switch edge port (F-port) becomes a slow drainer first and then gradually spreads to E-ports as the condition persists. A continuously incrementing “TxWait” counter on the switch F-port is the first indication of this condition.
- Oversubscription Slowdrain: This happens due to speed mismatched devices or oversubscribed devices communicating. In this scenario, a device could be draining at its max rate (and returning all credits), but there are still more frames towards it that will be held up in the fabric. The “TxWait” counter on the connected F-port may look quite normal, but impact of this will be felt on the core ports (E-ports) on an adjacent switch which then becomes the slow drainer. A high value of the “TxDataRate” counter on an F-port in conjunction high value of “TxWait” counter on an adjacent switch E-port (destined towards that F-port) is indicative of this condition. As you might have guessed from the description, detecting this condition is hard and may require some kind of manual correlation across port counters. But on the MDS, we did manage to figure out some innovative ways to detect this condition on a given switch via software. It may be noted that oversubscription can happen even when host and target are connected to the same switch, but with slightly different symptoms (Think: How different is this case?)
If you have trouble understanding any of the above, you would need to dip your feet a little more on the slow drain concept. I would recommend an excellent FCIA webinar that covers perspectives from both the FC fabric vendors here
Let us now look at what is the FC community doing to solve this long standing problem.
Traditionally handling congestion in networks relied extensively on QoS techniques like packet markdowns, policing and intelligent early packet drops. These QoS techniques are mostly alien to no-drop FC fabrics because of the nature of evolution of the fabric from a SCSI channel internal to the server. All devices connected to the channel were of equal priority with full access to the channel bandwidth and no possibility of drops/congestion. Hence the nomenclature as a Fibre Channel fabric and not a “network”.
With QoS based solutions ruled out, more of “big hammer” approaches are being used today like: Reset port with stuck credits for consistently large periods (1.5 sec), discard frames on port after a certain hold time with no credits (200ms), classify traffic towards slow devices to isolation virtual lanes, Redesigning fabrics by throwing more bandwidth to keep oversubscription under control etc. All these solutions were mostly treating the symptoms without really curing it by getting to the source of the problem. In some ways the solutions were like treating a viral infection with an antibiotic. Also slow drain was primarily considered to be a problem of the fabric switches to detect and solve and hence all solutions are fabric-centric and vendor specific.
The T11.3 Fibre Channel standards committee decided to acknowledge the problem and look at ways to standardize solutions. To this effect it was decided to:
- Involve the end-devices that source and drain I/O traffic as active participants in building a solution.
- Widen scope of the problem to not only include slow drain condition but also any event that could potentially impact fabric performance.
- Standardize methods to notify fabric performance impacting events among the fabric entities.
The solution proposed involves three parts described below. These are still in the process of review, but should become approved standards pretty soon.
Part-1) Define and Detect fabric performance impacting events:
The standards limit their scope to only defining the various types of events that can impact fabric performance. The events include Congestion, Link Integrity and Delivery failure. The actual detection of these events are expected to be done in a vendor specific manner. The detection can happen either in the fabric or end-devices, though I expect most solutions to rely on fabric for detection and notification. On the MDS we already have elaborate slow drain detection mechanisms via PMON which will be reused for this purpose.
Part-2) Registration and Notification of events:
This is the main focus area of the standards. There are two types of notifications viz. FPIN and Congestion Signals. FPINs are ELS (Extended Link Service) while Signals are primitives. The end devices interested in receiving Signals and FPIN register using EDC (Exchange Diagnostic Capability) and RDF (Register diagnostic function) respectively with the Fabric Controller after login (FLOGI).
FPIN (Fabric Performance Impact Notification):
An ELS that is sent from the FC-2 layer of the detecting switch port (typically from switch control plane software) to registered end devices. The payload is a TLV indicating the event type and more information about it. FPIN has the following characteristics:
- Designed as a best-effort delivery mechanism with no acknowledgement from the receiver (unlike other ELSs)
- Periodically sent at a predetermined frequency as long as a fabric performance condition persists
- A recipient interprets non-reception of two consecutive FPINs as an event condition that no longer exists
- A clear FPIN can indicate immediate clearing of condition to a recipient without having to wait for consecutive FPIN misses
- Delivered to only the zoned devices of an impacted port(device)
There are 4 types of events for which FPIN can be generated:
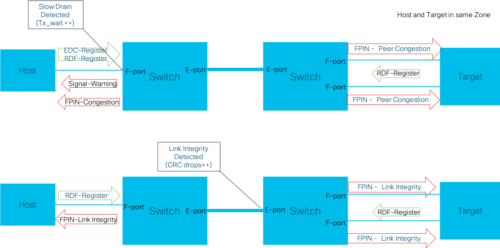
- Congestion: A slow drain condition detected at a fabric F-port will be notified to the connected end device. The information includes a Warning/Alarm severity level.
- Peer Congestion: A slow drain condition at any fabric port will be notified to all devices communicating via that port. The information includes the type of slow drain (CreditStall/ Oversubscription) and list of impacted devices.
- Link Integrity: A condition that puts fabric port integrity in question. The information includes the reason (Link failure, Loss of Signal, Invalid CRC etc) and a threshold value that was breached.
- Delivery disruption: A packet drop condition on a fabric port. The information includes the reason code (Timeout, No route etc) and a dropped packet header used to deduce the flows impacted by the drop.
Congestion Signal:
This is a FC primitive (not a frame) that indicates transmit resources of the sending port has exceeded a threshold. This is typically sent from a FC-1 layer of the detecting port (typically a low level firmware) to registered devices.
Signals are required in addition to FPIN because primitives can be transmitted on a congested port even when there are no credits available (an FPIN frame has to wait when there are no credits). So unlike an FPIN, Signals can be considered as real time indicators of congestion with better delivery guarantee.
The below diagram shows two examples of FPIN and Signal notifications
Two questions might come up for a curious mind:
- Q: Would it make sense to inject more notification packets into an already congested fabric?
A: FPIN is designed in such a way that it usually travels in the direction opposite to that of congestion. Further it is designed as a single frame sequence with no acknowledgement which means there is minimal impact. The frequency of transmission of FPIN is based on how often end devices are comfortable performing congestion mitigation actions. This is expected to be in the several seconds spectrum. - Q: Instead of a new ELS frame from control plane, why not encode congestion information in the data path (I/O) frames itself for real time congestion notification (like ECN bits of IP header in Ethernet networks)?
A: There is very little space in the current FC header to encode all possible fabric performance impacting information. Further, any changes in the header to accommodate this would require switching ASIC changes. This means more delays in solution implementations and no solution for existing fabrics. While FPIN control plane notification is not real time as many would like it to be, the goal really was to make the situation better than we have today. Hopefully in the future the committee will consider a real time congestion notification scheme.
Part-3) Take Action to mitigate congestion:
This is also an area which the standards do not touch upon. In my personal opinion some guidance in this area would have helped to drive uniformity across vendor implementations. But it seems like there is some consensus building up among the vendors with storage and host-OS implementations innovating in this area with actions like:
- Targets ports on receiving a FPIN peer congestion notification will rate limit I/O responses to congested hosts. There might also be some sort of adaptability built into the rate limiting based on the frequency of reception of FPIN from the fabric. A target port may eventually settle for an equilibrium rate per-host.
- Hosts ports on receiving a FPIN Link Integrity notification may tune their multipath algorithms to degrade the paths involving ports with link integrity issues. Early versions of FC Linux drivers are already available on github.
For cases where end-devices or the fabric is running an old software that doesn’t support FPIN/Signals, the existing fabric centric solutions would be the only option. On the MDS we are also planning to implement additional “softer” approaches like dynamic ingress-rate-limiting (DIRL) that is primarily meant for handling oversubscription type slow drain. With DIRL an F-port will try to rate limit the amount of traffic a legacy slow draining device can send by controlling the rate of credit return.
In summary, with FPIN/Signal generation on slow drain detection by the fabric and end devices taking actions based on these notifications, we will have a significantly better performing FC fabric than today. I see several FC ecosystem players comprising HBA, Switch and Storage vendors all galvanized on solving this long standing problem of FC fabrics.
Could this be the proverbial light at the end of the “slow draining” tunnel? Expecting to see solution announcements from various vendors soon!
If you really made it till here, please do write a line or two of feedback. This should help me improve and keep going with my new found hobby :). If you have questions/clarifications, please post it below instead of a unicast, for the benefit of everyone.
Tags:6 Comments



Comment and Response from self:
Friends and colleagues Ed Mazurek and Paresh Gupta sent me a unicast saying that the term “Oversubscription” based slowdrain is misleading. What essentially happens in this type of slow drain is that an end device is asking for more data than it can theoretically handle. This results in the links being “asked” to be overutilized (but impossible to achieve). So an “Overutilization” based slow drain is the correct terminology.
After some googling I could not find an authoritative definition of what Oversubscription really means in this context. It looks like it means subtly different things to different people.
– The most common understanding in a networking context is: “The ratio of downstream bandwidth to upstream bandwidth”. Oversubscriptions are very common practice in any network design and in a FC fabric context, we use the terms host to fabric oversubscription (Eg: 10:1 or 20:1) and storage to fabric oversubscription (Eg: 1:1 or 2:1).
If you put on a networking hat and this is your type of definition, then I tend to agree that using the term Oversubscription slow drain can send a very wrong message. Overutilization based slow drain is a better terminology.
– But there seems to be a dictionary (Merriam Webster) definition of Oversubscription which is: “to subscribe for more than is available”. If you take out your networking hat and this is your type of definition then using an Oversubscription based slow drain also seems appropriate.
So depending on which school of thought you belong to, pick a term that suits you 🙂
Great content Harsha. Thanks for writing this up. Hope to see few more blogs now…
Good Info. Keep going!!
It's a very good read Harsha. Can you also consider explaining how different/ advantageous is this new solution under consideration compared to er_rdy based congestion isolation techniques that we have now?
Good blog harsha. useful summary in few paragraphs
Very informative and insightful post, thank you Harsha!